Data Serialization
A guide to data serialization, the process of converting complex data structures into byte streams for efficient transmission across networks and storage, comparing formats like JSON, Avro, and Protobuf.
Translating Memory to Wire
When a software application holds a customer record in memory, that data exists as a complex, language-specific object (like a Java Class or a Python Dictionary). However, you cannot send a Java Object directly over a network cable, nor can you save it raw to a hard drive so that a Rust application can read it later.
Data serialization is the process of translating these complex, in-memory data structures into a linear stream of bytes (or formatted text) so they can be transmitted over a network or saved to persistent storage. Deserialization is the reverse process: taking the byte stream and reconstructing the complex object in memory.
In modern data engineering, the choice of serialization format dictates the speed of the streaming pipeline, the storage footprint of the data lake, and the fragility of the overall architecture.
Text-Based vs. Binary Serialization
Serialization formats fall into two broad categories:
Text-Based Formats (JSON, CSV, XML): These formats are human-readable. You can open a JSON file in a text editor and immediately understand the data. Because they are plain text, they are incredibly flexible and heavily used in web APIs. However, they are highly inefficient. A JSON file includes the schema (the column names) repeated in every single record, creating massive storage bloat. They also lack strong data typing (a number in JSON might be a float or an integer).
Binary Formats (Avro, Protobuf, Thrift): These formats are designed for machines, not humans. They compress the data into a dense binary stream. To achieve this, they decouple the data from the schema. In Apache Avro, the schema is defined once (in JSON) at the beginning of the file, and then millions of records follow in pure, dense binary format. Binary serialization is orders of magnitude faster to process and requires significantly less network bandwidth and storage space.
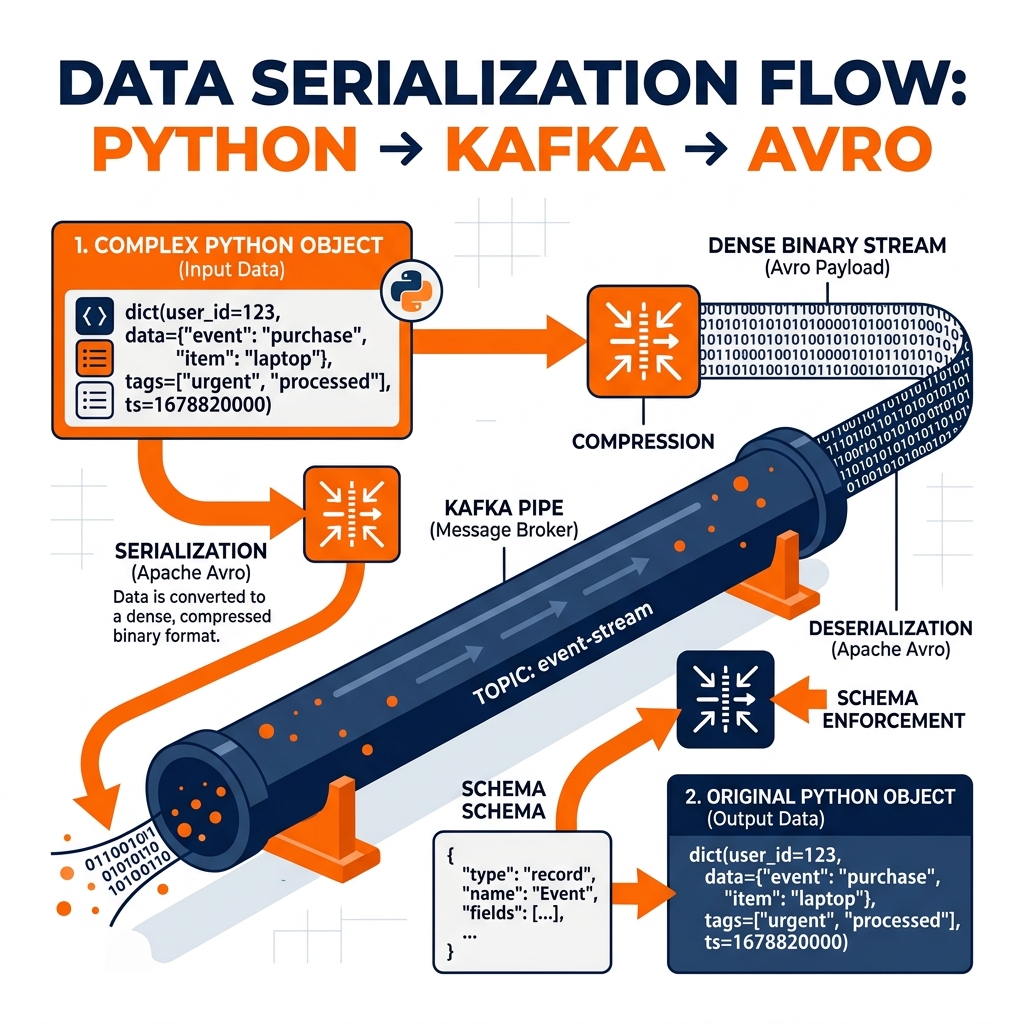
Serialization in Streaming Pipelines
In a high-throughput Apache Kafka pipeline, binary serialization is mandatory. If an e-commerce company produces 100,000 order events per second, serializing those events as raw JSON would saturate the network bandwidth and inflate Kafka storage costs.
Instead, producers serialize the events using Apache Avro or Protocol Buffers (Protobuf). The application takes the Python dictionary, checks it against the Avro schema, compresses it into a tiny binary payload, and sends it to Kafka. The downstream consumer (like Apache Flink) receives the binary payload, looks up the schema, and deserializes it back into memory for processing.
Furthermore, binary serialization formats enforce strict data types. If a producer attempts to serialize a String into a field that the Avro schema defines as an Integer, the serialization process fails immediately. This “schema-on-write” enforcement protects the pipeline from silent data corruption, ensuring that bad data is caught at the source rather than crashing downstream analytical queries.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.