Query Caching
A guide to query caching, the performance optimization technique that stores the results of complex database operations in fast memory to drastically reduce response times for subsequent, identical queries.
Remembering the Answer
In a modern enterprise data platform, computing the answer to a complex analytical question is incredibly expensive. If a CEO opens a dashboard that executes a SELECT sum(revenue) FROM fact_sales JOIN dim_date... query spanning 5 years of history and billions of rows, the underlying compute engine (like Dremio or Snowflake) might spin up dozens of server nodes, read terabytes of data from disk, shuffle it across the network, and take 15 seconds to return the final aggregated number.
If the CFO opens that exact same dashboard five minutes later, forcing the engine to re-read those same terabytes of data and perform the exact same massive computation just to return the exact same number, it is a massive waste of time, compute resources, and cloud budget.
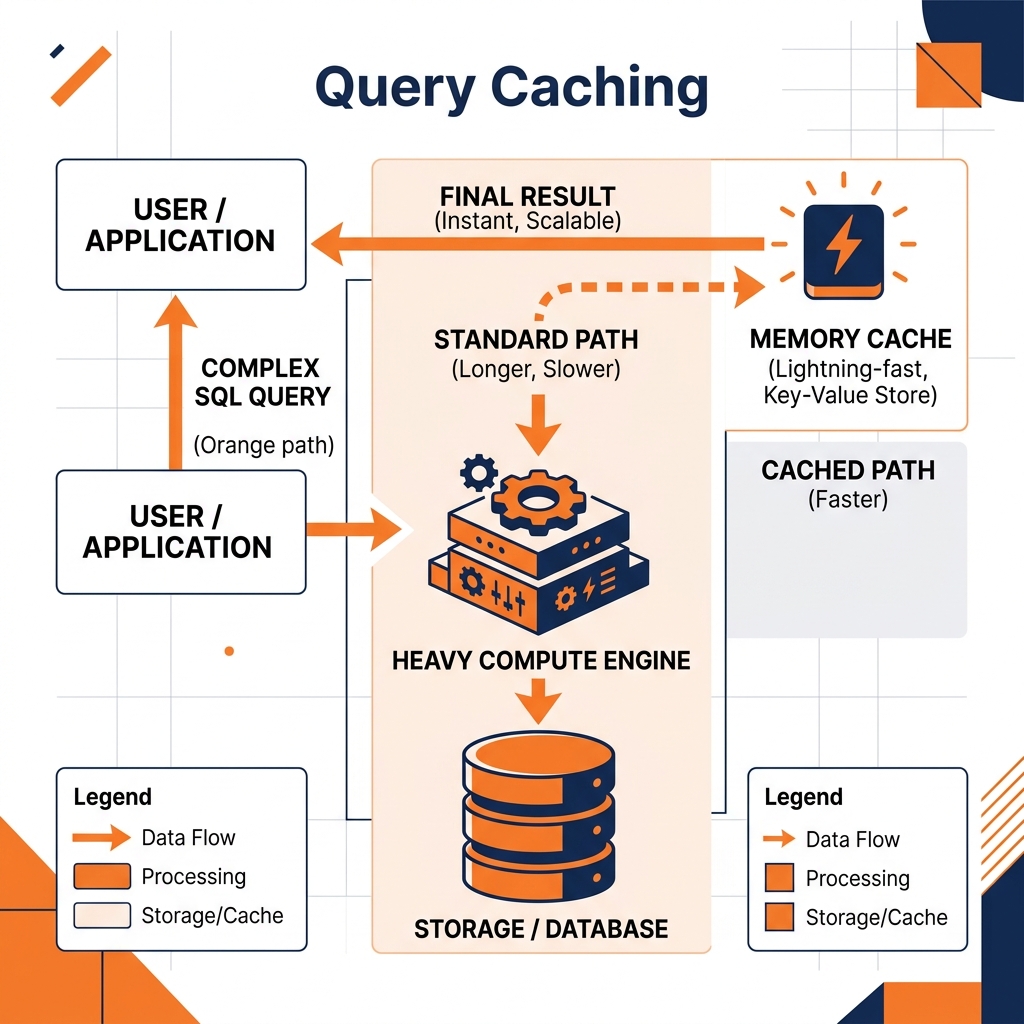
Query caching solves this by trading cheap memory for expensive compute. When a query is executed, the engine stores the final result in a high-speed, temporary storage layer (usually RAM or fast SSDs). If the exact same query is issued again shortly after, the engine bypasses the heavy computation entirely and serves the result instantly from the cache.
The Challenges of Cache Invalidation
The hardest problem in computer science is cache invalidation. A cached result is only useful if it is accurate.
If the fact_sales table receives a new batch of streaming data at 10:05 AM, the cached answer from 10:00 AM is now stale and mathematically incorrect. The data platform must immediately “invalidate” (delete) the cache so that the next query is forced to compute the fresh result.
In a modern lakehouse architecture utilizing Apache Iceberg, cache invalidation is highly efficient. Because Iceberg provides strict snapshot IDs for every transaction, the query engine simply checks if the underlying table’s snapshot ID has changed since the cache was created. If it hasn’t, the cache is guaranteed to be perfectly accurate and is served instantly.
Types of Caching
Data platforms implement caching at multiple architectural layers:
1. Metadata Caching: Caching the structural information about the tables (where the files are located on S3, column statistics). This prevents the engine from making slow API calls to the object storage just to plan the query.
2. Data (File) Caching: Caching the raw Parquet files themselves on the local NVMe drives of the compute nodes. The engine still executes the query logic, but it reads the data from local disk at gigabytes per second rather than pulling it across the network from Amazon S3.
3. Result Set Caching: The highest level of caching. Caching the final, computed output of the query so the entire execution plan can be bypassed.
While caching is powerful, it is not a silver bullet. If every user is asking slightly different questions (ad-hoc queries with unique WHERE clauses), the cache hit rate drops to zero, and the system pays the overhead of managing the cache without reaping any of the benefits. For these dynamic workloads, structural accelerations like Dremio Data Reflections are required.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.