Feature Engineering
A guide to feature engineering, the critical data science and engineering process of transforming raw data into meaningful variables (features) that machine learning algorithms can actually understand and learn from.
Crafting the Signal
A machine learning model is essentially a complex mathematical equation. It cannot understand raw text, vague dates, or unstructured concepts; it only understands numbers. If you feed a machine learning model raw, unrefined data directly from a production database, the model will fail to learn anything useful.
Feature engineering is the art and science of transforming raw data into meaningful, mathematical variables (features) that expose the underlying patterns of the problem to the machine learning algorithm. It is widely considered the most important, time-consuming, and difficult step in the entire machine learning lifecycle. A simple algorithm trained on brilliant features will almost always outperform a brilliant algorithm trained on simple features.
Common Feature Engineering Techniques
1. Encoding Categorical Variables:
A model cannot understand the text string Color: Red. Engineers use “One-Hot Encoding” to convert this into a binary matrix. Instead of one column with the word “Red,” the table gets three new columns: is_red, is_blue, and is_green, populated with 1s and 0s.
2. Date and Time Extraction:
A raw timestamp 2025-12-25 18:30:00 is nearly useless to an algorithm predicting restaurant sales. A feature engineer will extract meaningful cyclic features from it: day_of_week = 4 (Thursday), is_holiday = 1, and hour_of_day = 18. Suddenly, the model can learn that sales spike on Thursday evenings and holidays.
3. Scaling and Normalization:
If one column represents Customer Age (ranging from 18 to 90) and another represents Account Balance (ranging from $0 to $1,000,000), the model will mathematically assume the Account Balance is vastly more important simply because the numbers are bigger. Engineers “scale” all numerical features to fit within a tight range (like 0 to 1) so the model treats them equally.
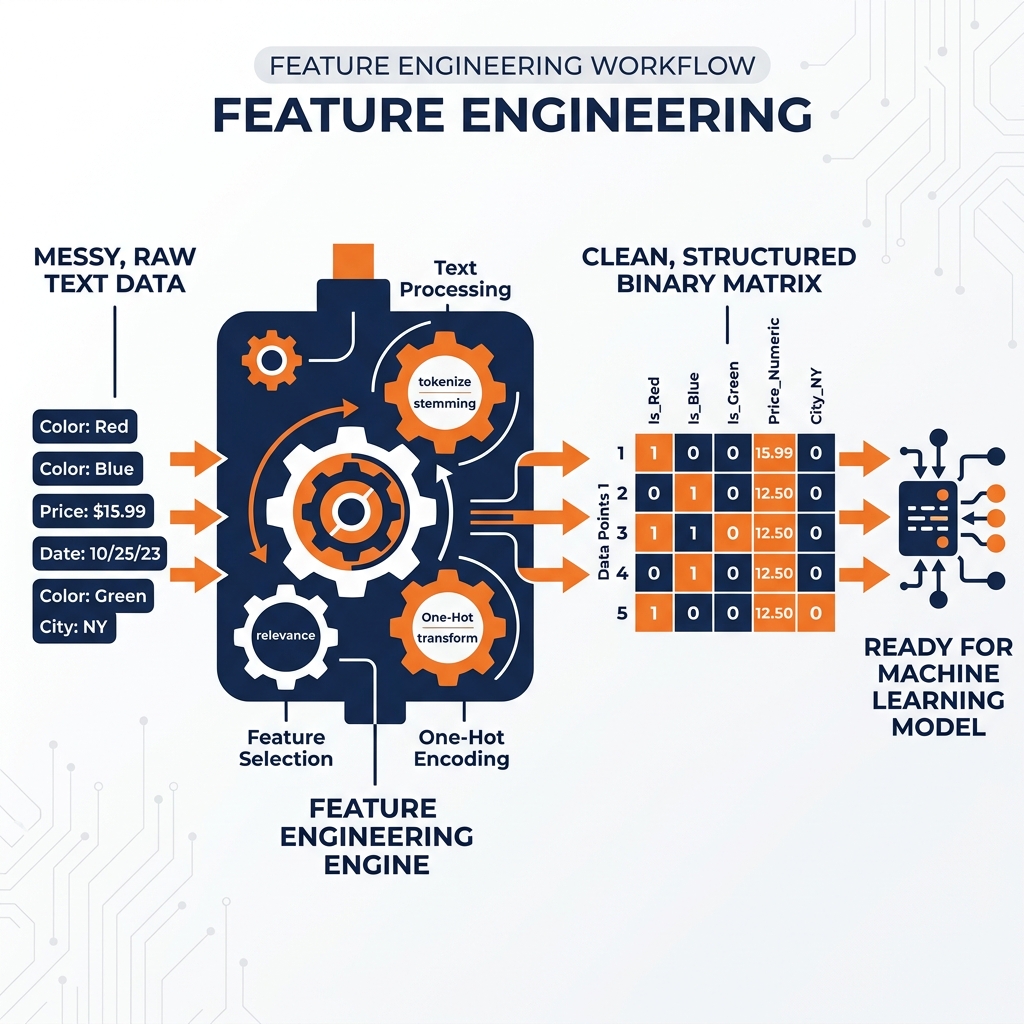
The Feature Store
Historically, data scientists would write complex Python scripts in a Jupyter Notebook to perform feature engineering. This created massive problems: the code was isolated on their laptop, and the engineering team had to completely rewrite the logic in Java or Scala to deploy the model into a production streaming pipeline. If the two scripts were slightly different (Training-Serving Skew), the model would fail in production.
Modern architectures solve this with a Feature Store.
The Feature Store acts as a centralized repository for engineered features. Data engineers build a pipeline once to calculate user_lifetime_value. They save this feature to the Feature Store.
When the Data Science team wants to train a model, they pull the historical values from the Feature Store. When the production application needs to make a real-time prediction, it pulls the exact same real-time value from the Feature Store API. The logic is defined once, eliminating skew and allowing teams to reuse features across hundreds of different machine learning models.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.