Apache Gravitino
A guide to Apache Gravitino, the open-source unified metadata layer that provides a single catalog API over multiple heterogeneous data sources, enabling governed multi-engine data discovery and access.
The Multi-Source Metadata Unification Problem
Modern enterprise data platforms rarely consist of a single storage system. An organization might store operational data in PostgreSQL, analytical data in Iceberg tables on S3, machine learning features in a feature store, messaging data in Kafka topics, and legacy reports in Hive. Each of these systems has its own metadata model, its own catalog interface, and its own access control model. Engineers must learn and manage five different catalog systems to understand what data exists across the platform.
Apache Gravitino is an open-source unified metadata layer that addresses this fragmentation. Gravitino provides a single, consistent REST API that abstracts over multiple underlying metadata sources and data systems. Databases, tables, schemas, and other metadata objects from Iceberg catalogs, Hive Metastore, MySQL, PostgreSQL, Kafka topics, and other systems are all exposed through the same Gravitino API, allowing a single client (a query engine, a data catalog UI, or a governance tool) to discover and interact with data assets from any of these systems through one interface.
Gravitino was originally developed by the Datastrato team and donated to the Apache Software Foundation in 2024, joining the Apache incubator as a community-governed project with contributions from multiple organizations.
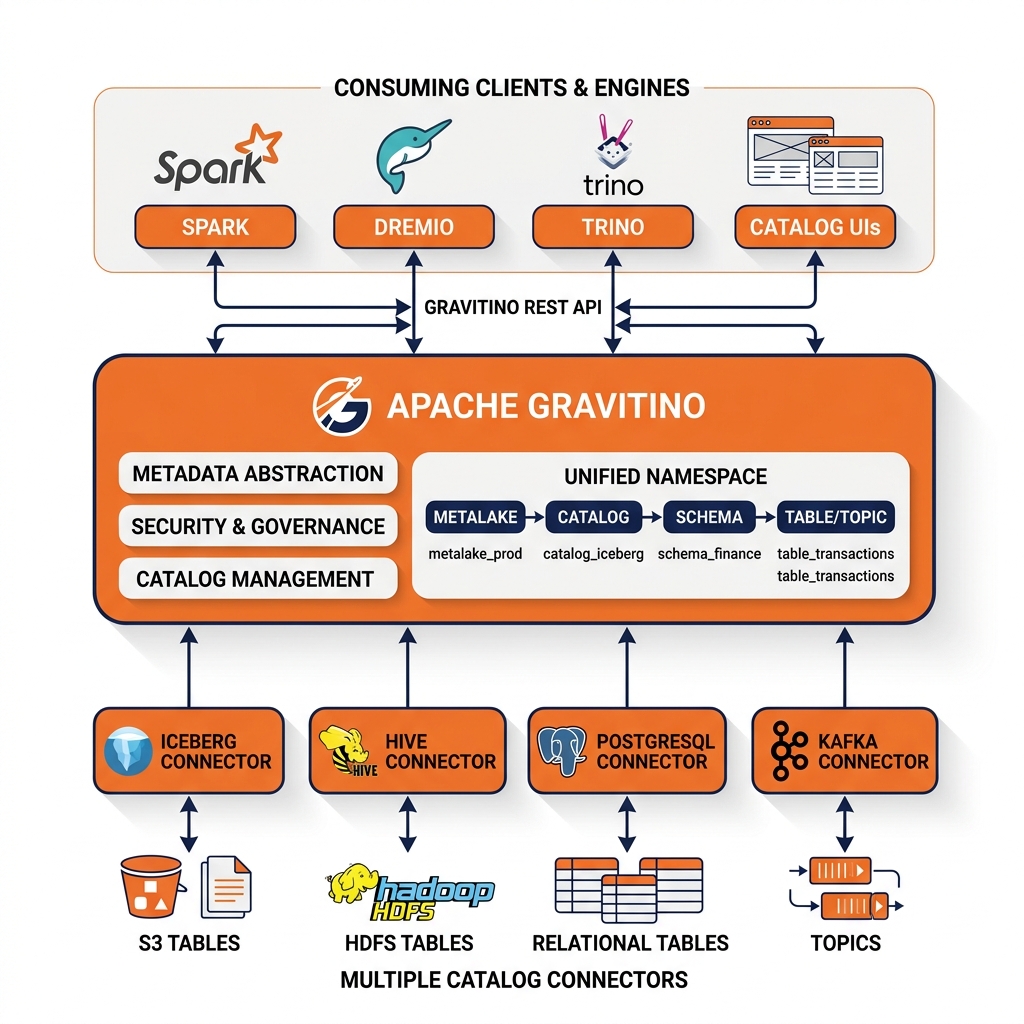
Gravitino’s Architecture
Gravitino operates as a metadata proxy layer. Each underlying data system is registered in Gravitino as a catalog through a connector plugin specific to that system type. The Iceberg REST catalog connector makes Iceberg tables accessible. The Hive connector makes Hive Metastore tables accessible. The JDBC connector makes relational database tables accessible. The Kafka connector makes Kafka topics accessible.
Once registered, all catalogs are organized under a unified namespace hierarchy: metalake > catalog > schema > table. A metalake is the top-level organizational unit (typically one per organization or team), containing multiple catalogs, each representing one underlying data system. Within each catalog, the native namespace hierarchy (schemas and tables) is mapped to Gravitino’s unified namespace model.
A query engine or catalog browser that speaks the Gravitino REST API can enumerate all catalogs in a metalake, list all schemas in any catalog, inspect table schemas from any underlying system, and retrieve metadata uniformly regardless of whether the underlying catalog is Iceberg on S3, Hive on HDFS, or PostgreSQL.
Gravitino as an Iceberg REST Catalog
Gravitino implements the Apache Iceberg REST Catalog specification, making Gravitino usable as a drop-in Iceberg catalog for any Iceberg-compatible compute engine. When configured with an Iceberg connector, Gravitino serves Iceberg REST Catalog API requests for the Iceberg tables in its scope, providing table load with credential vending, atomic commit operations, and namespace management through the standard REST spec.
This means compute engines (Spark, Flink, Dremio, Trino) can use Gravitino as their Iceberg catalog without any Gravitino-specific client code, while benefiting from Gravitino’s additional multi-source metadata unification capabilities.
Gravitino vs. Apache Polaris
Both Gravitino and Apache Polaris implement the Iceberg REST Catalog spec and serve as open-source catalog options for the Iceberg ecosystem, but their architectural focus differs. Apache Polaris is focused specifically on Iceberg table governance, with a sophisticated RBAC model, credential vending, and multi-catalog Iceberg management as its primary function. Polaris is optimized for the Iceberg-centric lakehouse.
Gravitino’s broader ambition is unified metadata across heterogeneous systems, including non-Iceberg data sources. For organizations that need catalog coverage across Iceberg, Hive, relational databases, and other systems through a single interface, Gravitino’s multi-source approach provides broader coverage. For organizations focused primarily on Iceberg governance and credential vending security, Polaris’s more specialized implementation may be the better choice.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.