Schema Registry
A guide to the schema registry, the centralized governance component in streaming architectures that enforces data structure contracts and manages schema evolution across decoupled producers and consumers.
Enforcing Contracts in Motion
In a monolithic application, if a developer changes the structure of a database table (e.g., changing an order_id from an Integer to a String), the application code can be updated simultaneously. However, in modern distributed data architectures and event-driven microservices, systems are highly decoupled.
A “Producer” team might write order events into an Apache Kafka topic, while three different “Consumer” teams (Fraud Detection, Inventory, and Analytics) read from that topic. If the Producer team unilaterally changes the structure (the schema) of the JSON payload they are sending, the Consumer applications will break catastrophically when they try to parse a String expecting an Integer.
A Schema Registry (like the Confluent Schema Registry for Kafka) solves this by enforcing a strict “data contract” between producers and consumers. It acts as an independent, centralized repository of data schemas.
How a Schema Registry Works
Instead of sending raw JSON, producers serialize their messages using a binary format like Apache Avro or Protobuf.
1. Registration: Before sending a new type of message, the Producer registers the schema (e.g., OrderSchema v1) with the Schema Registry.
2. Production: The Producer serializes the message payload into Avro. It does not include the bulky schema inside every message; instead, it simply attaches the unique Schema ID.
3. Consumption: The Consumer reads the message, sees Schema ID 42, fetches Schema 42 from the Schema Registry (and caches it locally), and uses it to deserialize the binary payload back into a usable object.
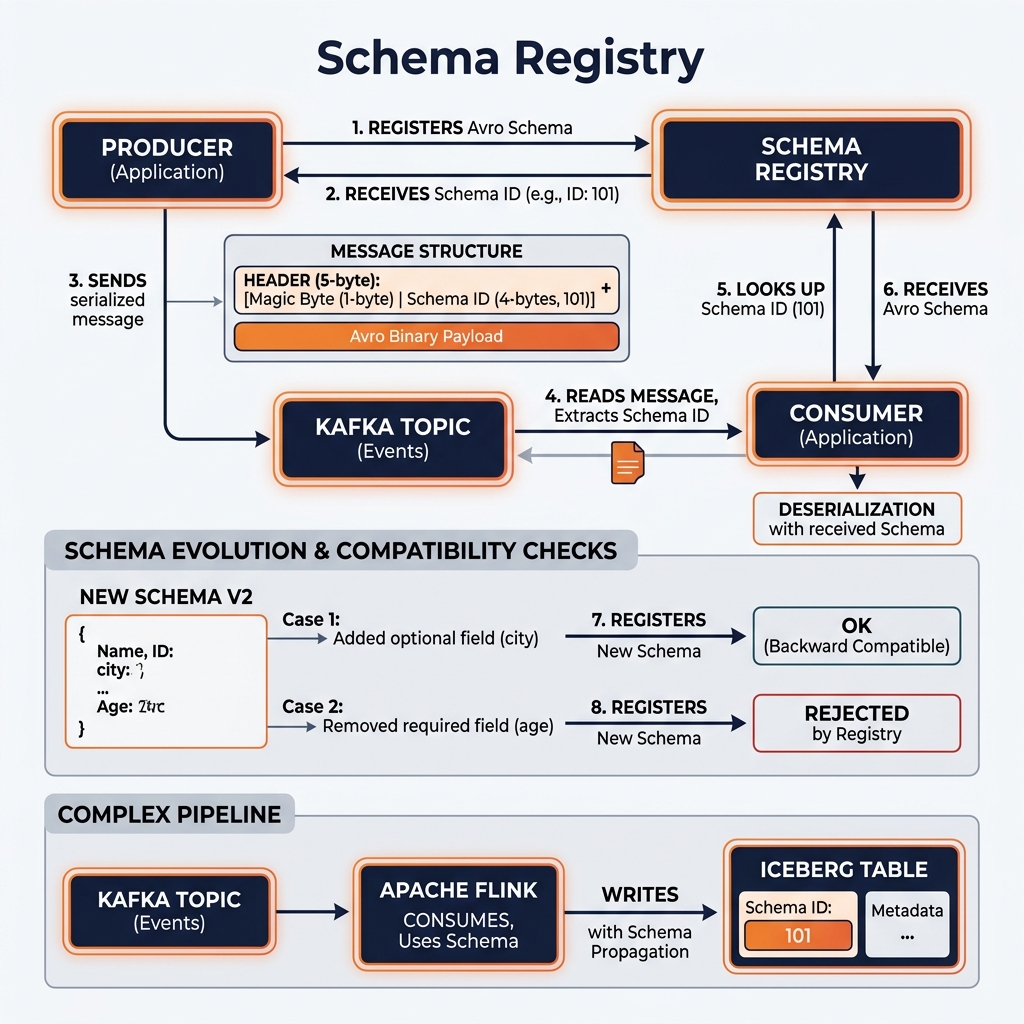
Managing Schema Evolution
The true power of a Schema Registry is managing change over time. Businesses evolve, and schemas must evolve with them (Schema Evolution).
If the Producer team wants to add a new discount_code field to the order event, they attempt to register OrderSchema v2. The Schema Registry acts as a gatekeeper, evaluating the proposed change against strict compatibility rules:
Backward Compatibility: Can a Consumer running old code (expecting v1) still read the new v2 message? (Yes, if the new discount_code field has a default value or is optional, the old consumer can simply ignore it).
Forward Compatibility: Can a Consumer running new code (expecting v2) read an old v1 message that is still sitting in the Kafka topic?
If the new schema breaks the defined compatibility rules (e.g., deleting a required field, or changing an integer to a string), the Schema Registry rejects the registration, and the Producer is physically prevented from publishing the breaking messages to the topic.
By enforcing these data contracts at the architectural level, a Schema Registry prevents “poison pill” messages from corrupting streaming pipelines and ensures the long-term stability of the data lakehouse ingestion layer.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.