JSONL (Newline-Delimited JSON)
A guide to JSONL (JSON Lines), the newline-delimited JSON format widely used for streaming data, log ingestion, and semi-structured data exchange in modern data engineering pipelines.
JSON for Streaming and Batch Pipelines
Standard JSON represents a document as a single nested object or array. For a file containing many records, standard JSON wraps them in a top-level array: [{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}, ...]. This structure works well for small files but creates problems for large streaming datasets: parsing a 10GB JSON array requires reading the entire file before any records can be processed, the file cannot be split and processed in parallel, and appending a new record requires reading and rewriting the entire file.
JSONL (JSON Lines), also called NDJSON (Newline-Delimited JSON), solves these problems with a simple structural change. Rather than wrapping all records in a single top-level array, JSONL stores each record as a standalone, complete JSON object on its own line. The file format is simply one valid JSON document per line, with newlines as the record separator.
This line-oriented structure provides significant practical advantages. JSONL files can be read line by line, processing each record independently without loading the entire file into memory. Files can be split at line boundaries for parallel processing. New records are appended by writing new lines to the end of the file, without modifying existing content. Any tool that can read text files line by line can process JSONL without a specialized JSON array parser.
JSONL in Data Pipelines
JSONL is the dominant format for log data ingestion. Web servers, application backends, and cloud services typically emit events as structured JSON log lines, one event per line. Log aggregation pipelines (Fluentd, Logstash, Vector) collect these JSONL streams and route them to analytical destinations.
Kafka pipelines frequently use JSONL (or Avro with Schema Registry as a more governance-friendly alternative) as the message serialization format. Each Kafka message contains one JSONL record. Consumer pipelines read Kafka messages, parse the JSON, apply transformations, and write to Iceberg tables.
Apache Spark and Apache Flink both have native JSONL readers that can process JSONL files in S3 or other object storage in parallel across multiple tasks. Dremio reads JSONL files natively when configured with a file-based data source, allowing analysts to query JSONL logs in S3 directly through SQL without an explicit ETL step to convert them to Parquet.
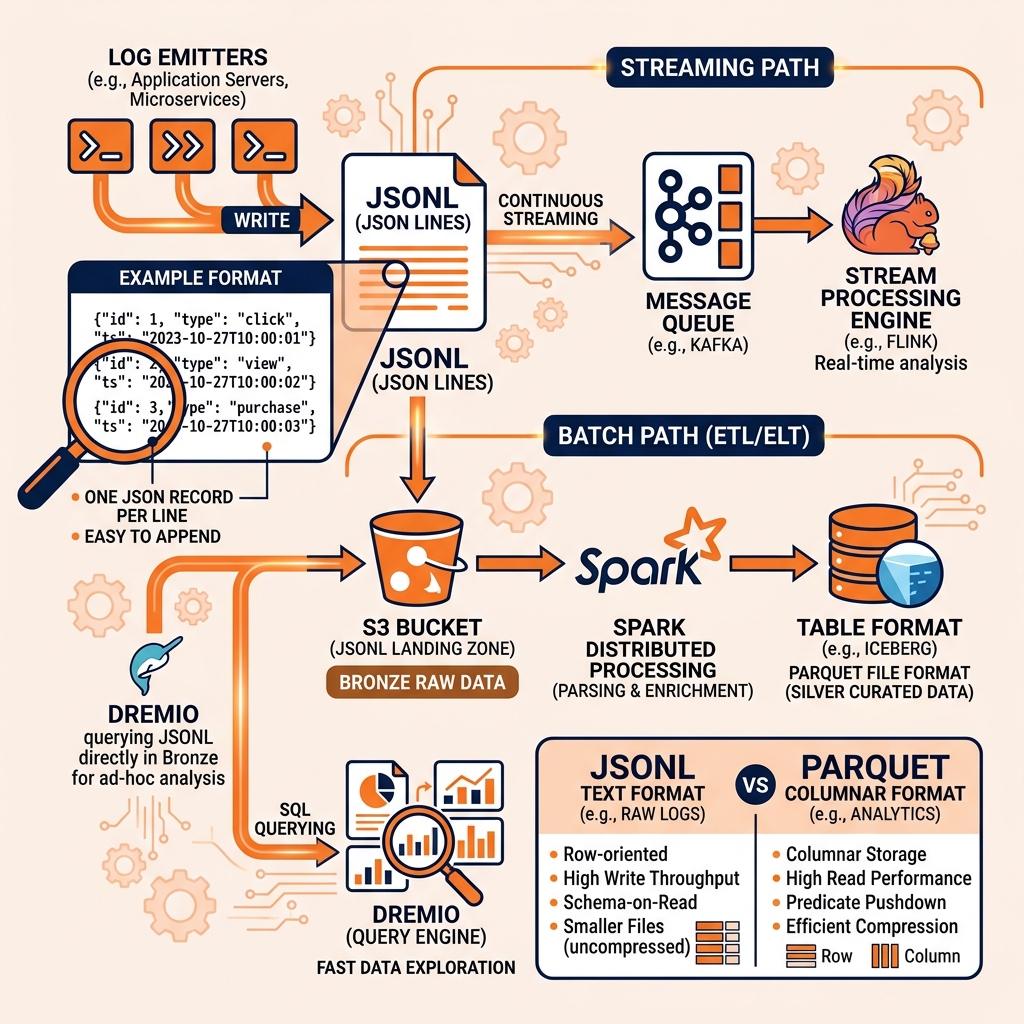
JSONL vs. Parquet for Analytics
JSONL is a text-based, row-oriented format. While its line-oriented structure enables streaming processing, it lacks the analytical performance advantages of columnar formats. JSONL files are uncompressed or gzip-compressed at the file level but cannot apply column-level encoding (dictionary encoding, delta encoding) that Parquet uses to achieve high compression ratios for analytical columns. JSONL queries that need only specific fields must still parse the complete JSON of every line to extract those fields.
For analytical workloads, JSONL serves as an ingestion and interchange format rather than a final storage format. The typical pipeline pattern converts JSONL landing zone files into Iceberg Parquet tables as part of the Bronze-to-Silver transformation: JSONL files in the raw landing zone (Bronze) are parsed by Spark, the schema is inferred or enforced, and the records are written to partitioned Iceberg Parquet tables (Silver) that provide full analytical query performance. JSONL columns containing nested structures are flattened and the nested fields promoted to top-level columns during this transformation.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.