Retrieval-Augmented Generation (RAG)
A guide to RAG, the foundational AI architecture that grounds Large Language Models in verifiable, private corporate data, eliminating hallucinations and ensuring accurate, context-aware responses.
Giving the AI a Library Card
When a user asks a Large Language Model (like ChatGPT) a question, the model generates an answer based purely on the static weights in its neural network, which were locked in during its initial training months or years ago.
If an employee asks a generic LLM, “What is our company’s current work-from-home policy?”, the LLM will fail. It might hallucinate a plausible-sounding policy, or it will apologize and state it doesn’t have access to private corporate data.
Retrieval-Augmented Generation (RAG) solves this fundamental limitation. RAG is an architectural pattern that bridges the gap between the brilliant reasoning capabilities of an LLM and the private, up-to-the-minute data sitting in an enterprise data lakehouse.
The RAG Pipeline
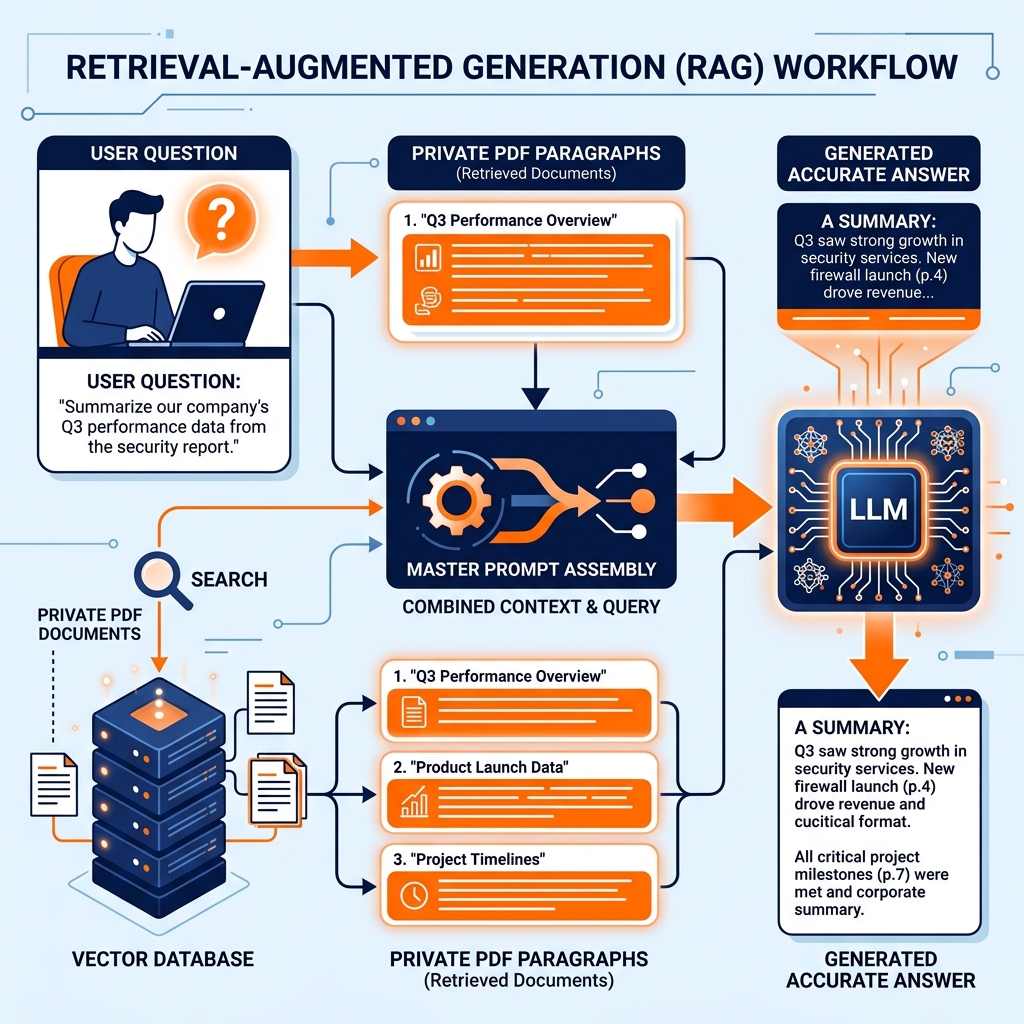
A RAG architecture operates in two distinct phases:
1. The Retrieval Phase: When the employee asks the question, the system does not send it directly to the LLM. First, the system converts the question into a Vector Embedding and performs a Semantic Search against the company’s internal Vector Database. The database searches through millions of private PDFs, HR manuals, and Slack messages, and retrieves the three paragraphs most highly relevant to the question.
2. The Generation Phase: The system then takes the original question AND the three retrieved paragraphs, bundles them together into a massive Prompt, and sends that prompt to the LLM.
The prompt effectively says: “You are an HR Assistant. Please answer the user’s question using ONLY the following retrieved text blocks: [Insert Retrieved Paragraphs Here].”
The LLM then generates the final answer, acting essentially as a summarization and reasoning engine for the retrieved data, rather than trying to answer from its own memory.
Why RAG is Essential for Enterprise
Eliminating Hallucinations: Because the prompt explicitly restricts the LLM to only use the retrieved context, the model is “grounded.” It cannot invent facts; it can only synthesize the truth provided to it. Furthermore, the RAG system can easily provide citations (e.g., “According to the Employee Handbook, page 42…”) proving the origin of the answer.
Data Privacy and Security: Training a custom LLM from scratch on private corporate data costs millions of dollars and creates massive security risks (if a user asks the model for the CEO’s salary, the model might leak it). With RAG, the LLM remains a generic, stateless reasoning engine. The security is enforced during the Retrieval phase. If the employee does not have Row-Level Security permissions to see the CEO’s salary in the vector database, that data is never retrieved, and thus never fed to the LLM.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.