Apache Avro
A guide to Apache Avro, the row-oriented serialization format with schema evolution support that serves as the standard format for Kafka event streaming and data pipeline message exchange.
Row-Oriented Streaming Serialization
Apache Avro is a data serialization format developed within the Apache Hadoop project that took a fundamentally different design direction from the columnar formats (ORC, Parquet). While ORC and Parquet optimize for analytical read performance by storing data column-by-column, Avro stores data row-by-row in a compact binary format optimized for efficient serialization, deserialization, and schema evolution in event streaming contexts.
Avro’s design reflects the requirements of data pipelines where entire records must be serialized and deserialized rapidly as events flow between systems. In a Kafka event stream, each message contains one complete event record (a customer transaction, a page view, a sensor reading). Serializing this event into Avro format, transmitting it through Kafka, and deserializing it in the consumer is far more efficient in row-oriented Avro than in a columnar format that requires batching many rows before achieving efficient storage representation.
Avro’s Schema and Evolution Model
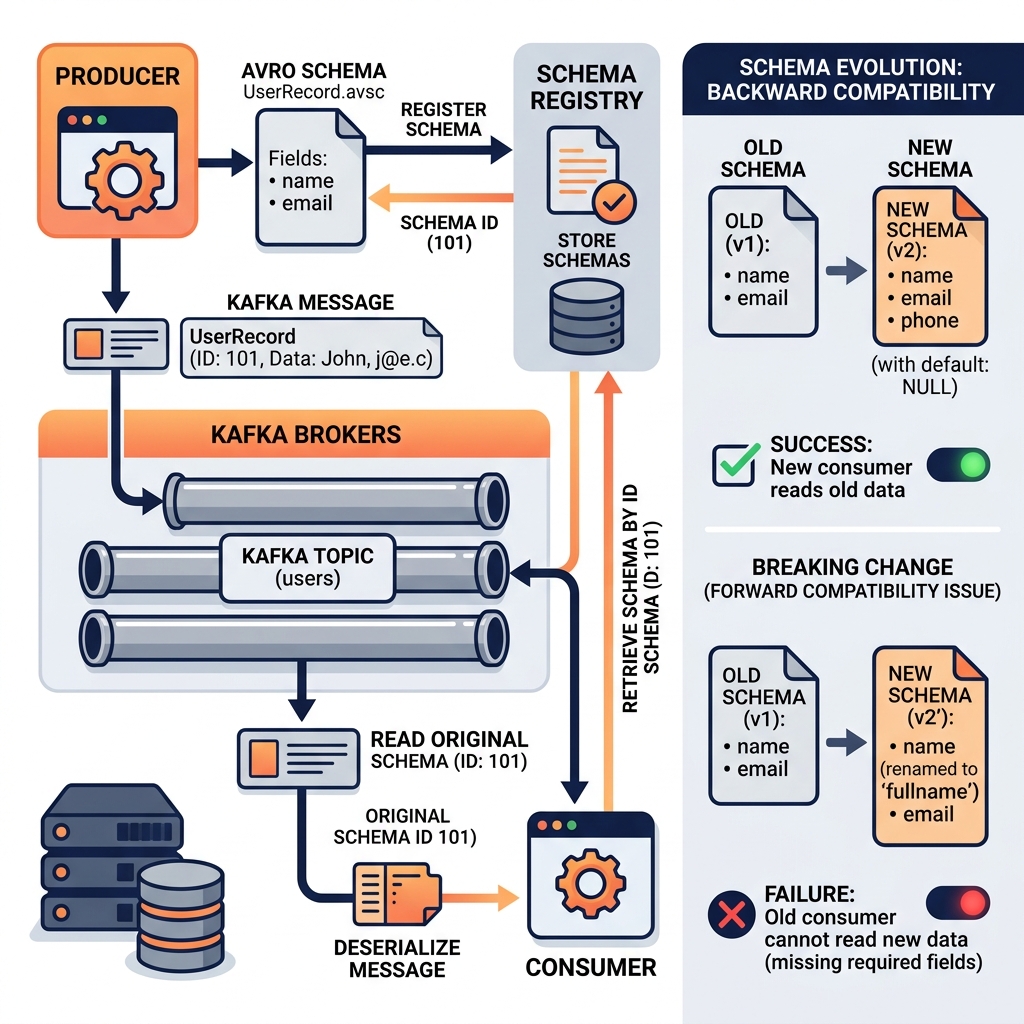
Avro schemas are defined in JSON and describe the structure, field names, types, and default values of the data format. Unlike formats that embed schema in every record (which would waste space in high-throughput streaming), Avro typically separates schema from data: the schema is stored separately (in a Schema Registry) and data records are compact binary encodings that only contain field values without field names.
This schema-data separation requires that both the producer and consumer agree on the schema being used. Avro implements this through its schema evolution model, which defines specific compatibility rules that allow schemas to evolve without breaking producer-consumer compatibility.
Backward compatibility allows new consumers (with a newer schema) to read data written by old producers (with an older schema). Adding a new field with a default value is backward compatible: old records without the field are read successfully, with the field defaulting to its defined value.
Forward compatibility allows old consumers (with an older schema) to read data written by new producers (with a newer schema). Removing a field (when old consumers simply ignore unknown fields) provides forward compatibility.
Full compatibility maintains both backward and forward compatibility simultaneously, allowing schema evolution without any consumer or producer coordination. Only field additions (with defaults) and field removals are fully compatible; changing field types or renaming fields breaks full compatibility.
Confluent Schema Registry
In Kafka-based data pipelines, Avro is typically paired with Confluent Schema Registry, a centralized service that stores and validates Avro schemas for Kafka topics. When a producer writes an Avro-encoded event to Kafka, it first registers the schema with the Schema Registry (which checks compatibility) and receives a schema ID. The schema ID is embedded in each Kafka message. Consumers retrieve the schema from the Schema Registry using the schema ID and use it to deserialize the message.
This centralized schema management provides schema governance for the entire Kafka ecosystem. Schema Registry enforces compatibility rules on every schema registration, preventing incompatible schema changes from being published. It provides a searchable, versionable history of all schemas ever used for each Kafka topic. And it allows consumers and producers to evolve their schemas independently as long as they maintain the configured compatibility level.
Avro in the Iceberg Lakehouse
Within Apache Iceberg’s architecture, Avro appears not as a data file format but as the format for Iceberg’s manifest files. Iceberg manifest files (which list data files and their statistics) are stored as Avro files. This choice reflects Avro’s strengths: manifest files contain records (each record describes one data file), schema evolution matters (Iceberg metadata schema has evolved across specification versions), and compact binary encoding is preferable over verbose JSON for what can be large manifest files.
For streaming pipelines, the typical pattern is to use Avro for Kafka event serialization (leveraging Schema Registry for governance) and Parquet for Iceberg data file storage (leveraging Iceberg’s native metadata layer). Flink or Spark streaming jobs read Avro-encoded Kafka events, decode them using the Schema Registry, apply transformations, and write the results as Parquet files committed to Iceberg tables.
Dremio reads Avro data files directly for compatibility with legacy pipelines that write Avro to the data lake, while recommending Parquet as the primary format for new Iceberg table deployments.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.