Partition Evolution
A guide to Apache Iceberg partition evolution, the capability that allows table partitioning to be changed without rewriting data, enabling partition strategies to adapt to changing query patterns and data volumes without downtime or costly migrations.
Partitioning Locked at Table Creation
In Hive-style partitioned tables, the partition columns are defined once at table creation and cannot be changed without rebuilding the entire table. A table created with PARTITIONED BY (year INT, month INT) retains that partition scheme forever. If query patterns change (daily partitioning would now be more efficient, or the partition column’s data type needs to change), the only option is to create a new table with the new partition scheme and rewrite all existing data into the new partitions. For a petabyte-scale table, this is a multi-day migration that must be carefully coordinated with all readers and writers.
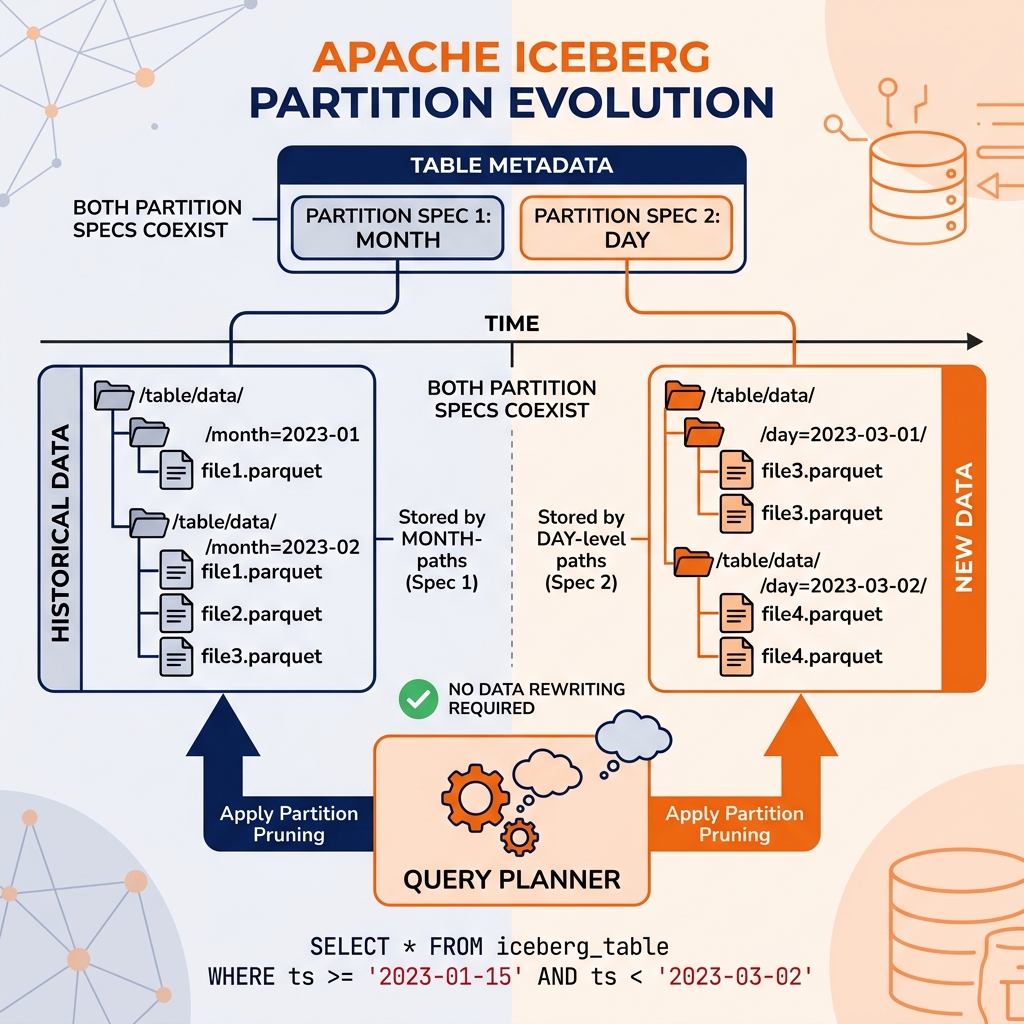
Apache Iceberg’s partition evolution solves this limitation by decoupling the partition scheme from the data files. In Iceberg, each table can have multiple partition specs (partition strategies) active simultaneously. When the partition spec changes, new data files are written using the new partition spec. Old data files retain their original partition layout. The query planner understands both old and new partition specs and applies the appropriate pruning logic when planning scans across files with different partition schemes.
This means a partition spec change in Iceberg is instantaneous (a metadata-only operation) and requires no data rewriting. Old and new data coexist in the same table with different partition layouts, and the query planner handles both correctly.
Partition Spec Changes
Iceberg supports several types of partition spec evolution:
Adding a partition field: Adding a new dimension to the partition scheme. A table previously partitioned by month(event_time) can be evolved to partition by month(event_time), region. New data files are written into the two-dimensional partition structure; old data files retain the single-dimension structure. Queries filtering on region can still benefit from partition pruning for new data (skipping files outside the queried region), while old data files are scanned using the original month-based pruning.
Replacing a partition field: Changing the granularity of time-based partitions as data volumes grow. A table originally partitioned by year(event_time) can evolve to month(event_time) as the table grows and monthly partitions become the right size. New data is partitioned by month; old annual partitions remain unchanged.
Removing a partition field: Removing a dimension that is no longer useful for pruning. New data files are written without that partition dimension; old files retain it.
Changing a partition transform: Changing from identity(region) partitioning (exact match on string values) to bucket(region, 50) partitioning (hashing region values into 50 buckets to prevent small-file problems with many distinct regions).
Hidden Partitioning and Partition Transforms
Iceberg’s partition evolution is enabled by hidden partitioning: instead of exposing raw partition column values to writers and readers, Iceberg applies partition transform functions to compute partition values from data columns. Common transforms include:
identity(col): Partition by the raw column value (equivalent to Hive-style partitioning)year(timestamp_col): Partition by the year extracted from a timestamp columnmonth(timestamp_col): Partition by year-month extracted from a timestamp columnday(timestamp_col): Partition by the date extracted from a timestamp columnhour(timestamp_col): Partition by the hour of a timestamp columnbucket(col, N): Partition by hashing the column value into N bucketstruncate(col, W): Partition by truncating string or integer columns to width W
Because partition transforms are applied by the table format rather than by the writer, writers do not need to know the partition scheme or compute partition values manually. And because the transforms are stored in the partition spec metadata, readers can apply predicate pushdown against the transform (a query WHERE event_time >= '2024-01-01' automatically translates to partition pruning against year(event_time) >= 2024 OR (year = 2024 AND month >= 1), even when the table uses month-level partitioning).
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.