Data Contracts
A guide to data contracts, the formal agreements between data producers and consumers that define schema, quality standards, SLAs, and ownership to prevent breaking changes and ensure reliable data pipelines.
The Silent Breaking Change Problem
A data engineer modifies a column name in an upstream table to better reflect its business meaning. They update the documentation, notify their team lead, and deploy the change to production. Three days later, the analytics team discovers that twelve dashboards are showing blank charts, a machine learning model is failing with schema validation errors, and a customer-facing reporting API is returning null values. The engineer’s well-intentioned change broke downstream consumers who were never informed and had no mechanism to enforce their schema expectations.
This scenario plays out daily in data organizations without data contracts. Upstream data producers and downstream data consumers have an implicit, undocumented, unenforceable agreement about the schema, semantics, quality, and freshness of data flowing between them. When either side changes without notifying the other, the implicit agreement breaks silently.
A data contract is the mechanism for making this implicit agreement explicit, documented, versioned, and machine-enforceable. A data contract is a formal specification (typically expressed as YAML or JSON) that defines what a data producer commits to providing and what consumers can depend on: the schema (columns, types, constraints), quality expectations (null rates, uniqueness guarantees, accepted value ranges), SLA commitments (refresh frequency, latency), and ownership (who owns the data product and who are the registered consumers).
The Structure of a Data Contract
A data contract document typically contains several key sections.
Schema definition: The exact column names, data types, nullability constraints, and descriptions for every field in the dataset. This is not just a schema dump from the catalog; it is a formal commitment that these fields will exist at these types for the duration of the contract version.
Quality rules: Machine-testable quality assertions that the producer commits to maintaining: the customer_id column is never null, the order_status column only contains the values ['pending', 'confirmed', 'shipped', 'cancelled'], the order_amount column is always positive.
SLA commitments: The producer’s commitment on data freshness (data updated daily by 6 AM UTC), retention (data retained for 2 years), and availability (table accessible 99.9% of the time).
Ownership and governance: The owning team, the data classification level, applicable regulations (GDPR, HIPAA), and the list of registered consumers who have agreed to the contract terms.
Versioning: A semantic version number for the contract, with explicit compatibility policies (backward-compatible changes require minor version bump, breaking changes require major version bump and consumer migration period).
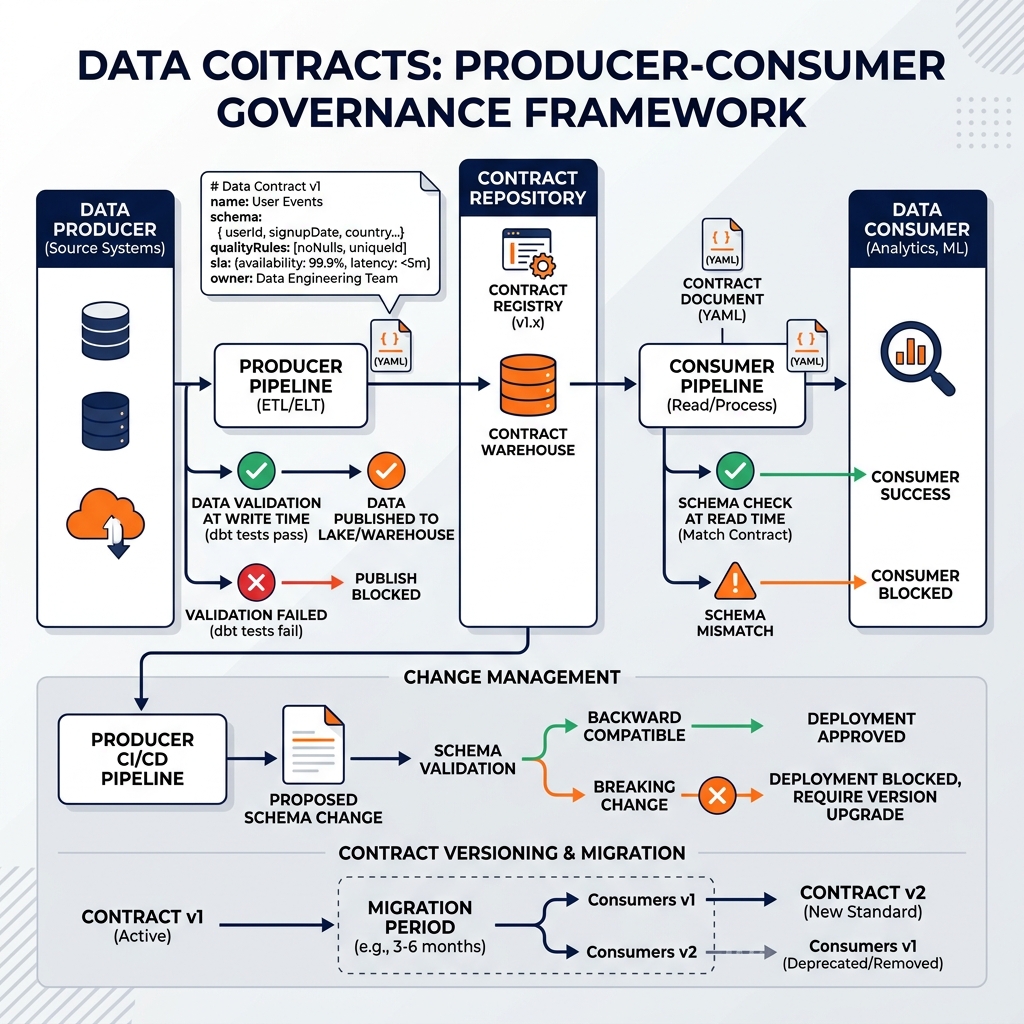
Enforcing Data Contracts
The value of a data contract is in its enforcement, not merely its documentation. Contract enforcement operates at multiple points in the pipeline.
At write time, the data producer’s pipeline validates its output against the contract before committing to the target table. A dbt test suite configured to match the contract’s quality rules runs after every model build, failing the pipeline if any assertion is violated. This producer-side enforcement prevents bad data from reaching consumers.
At read time, consumers validate the data they receive against the contract they agreed to. If the schema has changed in a way that violates the contract’s backward compatibility guarantees, the consumer can raise a contract violation alert and refuse to process the incompatible data.
At deploy time, schema changes to a contracted table are validated against the contract’s compatibility policy before deployment. A CI/CD pipeline check detects that a proposed column rename violates the contract’s backward compatibility commitment and blocks the deployment until either the consumer migration is completed or a new contract major version is negotiated.
Tools like Soda Data, Great Expectations, and dedicated data contract platforms (Bitol, Datacontract.com’s open specification) provide infrastructure for authoring, versioning, and enforcing data contracts. Apache Iceberg’s schema evolution tracking provides the technical substrate for detecting contract violations at the schema level.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.