Hidden Partitioning
A comprehensive guide to Apache Iceberg's hidden partitioning, the feature that decouples physical data organization from analytical query semantics, eliminating partition-aware query requirements.
The Partitioning Literacy Problem
Data partitioning is one of the most powerful performance optimization tools available to data engineers. By organizing data files into directories based on column values (partitioning by date, region, or category), the query engine can skip entire directories when a query’s WHERE clause does not match the partition values. A query filtering WHERE order_date = '2024-03-15' against a table partitioned by order_date reads only the files in the 2024-03-15 partition directory, skipping potentially billions of rows in other partitions.
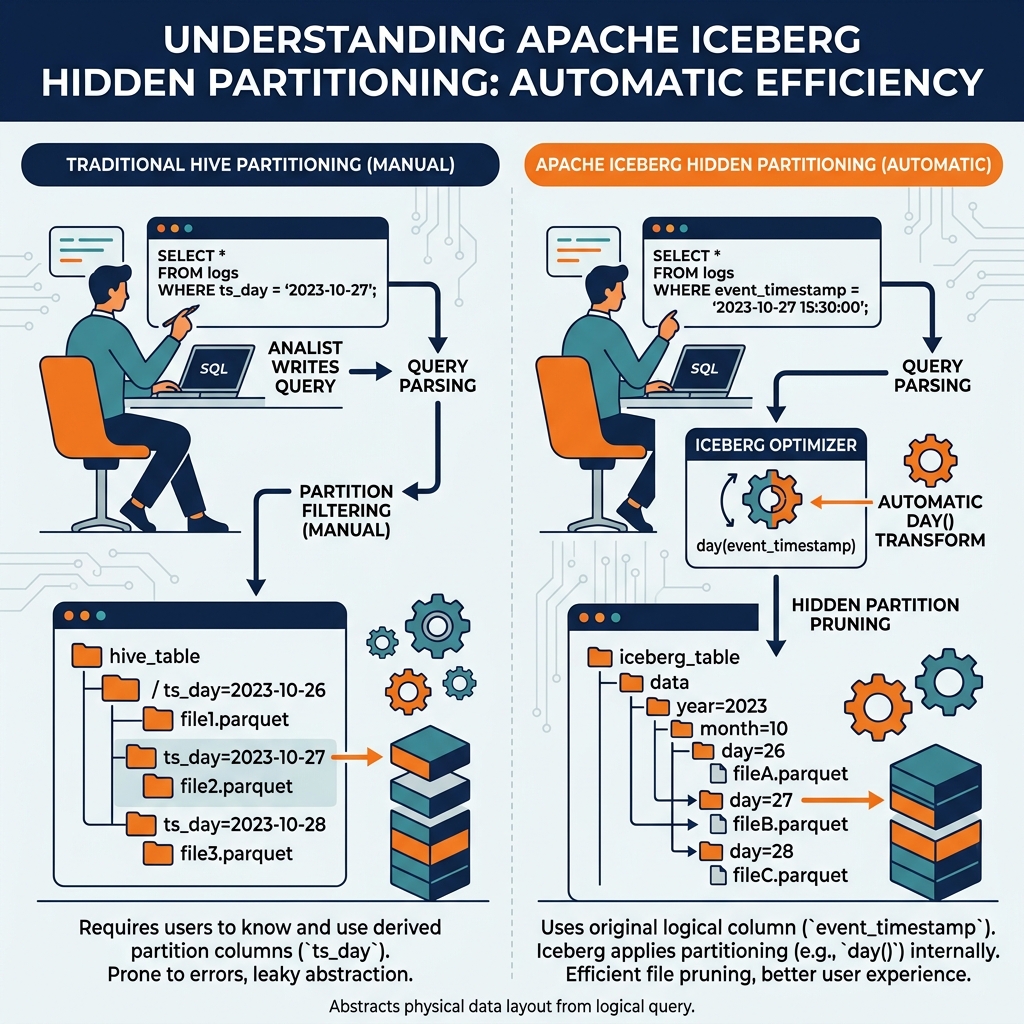
But traditional partitioning implementations, particularly in Hive-compatible systems, expose the physical partition structure directly to the query author. To get partition pruning, the analyst must know how the table is partitioned and write their query accordingly. If the table is partitioned by a column named dt containing strings in YYYY-MM-DD format, a query filtering on a timestamp column will perform a full table scan, reading all partitions, because the query engine does not automatically recognize that timestamp = '2024-03-15 14:30:00' corresponds to dt = '2024-03-15'.
