Real-Time Analytics
A guide to real-time analytics, the capability to ingest, process, and query streaming data instantly, allowing businesses to react to events as they happen rather than waiting for overnight batch processing.
The Death of the Daily Batch
For decades, the standard cadence of business intelligence was the “overnight batch.” Data from the day’s operations would sit in operational databases until midnight, at which point an ETL job would slowly pull the data into the data warehouse. When the CEO arrived at 9:00 AM the next day, they looked at a dashboard that was already 9 hours out of date.
For modern, digital-first businesses, yesterday’s data is useless. If a credit card is stolen, the bank cannot wait until midnight to detect the fraudulent transaction. If an Uber driver goes offline, the routing algorithm cannot wait an hour to redirect nearby drivers.
Real-Time Analytics is the architectural capability to ingest, process, and query data literally as the events occur, dropping latency from 24 hours down to sub-second milliseconds.
The Architecture of Real-Time
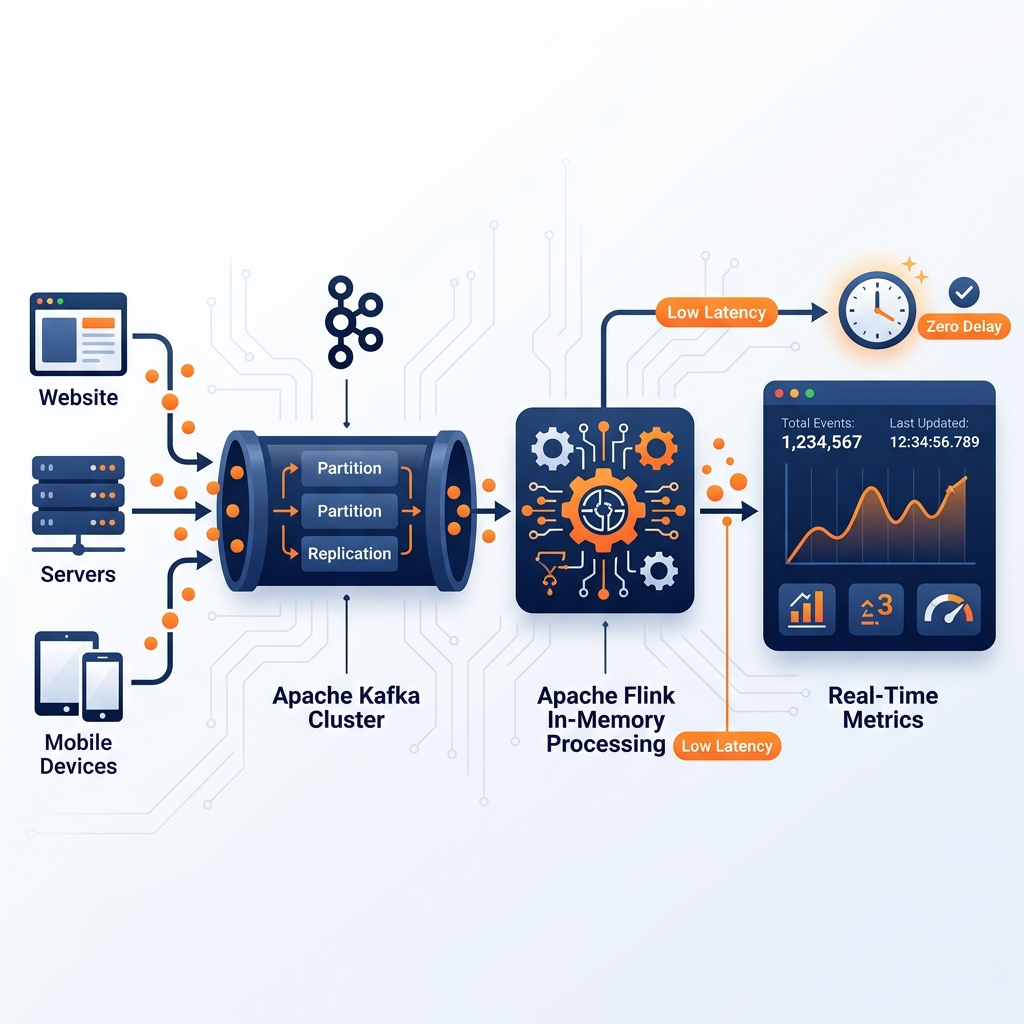
Achieving true real-time analytics requires abandoning traditional database batching and moving to a Streaming Architecture.
1. The Ingestion Stream: Instead of waiting for a database to be queried, source systems push data continuously into a streaming message broker (like Apache Kafka or Redpanda) the exact millisecond the event occurs.
2. The Stream Processing Engine: Traditional SQL engines cannot process data that never stops flowing. Specialized stream processing engines (like Apache Flink or Spark Streaming) connect directly to Kafka. They perform continuous aggregations “on the fly” in memory (e.g., maintaining a live, rolling 5-minute average of web traffic) without ever writing the raw data to a hard drive first.
3. The Real-Time Database: The processed aggregations are pushed to a specialized real-time OLAP database (like Apache Druid or ClickHouse) designed specifically for massive concurrency and sub-second dashboard refreshes.
The Shift to Real-Time Lakehouses
Historically, implementing a real-time streaming pipeline meant building a massively complex, separate infrastructure from the traditional batch data warehouse (the Lambda Architecture).
However, modern Data Lakehouses (utilizing formats like Apache Iceberg) are increasingly capable of supporting real-time ingestion. Tools like Flink can now write streaming data directly into Iceberg tables using frequent micro-commits (every 1 minute), allowing analysts to query near-real-time data using the exact same standard SQL tools (like Dremio) they use for historical batch data, finally unifying the real-time and historical architectures.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.