Iceberg Table Branching
A guide to Apache Iceberg table branching, the Git-like feature that creates isolated development branches within a single Iceberg table, enabling safe data experimentation, multi-team collaboration, and the Write-Audit-Publish quality workflow.
Git Semantics for Data Tables
Software engineers have used Git’s branching model for decades to work on features in isolation, merge changes collaboratively, and roll back bad code without affecting the main production codebase. Until Apache Iceberg introduced table branching, data engineers had no equivalent isolation mechanism for data tables: every write went directly to the production table, and coordinating multi-team data development required complex workarounds involving separate tables, separate schemas, or careful scheduling.
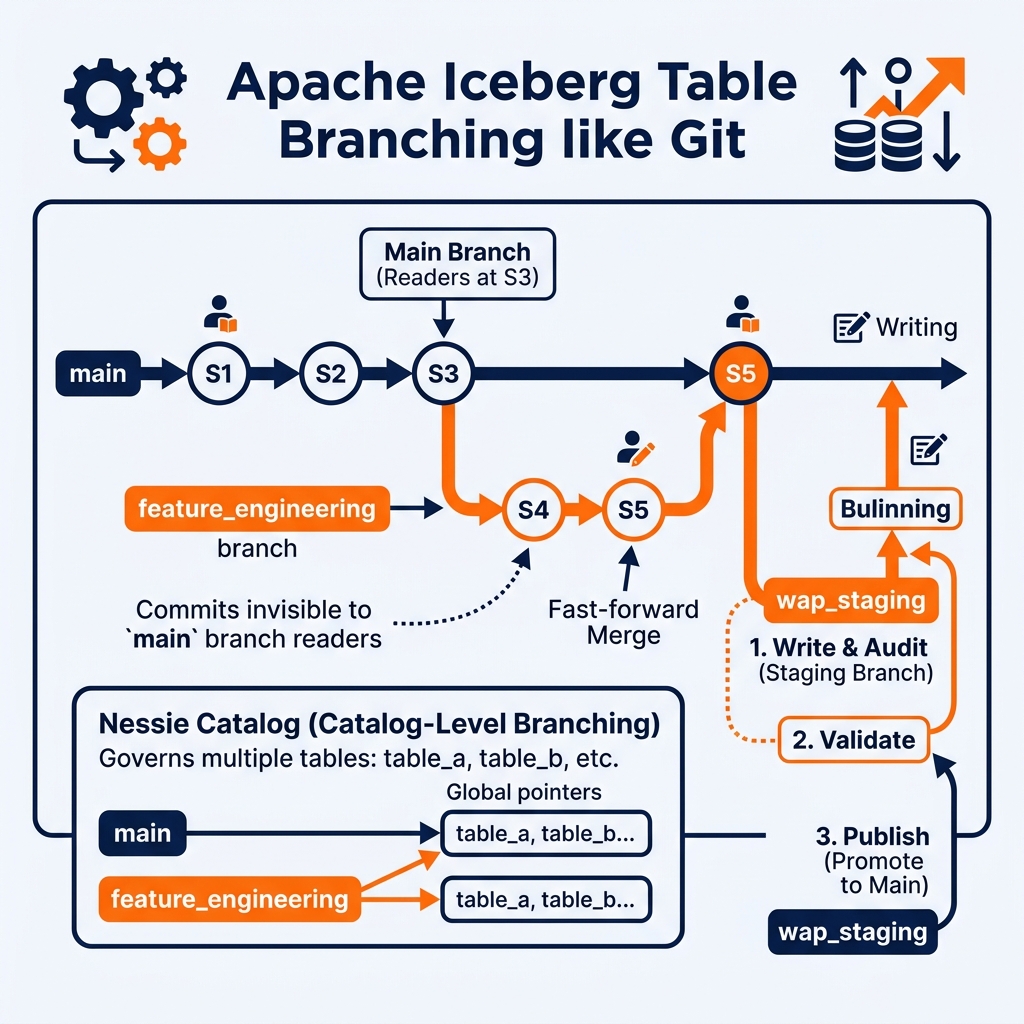
Apache Iceberg table branching brings Git-like semantics to data tables. A named branch is a pointer to a specific Iceberg snapshot that can advance independently of the main table reference. Multiple branches of the same table can coexist simultaneously, each pointing to a different snapshot and accumulating independent commit history. Changes committed to a branch are invisible to readers of other branches, providing true isolation.
The main table reference (the default read target) is itself implemented as a branch called main (or historically current). All other branches are named references that point to snapshots independent of main. A Spark session configured to read or write to a specific branch uses only that branch’s snapshot history for all table operations.
Branch Lifecycle
Creating a branch: A new branch is created from any existing snapshot or from an existing branch: ALTER TABLE catalog.db.table CREATE BRANCH feature_engineering FROM SNAPSHOT 1500. The new branch starts at snapshot 1500 and is independent of main.
Writing to a branch: Spark and Flink operations can be directed to a specific branch by configuring the branch in the session or write options. spark.conf.set("spark.wap.branch", "feature_engineering"). All writes in this session commit to the feature_engineering branch without affecting main.
Reading from a branch: Reading from a specific branch is configured similarly, allowing analysts to query the branch state independently: SELECT * FROM catalog.db.table VERSION AS OF 'feature_engineering'.
Merging a branch: When a branch’s changes are ready for production, the branch is merged or fast-forwarded to main: ALTER TABLE catalog.db.table FAST FORWARD BRANCH main TO BRANCH feature_engineering. This atomic operation advances main to the branch’s current snapshot.
Expiring a branch: When a branch is no longer needed, it is dropped: ALTER TABLE catalog.db.table DROP BRANCH feature_engineering. The branch’s snapshots may be cleaned up by the next snapshot expiration run.
Use Cases for Iceberg Branching
Write-Audit-Publish (WAP): The WAP quality workflow (described separately) uses an Iceberg branch as the staging area for new data, validated before being merged to main. The branch provides the isolation that makes WAP possible.
Feature engineering isolation: Data scientists can create a branch from the current main snapshot, apply experimental transformations to the branched table without affecting the production table, validate the results, and merge if the experiments are successful.
Multi-team parallel development: Teams building different features of the same table work on separate branches simultaneously. Each team’s work is isolated until merge, preventing interference between concurrent development efforts.
Blue-green deployments for data: A “green” branch of the table is prepared and validated in advance of a scheduled cutover. At the scheduled time, main is fast-forwarded to the green branch, atomically switching all readers to the new version with zero downtime and immediate rollback capability.
Nessie (Project Nessie) and Dremio’s Arctic catalog extend Iceberg branching to catalog-level branches, enabling branch semantics across all tables in the catalog simultaneously, providing a complete Git-for-data-catalog workflow.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.