Reverse ETL
A guide to Reverse ETL, the data pipeline pattern that syncs curated analytical data from the data warehouse or lakehouse back into operational business tools like CRMs, marketing platforms, and customer success systems.
Closing the Loop Between Analytics and Action
Traditional ETL pipelines flow in one direction: source systems (operational databases, SaaS applications) push data into the data warehouse or lakehouse for analysis. Analysts and business users consume the resulting dashboards and reports, then manually act on the insights by updating records in their operational tools. A data analyst discovers that a customer segment has high churn risk from an Iceberg-based churn model and exports a CSV, which a sales operations manager manually imports into Salesforce to update account risk scores.
This manual loop between analytics and action is slow, error-prone, and unscalable. The churn model updates daily; Salesforce needs to reflect the latest predictions to be operationally useful. Manually exporting and importing once a week means sales reps make decisions on week-old predictions. The export-import process itself introduces data quality risks from formatting issues and import errors.
Reverse ETL inverts the pipeline direction: instead of data flowing from operational tools into the lakehouse, curated analytical data flows from the lakehouse back into operational tools. A Reverse ETL pipeline reads the churn model’s output from an Iceberg Gold layer table and automatically syncs the churn_risk_score and next_best_action columns into the corresponding Salesforce account records via the Salesforce API. Sales reps see current churn predictions directly in Salesforce, updated nightly as the model runs, without any manual intervention.
What Reverse ETL Enables
Reverse ETL enables operational analytics: the practice of embedding analytical insights directly into the operational workflow tools where business teams spend their time, making analytics actionable without requiring users to leave their operational context.
Sales intelligence: Account health scores, propensity-to-buy models, and product usage signals synced from the lakehouse into CRM accounts, enabling sales reps to prioritize outreach based on data-driven scores rather than gut feel.
Marketing personalization: Customer segments and next-best-offer predictions synced from the lakehouse into marketing platforms (HubSpot, Braze, Iterable), enabling personalized email campaigns based on behavioral analytics computed in the lakehouse rather than limited platform-native segmentation.
Customer success alerting: Product usage metrics and health scores synced from the lakehouse into customer success platforms, triggering automated at-risk account workflows when the health score drops below a threshold.
Finance operations: Reconciled financial aggregates synced from the lakehouse into ERP systems, eliminating manual data entry and maintaining consistency between the analytical system of record and the operational system.
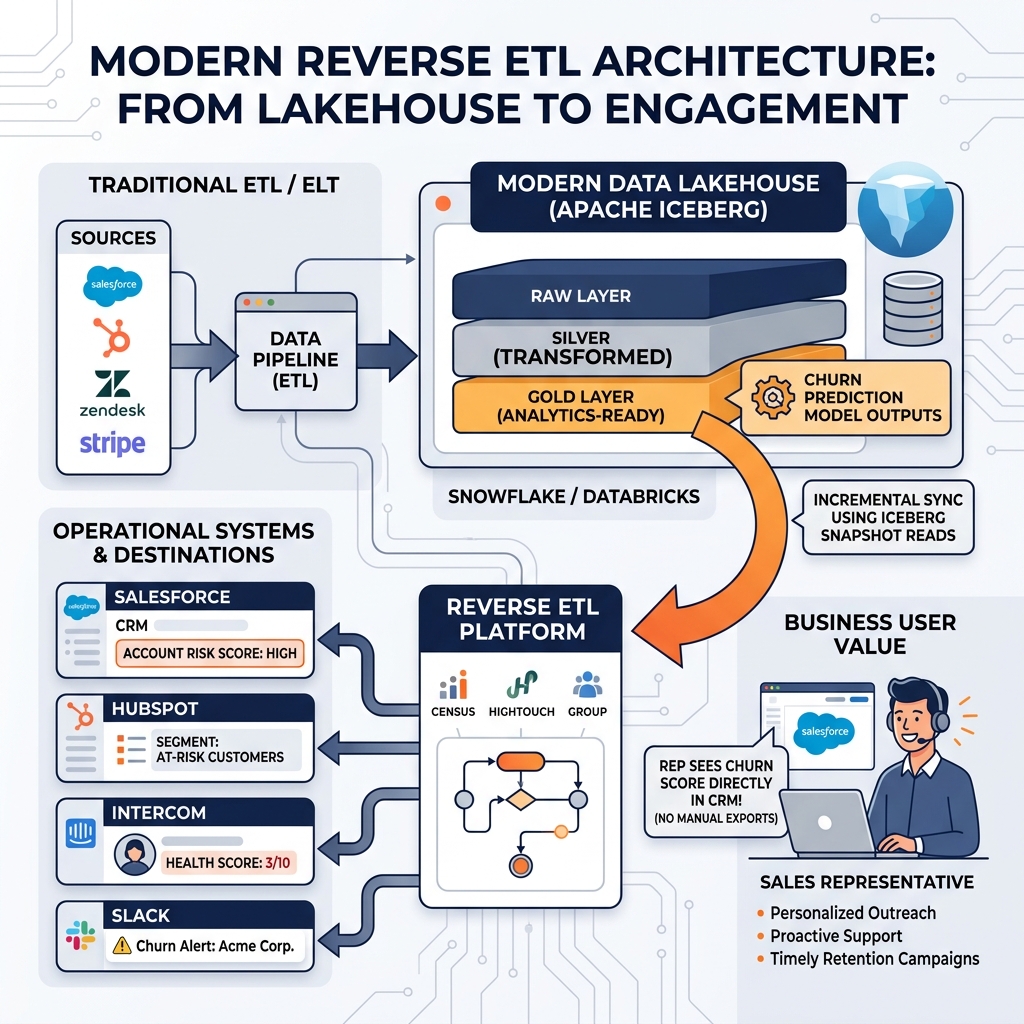
Reverse ETL Tooling and Iceberg Integration
Dedicated Reverse ETL platforms (Census, Hightouch, Polytouch) provide the infrastructure for building Reverse ETL pipelines without writing custom API integration code. These platforms connect to the data warehouse or lakehouse as a source (reading from Iceberg tables via Dremio’s SQL interface or directly via Arrow Flight) and connect to hundreds of operational destinations (Salesforce, HubSpot, Intercom, Zendesk, Marketo) through pre-built API connectors.
Reverse ETL platforms support incremental sync: on each pipeline run, only records that changed since the last run are synced to the destination, reducing API calls and destination system load. For Iceberg-backed sources, Iceberg’s snapshot-based incremental reads provide an efficient mechanism for the Reverse ETL platform to identify changed records without full table scans.
Dremio’s Virtual Datasets in the Semantic Layer serve as the ideal source for Reverse ETL pipelines. A Virtual Dataset that joins a churn model output table with a customer dimension table, computes the required fields, and filters to active accounts provides a clean, governed interface that the Reverse ETL platform queries. The Virtual Dataset abstracts the underlying Iceberg table complexity and ensures the Reverse ETL pipeline always reads business-ready data with correct semantics.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.