Lambda Architecture
A deep dive into Lambda Architecture, the dual-stream data processing pattern that separates batch and real-time processing into distinct layers to deliver both comprehensive historical accuracy and low-latency query results.
The Speed vs. Accuracy Dilemma
The history of enterprise data architecture is marked by a persistent, seemingly intractable tension between two competing analytical requirements: the need for complete historical accuracy and the need for real-time query responsiveness. For decades, engineers were forced to choose one at the expense of the other.
Batch processing systems offered completeness and accuracy. A MapReduce job running overnight could process an entire month of transaction history, applying complex deduplication logic, handling late-arriving events, and producing mathematically precise aggregates. However, the latency of these jobs was fundamentally unacceptable for operational use cases. An e-commerce fraud detection system cannot wait eighteen hours for the next batch job to identify a fraudulent transaction that occurred this morning.
Real-time streaming systems offered low latency. An Apache Kafka consumer processing events in milliseconds could flag a suspicious transaction pattern the moment it occurred. However, early streaming frameworks were fundamentally limited. They could not easily handle late-arriving events (where network delays cause a transaction timestamped at 11:59 PM to arrive at the processing system at 12:15 AM, after the midnight boundary has already been computed). They struggled to reprocess historical data when a bug was discovered in the stream processing logic, because the historical events had already been discarded from the ephemeral stream. And they produced approximate, eventually-consistent results rather than mathematically exact aggregates.
In 2011, Nathan Marz, while working at BackType (which was later acquired by Twitter), formalized a framework to resolve this tension definitively. Lambda Architecture provides a practical blueprint for combining batch and real-time processing into a unified system that delivers both the completeness of batch processing and the responsiveness of streaming, without forcing engineering teams to compromise on either dimension. Understanding Lambda Architecture requires understanding the three layers it comprises and why each one exists.
The Batch Layer
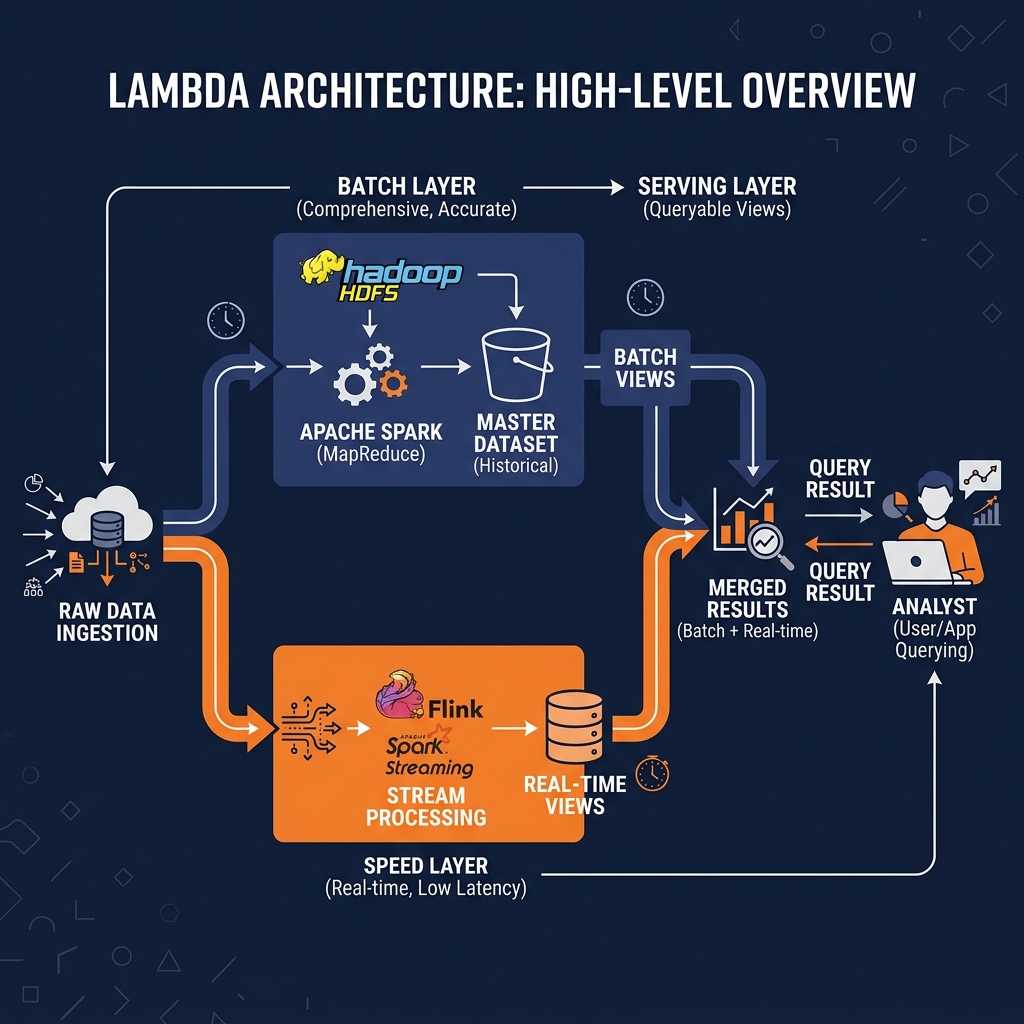
The Batch Layer is the foundation of the Lambda Architecture. Its sole responsibility is to maintain the “master dataset,” a complete, immutable, append-only record of all raw data from the beginning of the system’s history. This master dataset serves as the absolute ground truth; it contains every event, every transaction, and every log entry in its original, unprocessed form.
