Data Classification
A guide to data classification, the critical governance process of categorizing data based on its sensitivity, business value, and regulatory risk to apply appropriate security controls and retention policies.
Knowing What You Have
You cannot protect what you do not understand. In a modern data lakehouse containing petabytes of data, applying military-grade encryption and strict access controls to every single file is computationally expensive and paralyzes the business’s ability to perform agile analytics. Conversely, leaving all data completely open exposes the organization to catastrophic regulatory fines and public relations disasters.
Data classification is the foundational governance process of solving this dilemma. It involves scanning, identifying, and tagging data assets based on their level of sensitivity, business value, and compliance risk. By categorizing data into tiers, an organization can apply appropriate, proportionate security controls: locking down the highly sensitive data while freely democratizing the non-sensitive data.
Classification Tiers
Most organizations implement a tiered classification model, typically consisting of three to five levels:
1. Public Data: Data intended for external consumption. Marketing materials, press releases, or open-source datasets. Security control: None regarding confidentiality, though integrity controls (preventing unauthorized modification) are required.
2. Internal (Proprietary) Data: The default tier for most corporate data. Internal sales reports, non-sensitive operational metrics, and organizational charts. Security control: Accessible to all employees via standard authentication (SSO), but not authorized for external sharing.
3. Confidential Data: Sensitive business information that would cause financial or competitive harm if leaked. M&A plans, pre-release financial statements, and proprietary source code. Security control: Restricted to specific departments or project teams using Role-Based Access Control (RBAC).
4. Restricted (Highly Sensitive) Data: Data governed by strict legal or regulatory frameworks (GDPR, HIPAA, PCI-DSS). This includes Personally Identifiable Information (PII) like Social Security Numbers, health records, or credit card numbers. Security control: Strictly limited access, mandatory encryption at rest and in transit, dynamic data masking, and rigorous audit logging of every query.
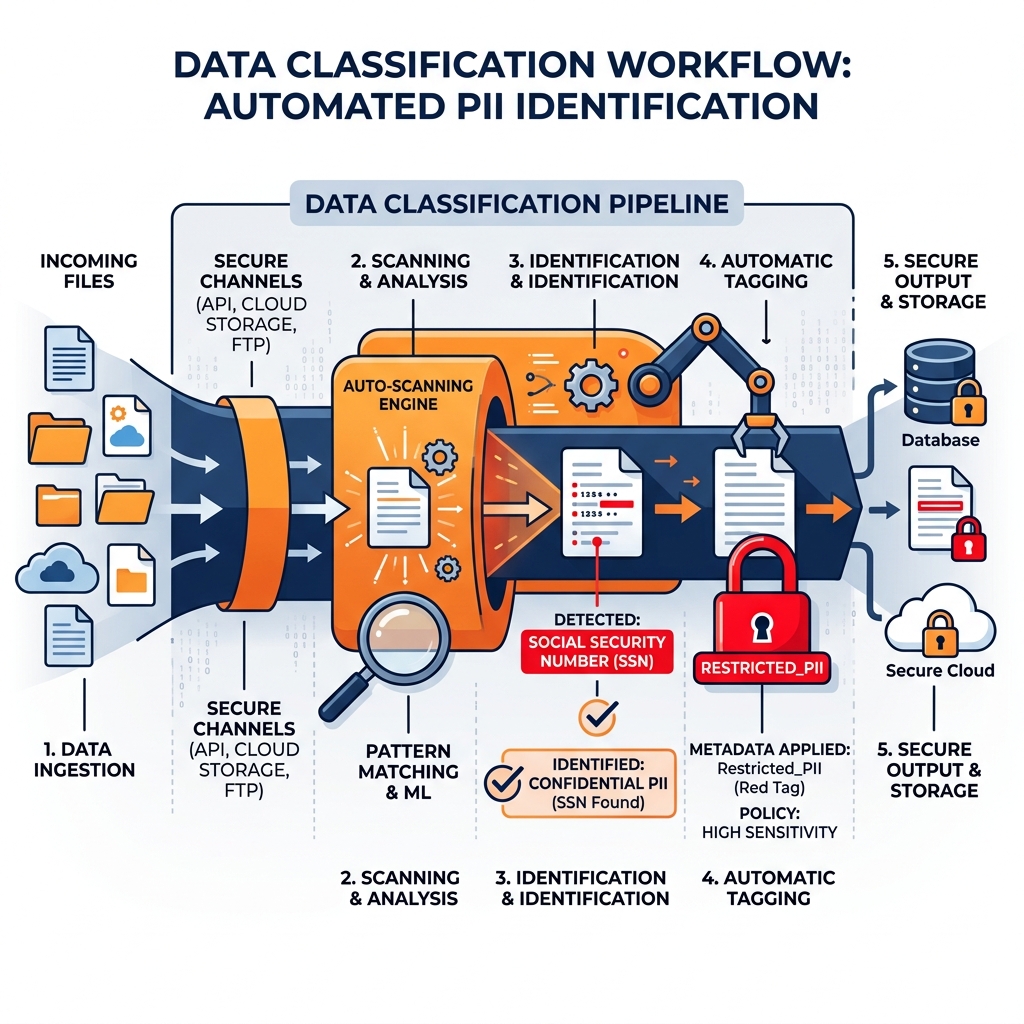
Automating Classification in the Pipeline
Historically, data classification was a manual, administrative task. A data steward would interview business owners and manually tag tables in a catalog. This approach fails to scale in the modern data ecosystem where thousands of new tables are generated automatically by pipelines every day.
Modern data platforms implement automated classification. When raw data lands in the Bronze layer of the lakehouse, an automated scanner profiles the data using regular expressions and machine learning models.
- If a column matches the pattern of a Social Security Number (XXX-XX-XXXX), the scanner automatically tags the column as
Restricted_PII. - If a text field contains medical terminology, it is tagged as
HIPAA_PHI.
These classification tags are attached to the Apache Iceberg table metadata in the catalog (like Apache Polaris).
Once tagged, Active Data Governance policies take over. A policy in the Dremio Semantic Layer might state: “If a column is tagged Restricted_PII, automatically apply a masking function unless the querying user is in the Compliance_Auditors active directory group.” This creates a closed-loop system where data is automatically identified, classified, and protected the moment it enters the architecture, without human intervention.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.