Data Gravity
A guide to Data Gravity, the concept that as datasets grow massive, they become increasingly difficult to move, forcing applications, compute, and services to be built physically close to the data itself.
The Mass that Attracts Compute
In physics, gravity is the force by which a planet or other body draws objects toward its center; the more massive the object, the stronger its gravitational pull. In 2010, software engineer Dave McCrory coined the term “Data Gravity” to describe how this exact phenomenon applies to enterprise data architectures.
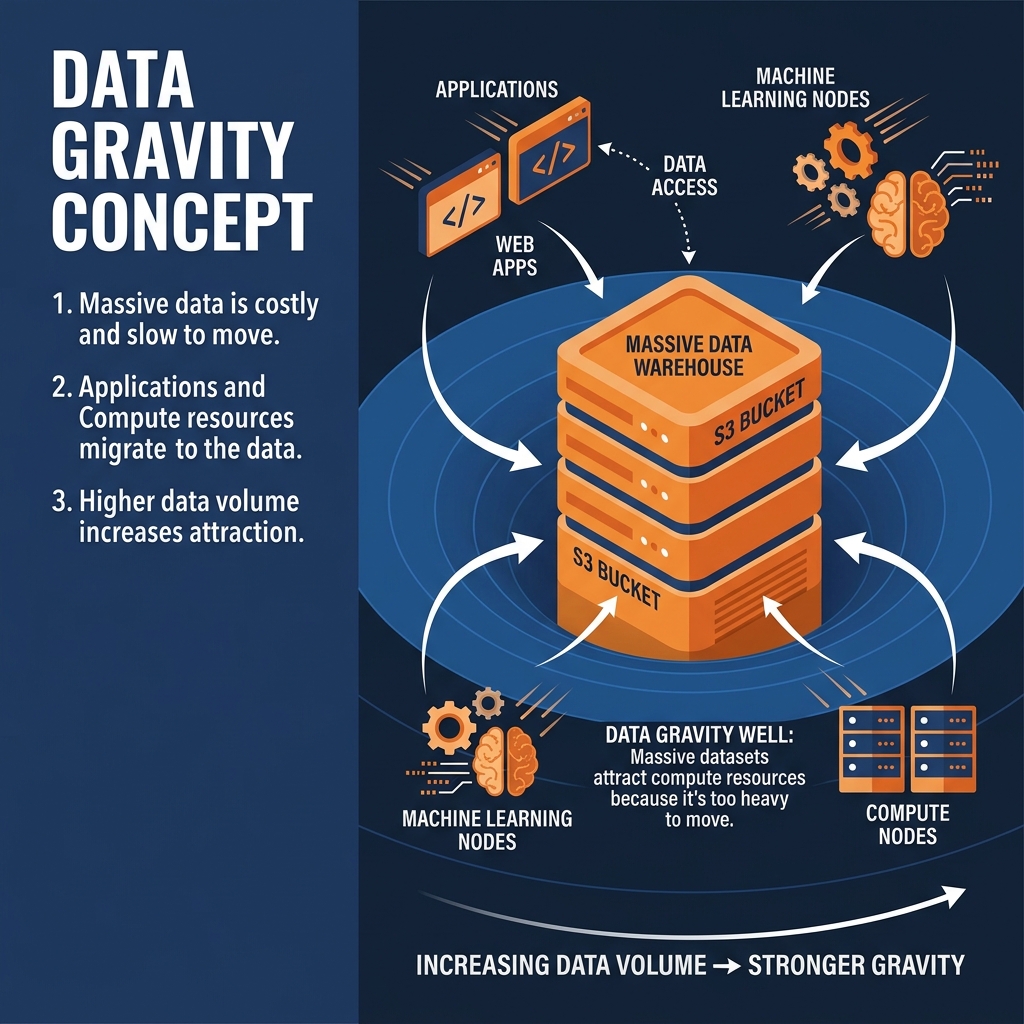
As a dataset grows in size and complexity (from gigabytes to terabytes to petabytes), it develops “mass.” This mass creates a gravitational pull. Because it is physically slow, incredibly expensive, and highly risky to move petabytes of data across internet networks, the data becomes immovable.
Therefore, instead of moving the data to the applications that need to process it, organizations are forced to move the applications, compute engines, and services so they reside physically adjacent to the massive dataset. The data’s gravity pulls the compute layer toward it.
The Impact on Cloud Strategy
Data gravity is the primary reason why large enterprises often find themselves suffering from cloud vendor lock-in.
If a company moves 50 Petabytes of historical data into Amazon S3, that data has immense gravity. If the company later decides they want to use Google Cloud’s BigQuery machine learning tools to analyze that data, they face a massive problem. Transferring 50PB of data from AWS to GCP over the public internet will incur millions of dollars in “egress fees” (the toll cloud providers charge to move data out of their network) and could take months of continuous transfer time.
Because the data cannot move, the company is forced to run their machine learning models on AWS using AWS tools, even if the GCP tools are superior. The gravity of the S3 bucket dictated the software architecture.
Mitigating Data Gravity
Data gravity cannot be eliminated, but modern data engineering architectures attempt to mitigate its negative effects through specific design patterns:
Open Table Formats: Storing data in proprietary database formats (like a Snowflake internal table) compounds gravity because the data is locked into that specific vendor’s ecosystem. By storing data in open formats like Apache Iceberg on generic object storage, the data’s gravity remains, but its accessibility increases. Multiple different compute engines (Dremio, Spark, Trino) can spin up in the same cloud region and access the Iceberg data simultaneously without moving it.
Data Mesh and Federation: Instead of trying to pull all enterprise data into a single, massive central repository (which creates a massive gravity well), a Data Mesh architecture leaves data in its distributed domains. Query Federation tools are used to logically join data across these domains at query time, minimizing physical data movement while still providing a unified view to analysts.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.