Processing in the Batch Layer occurs on a scheduled cycle, typically ranging from hourly to nightly, depending on the latency requirements of the specific use case. During each cycle, the batch processing engine (historically Apache Hadoop MapReduce, more recently Apache Spark) reads the entire master dataset from scratch, applies the full computation logic, and overwrites the previous “batch views” with a completely fresh set of precomputed results.
The critical design choice in the Batch Layer is the complete recomputation approach. Rather than incrementally updating previous results, the entire computation is rerun against the complete history on every cycle. This design provides two enormous benefits. First, it guarantees correctness: late-arriving events that were missed by the streaming system are automatically incorporated when the full history is reprocessed. Second, it provides immunity to bugs: if an engineer discovers a logic error in the aggregation formula, they simply fix the code, run the full batch cycle, and the correct results are automatically produced across the entire historical dataset. There are no complex state migration procedures or partial correction jobs required.
The output of the Batch Layer is a set of precomputed “batch views” stored in a database optimized for random read access. These batch views represent the most comprehensive and accurate possible representation of the analytical results, but they are stale by the length of the batch processing cycle.
The Speed Layer
The Speed Layer exists specifically to compensate for the staleness of the Batch Layer. While the Batch Layer may be reprocessing the last twelve hours of data in a long-running Spark job, the business needs analytical views of what is happening right now. The Speed Layer processes only the most recent data that has not yet been incorporated into the latest batch view.
The Speed Layer consumes from a real-time data stream, such as Apache Kafka, and maintains continuously updated “real-time views.” Because it only processes new, incoming events rather than the entire historical dataset, it can produce results with extremely low latency, often measured in seconds or milliseconds. This low-latency processing comes with an important trade-off: the Speed Layer sacrifices completeness for speed. It may use approximate aggregation algorithms, it may not handle late-arriving events perfectly, and its results may be slightly inconsistent in edge cases.
The temporary nature of this imperfection is the fundamental insight of Lambda Architecture. The Speed Layer’s results are considered authoritative only for the period between the current moment and the point in time covered by the most recent batch view. Once the Batch Layer finishes its next reprocessing cycle and publishes fresh, accurate batch views covering that time window, the Speed Layer’s views for that same period are discarded. The ephemeral inaccuracies of the Speed Layer are continuously overwritten by the mathematically accurate results of the Batch Layer.
