Data Archiving
A guide to data archiving, the strategic process of moving cold, infrequently accessed historical data off expensive, high-performance storage onto ultra-cheap, durable storage tiers to optimize costs.
Deep Storage for Cold Data
Not all data is created equal. A customer’s purchase from yesterday is “hot” data; the marketing team will query it a dozen times today to adjust their ad spend. A customer’s purchase from seven years ago is “cold” data; no one will look at it today, but the finance department is legally required by tax authorities to keep the record just in case of an audit.
Keeping 50 Terabytes of 7-year-old cold data in a high-performance Relational Database or pinned to the SSDs of a Dremio compute cluster is a colossal waste of money.
Data archiving is the automated lifecycle process of migrating this cold, infrequently accessed data away from expensive, fast storage and dumping it into incredibly cheap, deep storage tiers. The data is preserved safely and durably, but retrieving it may take hours instead of milliseconds.
Storage Tiers in the Cloud
Modern cloud object storage providers (like AWS S3) offer specific archiving tiers to facilitate this process:
S3 Standard (Hot): High cost, millisecond retrieval. Used for the active data lakehouse powering daily dashboards. S3 Standard-IA (Infrequent Access): Cheaper storage, but you pay a fee every time you retrieve the data. Used for data that is only queried once a month. S3 Glacier (Archive): Extremely cheap storage (a fraction of a cent per gigabyte), but retrieving the data takes several minutes or hours. S3 Glacier Deep Archive (Cold): The absolute cheapest storage on earth, but retrieving the data takes 12 to 48 hours.
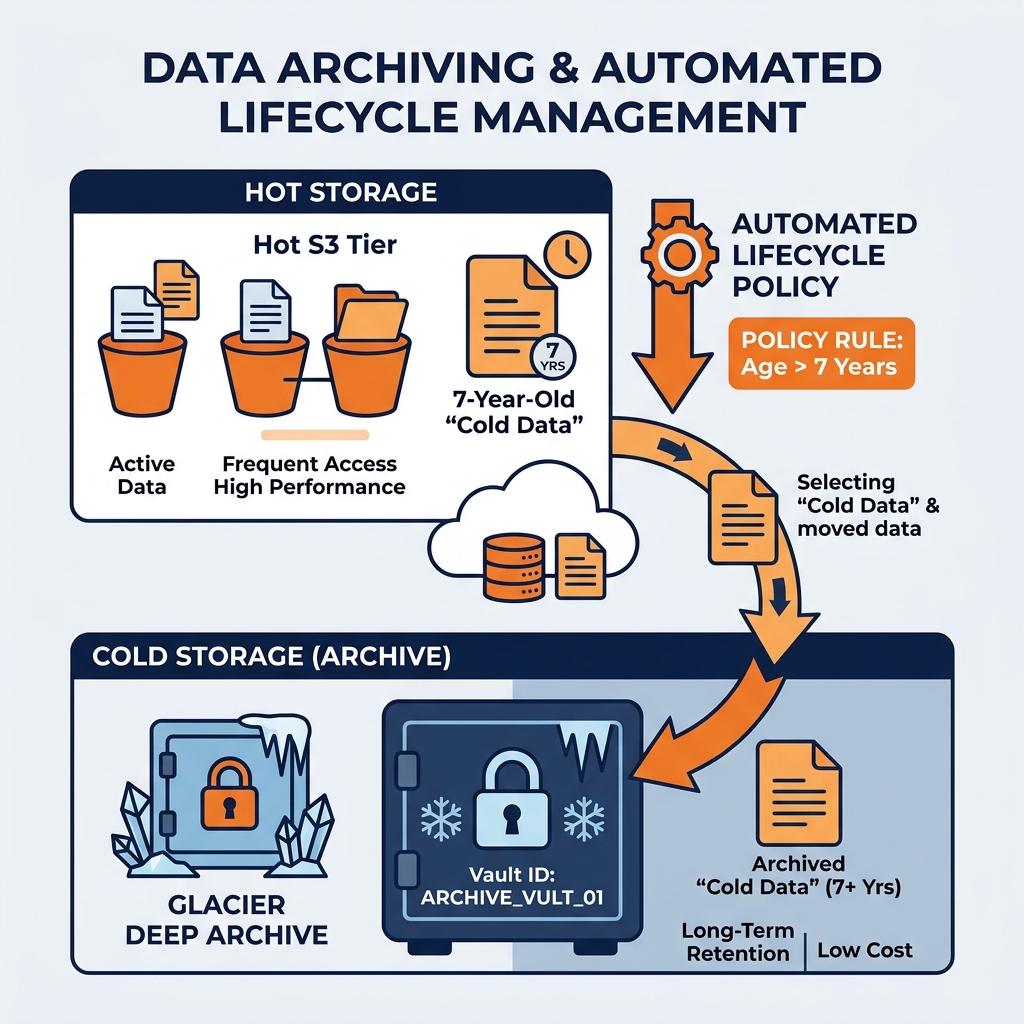
Automating the Lifecycle
Data engineers do not manually move files to Glacier. They configure Automated Lifecycle Policies at the storage level.
An engineer defines a policy on the S3 bucket: “When a Parquet file becomes 1 year old, automatically transition it from Standard to Glacier. When it becomes 7 years old, permanently delete it.”
The cloud provider automatically monitors the creation dates of millions of files and transparently moves them to the cheaper archiving tiers.
This creates a massive challenge for query engines. If an analyst accidentally runs a query SELECT * FROM sales WHERE year = 2018, and that data is in Glacier, the query engine will hang and fail, because it cannot wait 12 hours for the file to “thaw.” Modern data catalogs and query engines must be deeply aware of the storage tier, proactively warning the user or gracefully preventing the query from touching archived data unless a formal “restore” job is initiated.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.