Feature Store
A guide to feature stores, the centralized ML infrastructure component that computes, stores, and serves machine learning features consistently across model training and real-time inference to eliminate training-serving skew.
The Training-Serving Skew Problem
A machine learning model’s performance in production depends critically on the features it was trained on matching the features it receives at inference time. If the feature computation logic differs between the training pipeline and the serving pipeline even slightly, the model receives inputs it was never trained to handle, silently degrading performance.
This training-serving skew is one of the most common causes of ML model degradation in production. The training pipeline computes features in batch (using a Spark job on historical data), and the serving pipeline computes features in real time (using a separate Python function in the inference service). Both are supposed to implement the same logic, but they are maintained separately, written in different languages, and diverge silently over time.
A feature store is the ML infrastructure component that solves training-serving skew by providing a single, authoritative computation and storage layer for ML features. Features are defined once in the feature store (as Python code with the feature computation logic), computed by the feature store’s batch or streaming pipelines, stored in the feature store’s offline and online storage layers, and served to both training jobs and inference services through the feature store’s API. The same computation logic produces the same feature values at training time and at serving time.
Feature Store Architecture
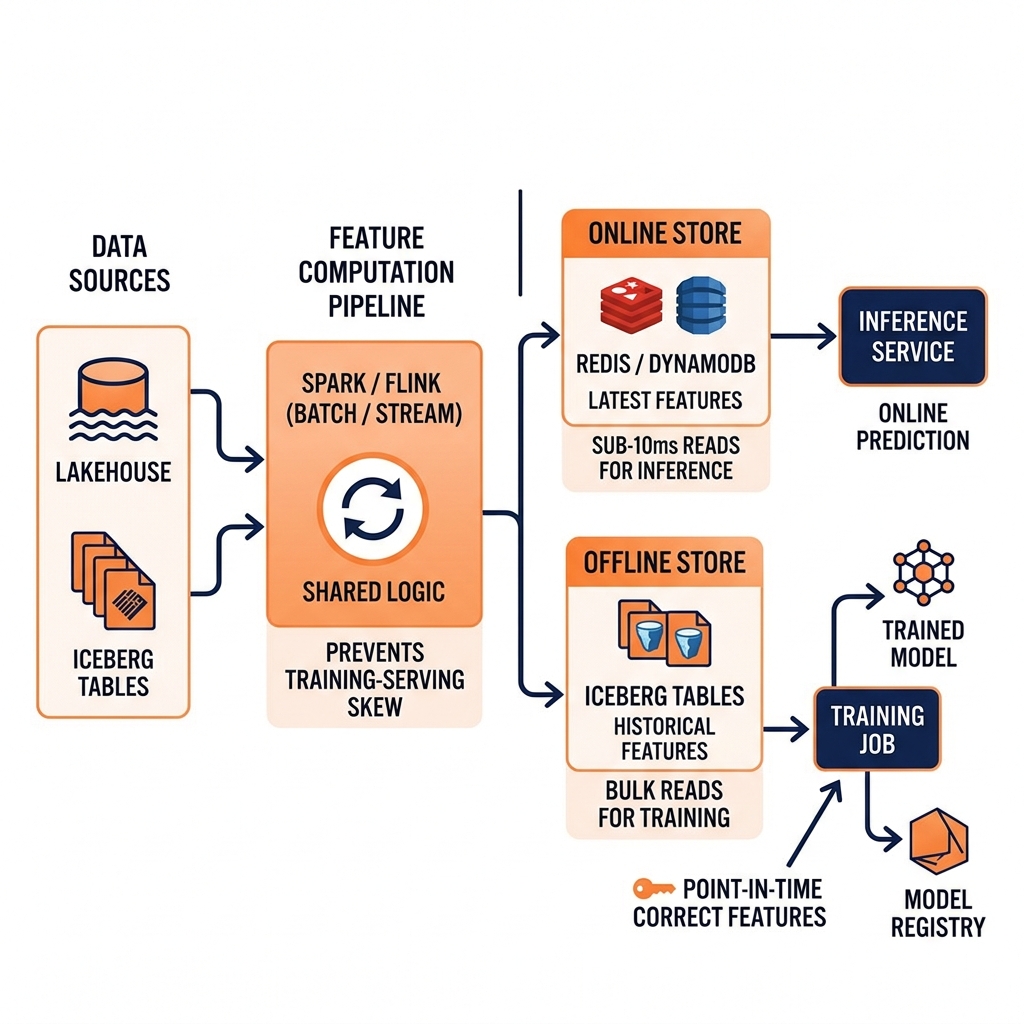
A feature store has two storage tiers with different performance characteristics.
Offline store: A historical feature store that retains feature values for all entities over time, used for model training and batch inference. The offline store is optimized for bulk reads: training jobs retrieve historical feature values for millions of entities to build training datasets. The offline store is commonly implemented on Apache Iceberg tables, providing time-travel capability for point-in-time correct feature retrieval (ensuring the training data does not contain future information that would not be available at inference time).
Online store: A low-latency feature store that retains only the latest feature values for each entity, used for real-time model inference. The online store is optimized for single-entity reads with millisecond latency: an inference request for user ID 12345 retrieves that user’s current feature vector from the online store in under 10 milliseconds. Online stores are commonly implemented on Redis, DynamoDB, or Cassandra.
The feature store’s materialization pipeline computes feature values from raw data (using Spark, Flink, or dbt) and writes them to both the offline store (as Iceberg snapshots) and the online store (as key-value records). This shared computation pipeline ensures that both stores contain feature values produced by the same computation logic.
Feature Stores and the Lakehouse
Feature stores integrate naturally with Iceberg-based lakehouses. The lakehouse’s Silver and Gold layer Iceberg tables are the primary raw data source for feature computation. Spark or Flink feature computation pipelines read from Iceberg tables, compute feature transformations, and write feature values to the feature store’s offline Iceberg tables.
Point-in-time correct feature retrieval from the offline store leverages Iceberg’s time travel: the training pipeline specifies the timestamp at which each training example’s label was observed, and the feature store retrieves the feature values that were current at that timestamp using Iceberg’s AS OF TIMESTAMP query syntax. This ensures that training examples contain only features that would have been available at prediction time, preventing label leakage.
Dremio’s integration with Iceberg enables direct analytical queries against feature store offline tables, supporting feature engineering exploration, feature drift monitoring, and feature quality dashboards through SQL without requiring a Spark session.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.