The Serving Layer
The Serving Layer is the interface between the data processing layers and the end-user. It is a specialized database that stores the outputs of both the Batch Layer and the Speed Layer simultaneously, and provides a unified query interface that merges these two perspectives transparently.
When an analyst issues a query to the Serving Layer (requesting, for example, the total number of active users today), the Serving Layer executes the query against both the batch views (which cover the accurate historical data up to the end of the last batch cycle) and the real-time views (which cover the recent period since the last batch cycle completed). It merges the two results and returns the unified answer. The analyst receives a response that is both historically comprehensive and current, without knowing or caring about the dual-layer architecture operating beneath them.
Early implementations of the Serving Layer used Cassandra or Apache HBase for the batch views and Apache Storm for the Speed Layer views. These choices were dictated by the technology available at the time, each with distinct write and read APIs that made the merging logic in the Serving Layer complex to maintain.
The Complexity Burden and the Rise of Kappa
Lambda Architecture’s elegant conceptual design comes with a severe operational cost: maintaining two completely separate code paths for the same analytical computation. The logic for computing “daily active users” must be implemented twice: once as a batch Spark job in the Batch Layer and once as a streaming Flink or Storm job in the Speed Layer. These two implementations use fundamentally different frameworks, different APIs, and often different programming models.
Keeping these two implementations synchronized is an ongoing maintenance burden. When the business logic changes (the definition of “active user” is updated to require at least three page views rather than one), both implementations must be updated simultaneously and deployed in a coordinated fashion. If the batch implementation is updated but the streaming implementation is not, the Serving Layer will return inconsistent results during the window when the two views overlap. This synchronization burden grows linearly with the number of distinct metrics the system must compute.
Furthermore, debugging a Lambda system is extremely complex. When an analyst reports that a specific metric looks incorrect, the engineering team must determine whether the error originated in the Batch Layer’s Spark job, the Speed Layer’s streaming job, or the Serving Layer’s merge logic. Each of these components is written in a different language with a different operational toolchain.
It was this operational complexity that motivated Jay Kreps (the creator of Apache Kafka) to articulate the Kappa Architecture in 2014, proposing that the Batch Layer could be eliminated entirely by using a replayable log (like Kafka with sufficient retention) as the sole source of truth. By using a streaming framework capable of reprocessing historical events, a single code path could satisfy both the accuracy requirements of the Batch Layer and the latency requirements of the Speed Layer simultaneously.
