Storage-Compute Separation
A guide to the separation of storage and compute, the foundational architectural principle of modern cloud data platforms that allows scaling processing power independently of data volume to minimize costs.
Breaking the Monolith
In traditional, on-premises data warehouse architectures (like Teradata or early Hadoop clusters), storage and compute were tightly coupled. A server node contained a specific amount of CPU power (compute) and a specific amount of hard drive space (storage).
If a company stored 100 Terabytes of data but only ran two simple reports a day, they still had to buy and power a massive cluster of 50 servers just to get enough hard drive space to hold the 100TB. Conversely, if a company had only 1 Terabyte of data but ran thousands of incredibly complex machine learning algorithms against it, they had to buy 50 servers just to get the required CPU power, leaving 99% of the hard drive space empty and wasted.
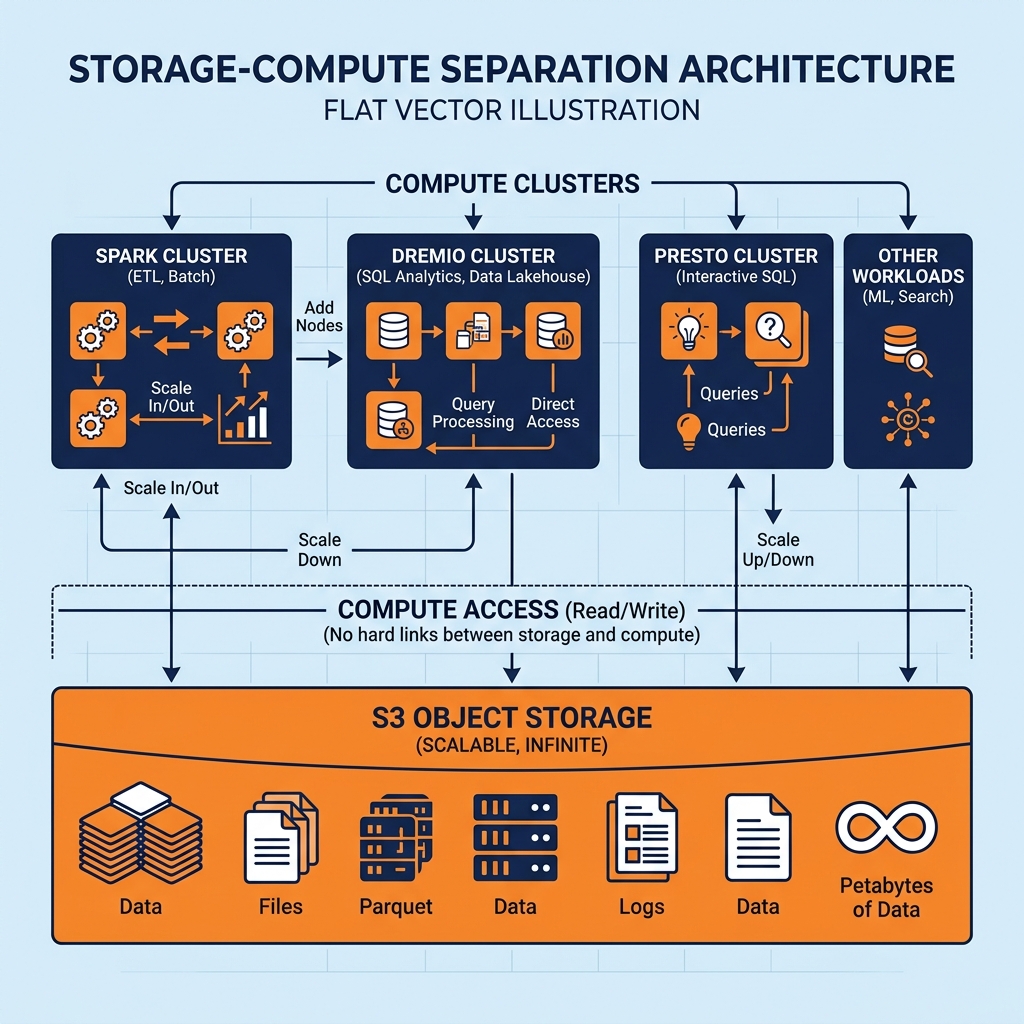
The separation of storage and compute is the architectural paradigm shift that solves this inefficiency. In a modern cloud data platform (like Snowflake or a Dremio-Iceberg lakehouse), the hard drives and the processors are physically and logically divorced.
The Cloud Architecture
The Storage Layer: All data is stored in cheap, infinitely scalable cloud object storage (Amazon S3, Google Cloud Storage, Azure Data Lake). You can store 10 Petabytes of data for a fraction of the cost of traditional storage. Object storage has no processing power; it simply holds the files (usually Apache Parquet).
The Compute Layer: The processing engines (Dremio, Spark, Trino) exist as separate, ephemeral clusters of CPU and RAM. When a user runs a query, the compute cluster spins up, reaches across the cloud network to pull the exact Parquet files it needs from S3, processes the data in memory, returns the result, and then immediately shuts down.
Benefits of Separation
Independent Scaling: You scale storage exactly to the gigabyte you need, paying only for S3. You scale compute exactly to the CPU cycle you need, paying only while the query is running. You never over-provision one to satisfy the other.
Workload Isolation (Multi-Tenancy): Because compute is separate from the central storage bucket, you can spin up multiple isolated compute clusters pointing at the exact same data. You can have a massive 100-node compute cluster for the Data Science team training ML models, and a smaller 10-node compute cluster for the HR team pulling daily reports. The Data Science team can max out their CPU without ever slowing down the HR team, eliminating the “noisy neighbor” problem that plagued traditional data warehouses.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.