dbt (Data Build Tool)
A comprehensive guide to dbt, the SQL-first transformation framework that brings software engineering best practices (version control, testing, documentation, modularity) to the data transformation layer.
SQL Transformation with Engineering Discipline
For most of the history of data warehousing, SQL transformations were maintained as ad-hoc scripts stored in shared drives, email attachments, or undocumented database stored procedures. The “data warehouse” was often a black box where data entered through ETL jobs and emerged as reports, with the intermediate transformation logic documented only in the memory of the engineer who wrote it. Testing was manual or nonexistent. Version control was unknown. Deployment was copy-pasting SQL into a production database console.
dbt (Data Build Tool) was created to apply software engineering discipline to this historically undisciplined layer. dbt provides a structured, version-controlled, tested, documented, and modular framework for writing SQL transformations that compile to production-optimized SQL and execute against the target data platform.
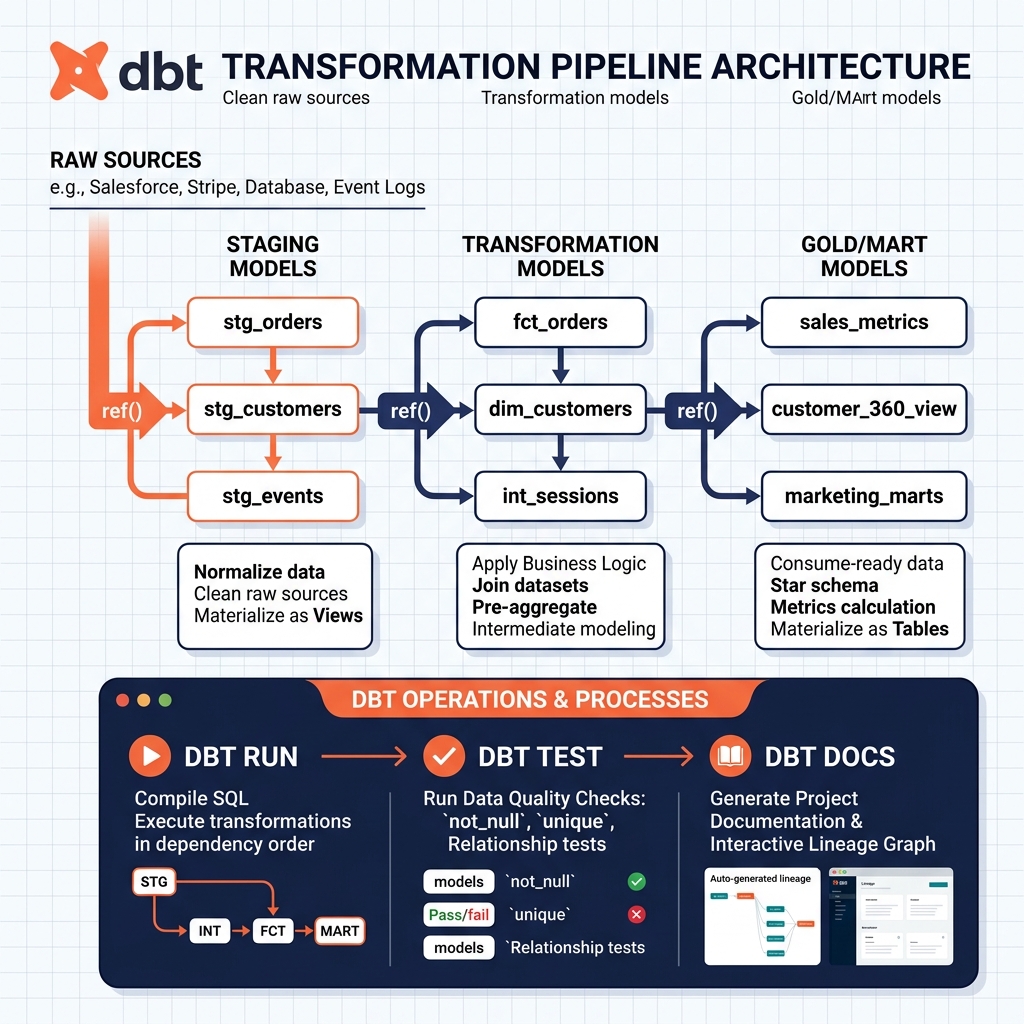
A dbt project is a directory of SQL files (models), YAML configuration files (schema definitions, test declarations), and template macros. When dbt run is executed, dbt reads all model SQL files, determines their dependency order (based on ref() references between models), compiles the SQL (resolving model references and Jinja template macros), and executes the SQL against the target data platform in dependency order. The result is a complete, reproducible set of transformed tables and views built from scratch in the correct order.
Models: The Core Abstraction
A dbt model is a SQL SELECT statement stored in a .sql file. The model defines what the output table or view should contain; dbt handles the DDL (creating or replacing the table) and manages incremental updates. A model can reference other models using the ref() function: SELECT * FROM {{ ref('orders_cleansed') }} tells dbt that the current model depends on the orders_cleansed model and must be built after it.
This reference system allows dbt to construct the full model dependency DAG automatically, enforcing correct build order and enabling impact analysis (which downstream models would be affected if an upstream model changes). The DAG is visualized in dbt’s lineage graph, providing a complete, automatically maintained picture of the transformation pipeline structure.
Models can be configured as views (no data stored, query executed on read), tables (data materialized to a physical table), or incremental models (only new or changed records appended since the last run, enabling efficient incremental pipeline execution without full table rebuilds).
Testing and Documentation
dbt’s testing framework allows data quality rules to be declared in YAML alongside the model definitions. Generic tests (not_null, unique, accepted_values, relationships) are applied with one-line YAML declarations. Custom singular tests can implement any SQL-based validation logic. Tests run automatically after each model build, providing immediate feedback on data quality violations.
dbt’s documentation system generates a searchable HTML portal (dbt Docs) from the model descriptions, column descriptions, and test definitions written in YAML. The documentation portal includes the automatically generated lineage graph showing model dependencies, making the transformation pipeline self-documenting for the entire analytics team.
dbt and Apache Iceberg
dbt supports Apache Iceberg as a first-class materialization target through its Iceberg integrations for Spark (dbt-spark), Trino (dbt-trino), and Athena (dbt-athena). When an Iceberg materialization is configured, dbt generates the appropriate SQL DDL and DML to create and update Iceberg tables rather than traditional database tables.
dbt incremental models with Iceberg support use Iceberg’s MERGE INTO semantics to efficiently upsert only changed records into the target Iceberg table, rather than rebuilding the entire table on every run. This enables efficient, production-ready incremental transformation pipelines with sub-minute latency from source change to updated Gold layer Iceberg table.
Dremio’s Semantic Layer complements dbt’s transformation layer naturally: dbt handles the transformation and materialization of raw data into clean, tested Iceberg tables, and Dremio builds the governed analytical access layer (Virtual Datasets, Row-Level Security, Data Reflections) on top of the dbt-produced Iceberg tables.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.