Streaming Lakehouse
A guide to the streaming lakehouse architecture that unifies real-time streaming ingestion with ACID table format semantics, enabling sub-minute data freshness in Iceberg-based analytical platforms.
Unifying Streaming and Batch in the Lakehouse
The traditional data architecture dichotomy between streaming (real-time, low-latency) and batch (high-throughput, high-latency) processing gave rise to Lambda Architecture: running separate streaming and batch pipelines in parallel and merging their results. This approach doubles engineering complexity and introduces the ongoing operational burden of keeping two pipeline systems synchronized.
The streaming lakehouse eliminates this dichotomy. It is an architecture where the lakehouse’s analytical tables are written by streaming ingestion pipelines (Apache Flink, Spark Structured Streaming) at sub-minute or sub-second latency, using Apache Iceberg’s ACID transaction semantics to maintain table consistency despite continuous concurrent writes and reads. The streaming lakehouse provides the low-latency freshness of a streaming system with the structured, queryable, governed format of an analytical table, all without a separate serving layer.
The key technical enabler of the streaming lakehouse is Iceberg’s transactional write model. Each Flink or Spark streaming micro-batch commits a new Iceberg snapshot containing the records produced in that time window. Because Iceberg’s snapshot commits are atomic, readers always see a consistent table state even as new snapshots are being continuously appended. A Dremio query reading the table between two streaming commits reads a complete, consistent snapshot without seeing partially-committed data.
Flink to Iceberg: The Core Pattern
Apache Flink with the Flink Iceberg sink is the most production-proven streaming lakehouse ingestion pattern. A Flink job reads events from Kafka topics, applies streaming transformations (enrichment, filtering, windowed aggregations), and writes records to an Iceberg sink. The Flink Iceberg sink buffers records, writes them to Parquet data files in the configured Iceberg table location, and commits a new snapshot at each checkpoint interval (typically 1-5 minutes).
The Flink Iceberg sink handles Iceberg’s exactly-once semantics through Flink’s checkpointing mechanism. At each Flink checkpoint, the sink atomically commits the buffered data files as a new Iceberg snapshot. If the Flink job fails and restarts from the last checkpoint, the sink will not re-commit data files that were already committed in the previous checkpoint, ensuring exactly-once delivery to the Iceberg table without duplicates.
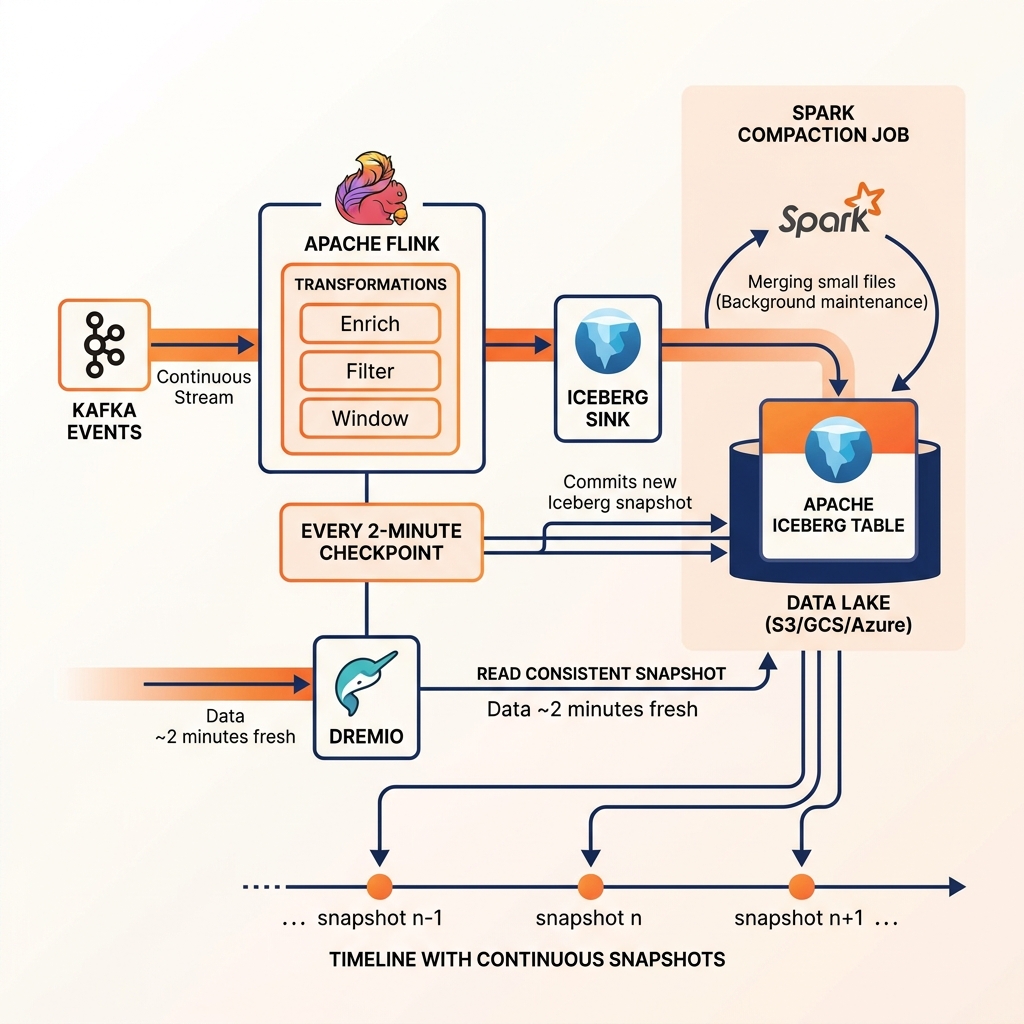
Compaction in Streaming Lakehouses
Streaming ingestion’s frequent small commits produce many small Parquet files, the small file problem described in the compaction article. A Flink job committing every 2 minutes to an Iceberg table produces 720 snapshots per day, each containing a small batch of data files. Over weeks of streaming ingestion, file counts in the millions accumulate without compaction.
Streaming lakehouse architectures must include a background compaction schedule that periodically merges the accumulated small files into optimally sized Parquet files. Spark’s rewrite_data_files procedure, scheduled through Airflow every few hours, is the standard approach. Alternatively, Flink itself can run in a separate maintenance job that continuously compacts files in the background while the main ingestion Flink job continues writing new data.
Dremio supports querying streaming Iceberg tables directly, providing analysts with interactive SQL access to data that is minutes old rather than hours old. Dremio’s Data Reflections can be configured with rapid refresh intervals to provide accelerated query performance even against rapidly evolving streaming lakehouse tables, combining sub-minute data freshness with sub-second query performance for dashboards.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.