This partition literacy requirement creates multiple classes of problems. Analysts who do not know the partition scheme write non-pruned queries that consume enormous compute resources. Schema changes that restructure partitions (switching from monthly to daily partitioning, or changing the partition column name) require all existing queries to be updated simultaneously or risk performance degradation. Data engineers become a bottleneck as they field questions about partition schemes and review queries for partition-aware correctness.
Apache Iceberg’s hidden partitioning feature was designed to completely eliminate this problem. With hidden partitioning, the query author does not need to know how the table is physically organized; the query engine automatically derives the correct partition filter from the query’s predicates, applying partition pruning transparently regardless of how the data is organized on disk.
How Hidden Partitioning Works
In Apache Iceberg, partitioning is defined through transform functions applied to source columns. Common transforms include identity (partition by the raw column value), year, month, day, and hour (extract the corresponding time unit from a timestamp column), bucket(N) (hash the column value into N buckets), and truncate(W) (truncate a string or integer to width W).
When a table is defined with PARTITIONED BY (day(event_timestamp)), Iceberg stores the data files organized by day, but this partitioning is invisible to query authors. Analysts write queries using the original event_timestamp column without any awareness of the physical day-based organization. When the query engine processes WHERE event_timestamp BETWEEN '2024-03-01' AND '2024-03-31', it automatically applies the day() transform to the predicate boundaries, computes that this corresponds to days 2024-03-01 through 2024-03-31, and prunes all data files outside that range. Partition pruning happens automatically with zero analyst intervention.
This decoupling of physical organization from analytical semantics is the core value proposition of hidden partitioning. The partition transform is an implementation detail managed by the data engineering team, completely invisible to the data consumers who query the table.
Partition Evolution
The most powerful consequence of hidden partitioning is that it enables partition evolution: changing the physical partitioning scheme of a table without breaking any existing queries and without rewriting any existing data.
Consider a table initially partitioned by month, which was appropriate when the table was small. After three years of data accumulation, each monthly partition has grown to contain billions of rows, making even month-filtered queries slow because of the large amount of data within each partition. The data engineering team decides to repartition by day for improved granularity.
In a traditional Hive-partitioned table, this change requires a full table rewrite (reading all existing data and rewriting it into the new daily partition directories) and updating every downstream query that references the monthly partition column. This is an extremely disruptive operation that typically requires coordinated downtime.
With Iceberg partition evolution, the data engineering team adds the new day(event_timestamp) partition spec to the table using ALTER TABLE ... ADD PARTITION FIELD. Existing data files remain in their original monthly-partitioned locations. New data ingested after the evolution is written using the new daily partitioning scheme. Iceberg maintains the partition spec history and applies the correct pruning strategy per data file based on which partition spec was active when that file was written. Queries using event_timestamp predicates automatically receive pruning against both the old monthly files (using the month-based spec) and the new daily files (using the day-based spec). The evolution is completely transparent to analysts and requires no query updates.
Multi-Column and Bucket Partitioning
Iceberg hidden partitioning supports multi-column partition specs, enabling sophisticated physical data organization strategies that remain transparent to query authors.
A table partitioned by (day(event_timestamp), identity(region)) organizes data files first by day, then by region within each day. Queries filtering on both event_timestamp and region receive two-dimensional pruning, dramatically reducing the files read for regional time-series analysis. Neither the day() transform nor the region partition column needs to appear explicitly in the analyst’s query predicate; Iceberg’s query planner automatically resolves both pruning dimensions from the raw column predicates.
Bucket partitioning is particularly valuable for high-cardinality columns like user_id or order_id. A bucket(256, user_id) partition spec distributes rows evenly across 256 buckets based on the hash of user_id. Queries filtering on specific user_id values are automatically routed to the correct bucket, providing efficient lookup performance even on very high-cardinality identifiers that cannot be partitioned by identity (because there would be millions of distinct partitions, one per user).
Dremio and Hidden Partition Optimization
Dremio’s query planner natively understands Iceberg’s hidden partitioning metadata and applies partition pruning as part of its distributed query planning process. When Dremio generates an execution plan for a query against an Iceberg table, it reads the partition spec from the Iceberg metadata, derives the applicable partition filters from the query predicates, and passes only the relevant data file paths to the distributed scan operators. Analysts querying Iceberg tables through Dremio’s Semantic Layer receive full hidden partition pruning benefits automatically, regardless of whether they are using Dremio’s SQL editor, a connected BI tool, or an AI agent generating queries through the REST API.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.