Lambda in the Modern Lakehouse Context
Despite the intellectual appeal of Kappa, Lambda Architecture has maintained significant real-world relevance, particularly in environments where the batch computation is extraordinarily complex or where the streaming framework cannot fully replicate the mathematical precision of a complete historical recomputation. The modern open Lakehouse has revitalized the Lambda pattern by dramatically simplifying its operational complexity.
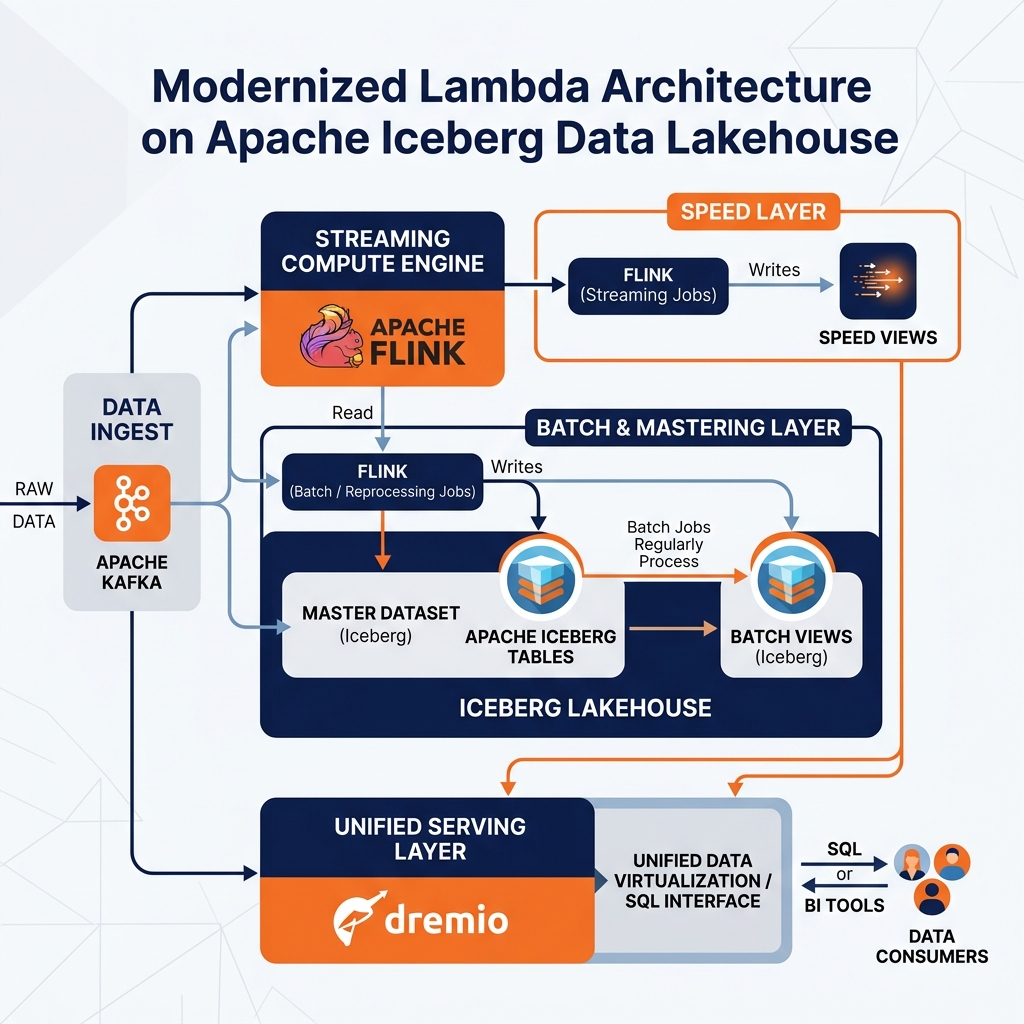
Apache Iceberg serves as the ideal foundation for the Batch Layer’s master dataset. By storing all raw event data as Iceberg tables on cloud object storage, organizations gain an infinitely scalable, ACID-compliant, and Time Travel-capable master dataset. If a batch reprocessing job fails midway through, the Iceberg metadata layer ensures the partially written results remain invisible to downstream consumers. The Batch Layer’s output batch views are also maintained as Iceberg tables, enabling schema evolution and point-in-time auditing without requiring a complete rebuild.
Apache Flink, which supports both streaming and batch processing with a single unified API, substantially alleviates the dual-code-path problem. Engineers can write their analytical logic once using the Flink DataStream API and deploy it in either streaming mode (for the Speed Layer) or batch mode (for the Batch Layer reprocessing run) without rewriting the core computation. This convergence significantly reduces the maintenance burden that historically made Lambda systems prohibitively expensive to operate.
Dremio as the Serving Layer
The most operationally complex component of the classic Lambda Architecture was the Serving Layer, which required sophisticated custom merge logic to join batch views and real-time views into coherent query results. Dremio’s Semantic Layer and federated query capabilities transform this complex custom merge layer into a configuration exercise.
Data engineers can define virtual datasets in Dremio that union the batch view Iceberg tables (containing accurate historical data) with the real-time view tables maintained by the streaming system. The Dremio query optimizer automatically resolves which partition of the query should be answered by the batch tables and which should be satisfied by the recent streaming tables. Data Reflections can be enabled on the batch view portion of the union, ensuring that historical queries return in milliseconds while the streaming portion is resolved in real-time against the latest streaming state.
This approach eliminates the custom database selection and merge code that originally defined the Serving Layer, replacing it with standard SQL and configuration within a single, governed semantic platform. The Lambda Architecture’s conceptual power is preserved while its operational nightmare is largely resolved by the capabilities of the modern open lakehouse stack.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.