Time-to-Live (TTL)
A guide to Time-to-Live (TTL), the automated data lifecycle mechanism that permanently deletes or archives records after a specified duration to enforce privacy compliance and manage storage costs.
The Automated Expiration Date
In the era of cheap cloud storage, the default engineering instinct is to save every piece of data forever. However, keeping data forever is a massive liability.
Under regulations like GDPR (Europe) and CCPA (California), organizations are legally prohibited from storing Personally Identifiable Information (PII) longer than is necessary for the original business purpose. If a user cancels their account, the company cannot legally keep their credit card history sitting in the data lakehouse for the next decade.
Furthermore, storing billions of irrelevant application logs from five years ago wastes significant cloud budget and slows down query performance by cluttering the tables.
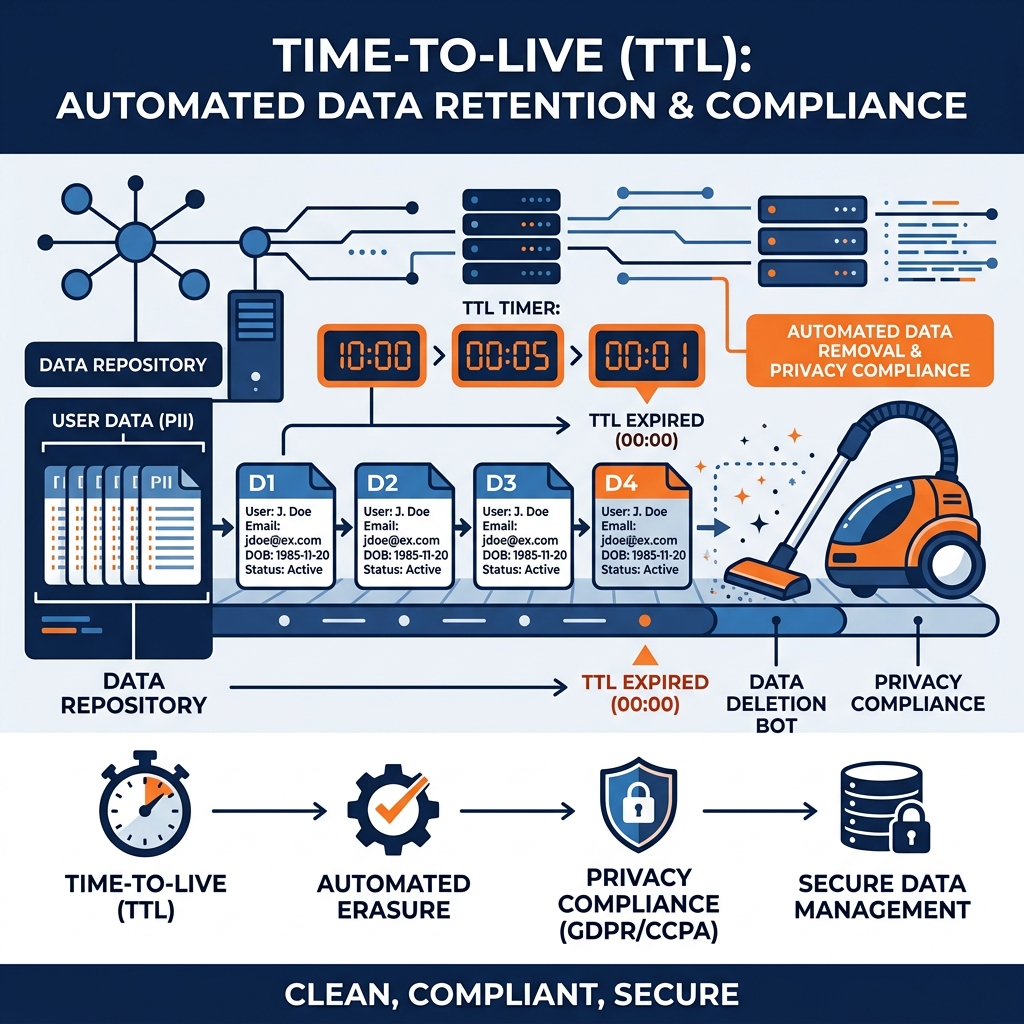
Time-to-Live (TTL) is the automated governance mechanism that solves this. It acts as an expiration date for data. When a record is written to a database or a lakehouse, it is tagged with a specific TTL duration (e.g., 30 days). Once that duration expires, the system automatically and permanently deletes the record without any human intervention.
TTL Implementations
Different storage systems handle TTL in different ways:
Key-Value Stores (e.g., Redis, DynamoDB): TTL is a native, highly optimized feature. When setting a key, you define an exact UNIX timestamp for expiration. A background process constantly sweeps the database and physically drops the expired keys, making it perfect for managing temporary user sessions or shopping carts.
Relational Databases: Standard SQL databases do not have native TTL. Data engineers must write custom background jobs (like an Airflow DAG) that run every night, executing a DELETE FROM logs WHERE created_at < NOW() - INTERVAL '30 days' command.
Data Lakehouses (Apache Iceberg): While Iceberg doesn’t delete the raw data rows automatically via TTL, it uses a similar concept for metadata: Snapshot Expiration. Every time an Iceberg table is updated, a new snapshot is created. If you update a table 1,000 times a day, the metadata overhead becomes massive. Engineers configure a snapshot TTL (e.g., “expire snapshots older than 7 days”). The catalog automatically cleans up the old metadata and deletes the orphaned Parquet files, keeping the lakehouse fast and cheap while preserving enough history for 7 days of Time Travel.
Balancing TTL and Analytics
Implementing strict TTL for compliance creates friction with the Data Science team, who want decades of historical data to train accurate machine learning models.
To satisfy both requirements, organizations implement a bifurcated pipeline. The raw user profile data in the production database has a strict 30-day TTL for compliance. Before the data expires, an ETL pipeline extracts the records, completely anonymizes them (hashing the names and dropping the emails), and writes the anonymized data to a separate “Data Archiving” layer in the lakehouse which has no TTL, safely providing the data scientists with the historical volume they need.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.