Multi-Table Transactions
A guide to multi-table transactions in Apache Iceberg, the ability to atomically commit changes across multiple Iceberg tables in a single transaction, ensuring cross-table consistency without distributed locking overhead.
The Cross-Table Consistency Problem
ACID transaction semantics in Apache Iceberg operate at the table level: a write to a single Iceberg table either succeeds atomically or fails completely, with no partial state visible to readers. But complex data engineering workflows often need to maintain consistency across multiple related tables simultaneously.
Consider a financial accounting system that updates a journal_entries table with new transaction records and updates a account_balances table with the resulting balance changes in the same pipeline step. If the journal_entries write succeeds but the account_balances write fails, the accounting data is inconsistent: journal entries record transactions whose effects are not reflected in the account balances. A reader querying both tables after the partial failure will see an inconsistent state.
Without multi-table transaction support, the engineering solution is defensive coding: implement idempotent writes, maintain watermarks in metadata tables, use compensating transactions to undo partial writes on failure. These patterns work but add significant complexity to pipeline code.
Multi-table transactions enable atomic commits across multiple Iceberg tables: either all table updates in the transaction commit atomically, or none of them do. Readers always see either the complete pre-transaction state of all tables or the complete post-transaction state of all tables.
Apache Iceberg Multi-Table Transaction API
Apache Iceberg’s catalog API includes the createTransaction method for initiating a multi-table transaction. Within a transaction, multiple table write operations are accumulated and their resulting snapshot updates are committed atomically when the transaction is committed.
A multi-table transaction in PyIceberg:
with catalog.create_multi_table_transaction() as txn:
journal_txn = txn.new_append(journal_table)
journal_txn.append_file(journal_data_file)
balances_txn = txn.new_overwrite(balances_table)
balances_txn.add_file(new_balances_file)
balances_txn.delete_file(old_balances_file)
# Commits both atomically or rolls back both
txn.commit_transaction()The catalog implements the atomicity guarantee by writing all metadata updates to both tables atomically in the catalog’s metadata store. If the commit to the catalog’s metadata store fails after writing the first table’s metadata but before writing the second, the catalog rolls back the first table’s metadata update during recovery, leaving both tables in their pre-transaction state.
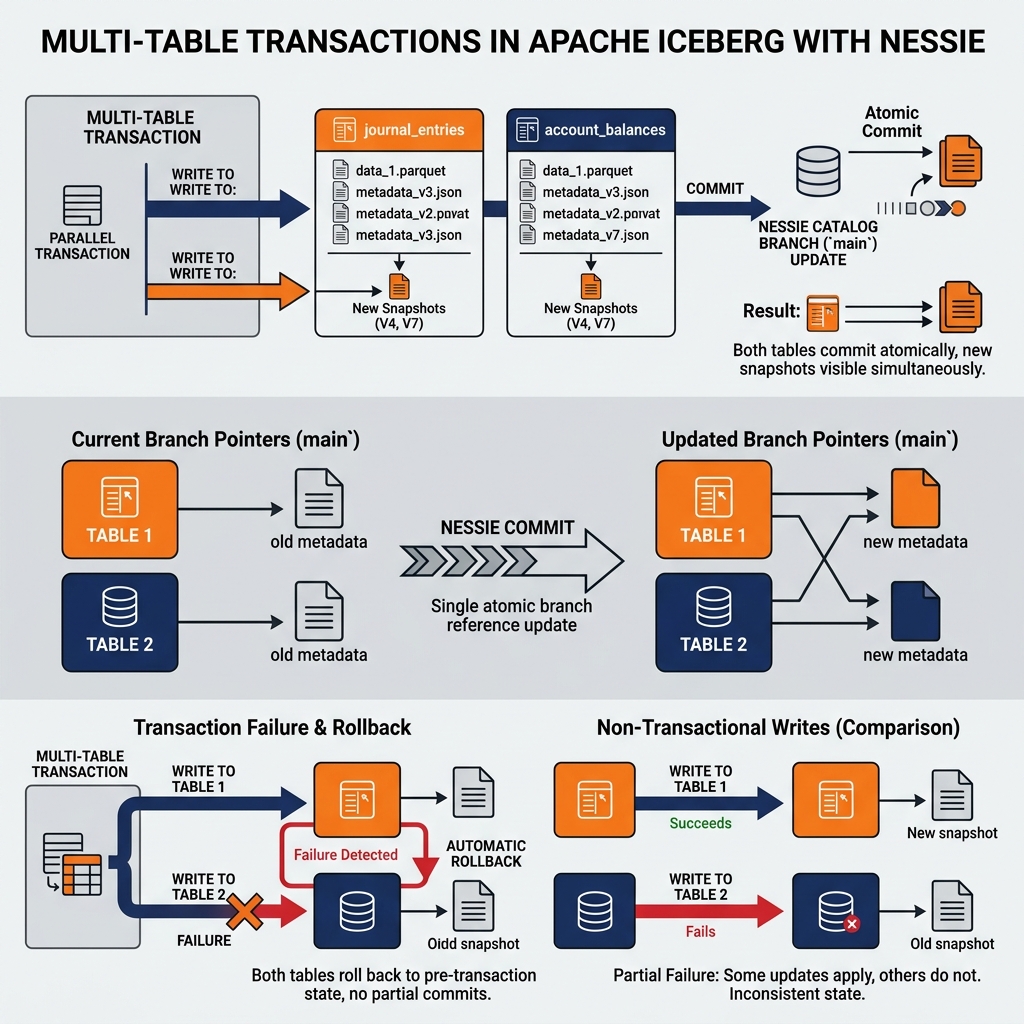
Project Nessie and Multi-Table Transactions
Project Nessie provides particularly strong multi-table transaction semantics through its Git-like branching model. Because Nessie tracks the complete catalog state (all tables’ current metadata pointers) at each commit, a Nessie transaction is a commit to the catalog branch that atomically updates multiple tables’ metadata pointers in a single branch commit.
This branch-level atomicity is equivalent to a multi-table transaction: all tables’ updates within a Nessie commit are visible atomically to readers. A reader on the main branch either sees all updates from the commit or none of them, providing cross-table consistency that aligns with Git’s commit atomicity model applied to data.
For complex data engineering pipelines requiring cross-table consistency guarantees, Nessie-backed Iceberg catalogs (available through Project Nessie or Dremio’s Arctic catalog) provide the strongest multi-table consistency semantics in the open lakehouse ecosystem.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.