Headless BI
A guide to Headless BI, the architectural pattern that decouples the semantic metric definition layer from the presentation layer, allowing consistent business logic to be consumed via API by any downstream application or tool.
Decoupling the Brain from the Face
In a traditional Business Intelligence (BI) tool like Tableau or Power BI, the “brain” and the “face” are tightly coupled. The tool acts as the “brain” by storing the semantic definitions of metrics (e.g., calculating “Net Revenue” by subtracting returns and taxes from gross sales), and it acts as the “face” by rendering the charts and dashboards.
This monolithic approach creates a massive problem when an organization wants to use that “Net Revenue” metric anywhere outside of that specific BI tool. If a developer wants to show Net Revenue in a custom React web application, or if a data scientist wants to use Net Revenue as a feature in a machine learning model, they cannot easily extract that logic from Tableau. They have to rewrite the SQL logic from scratch in their own application, leading to the classic problem of inconsistent metrics across the business.
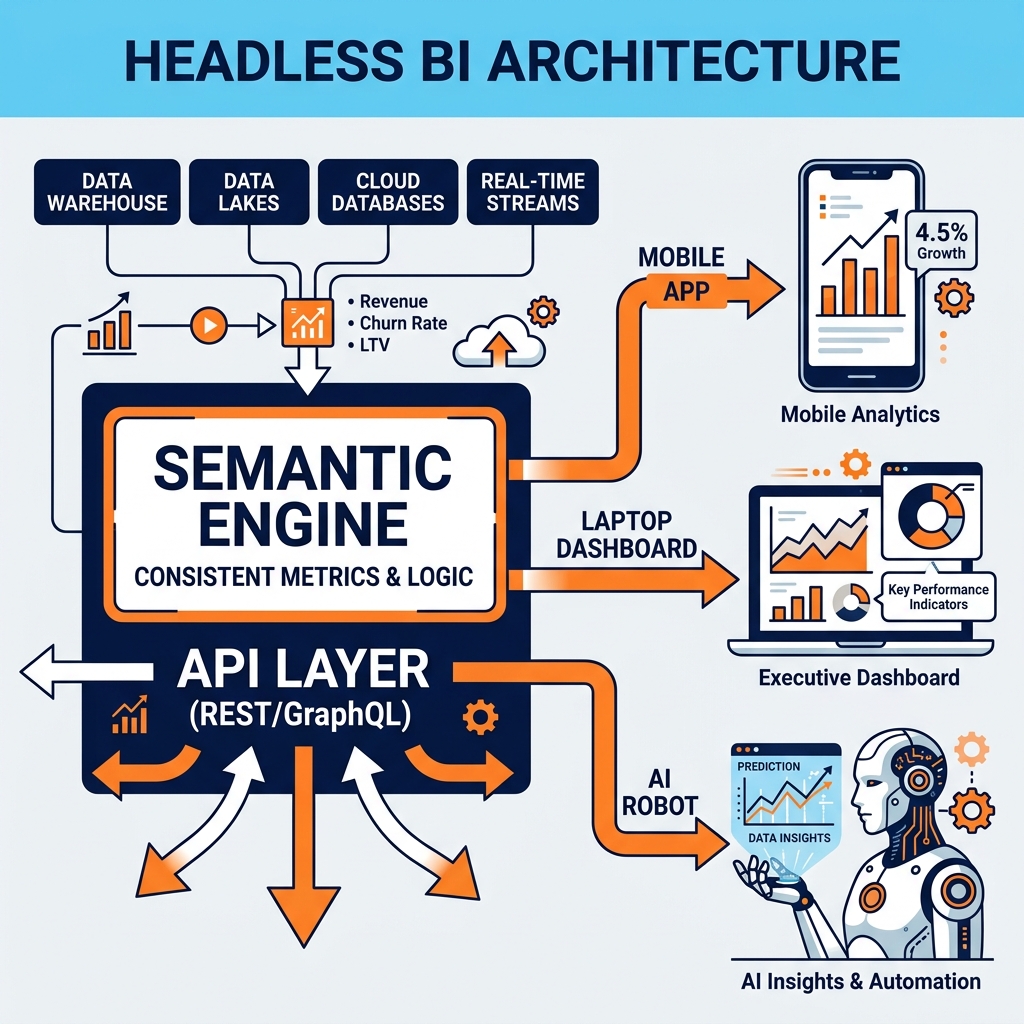
Headless BI (often used synonymously with a Metric Store) solves this by decoupling the brain from the face. It extracts the semantic metric definitions out of the BI tools and centralizes them in a standalone, “headless” API layer that sits directly on top of the data platform.
The Headless BI Architecture
A Headless BI platform (like Cube, Semantic Layer by dbt, or Malloy) operates as a pure semantic engine without a built-in visualization interface.
Data engineers write code (usually YAML or a specialized semantic language) within the Headless BI platform to define the entities, dimensions, measures, and complex business logic metrics.
Once defined, the Headless BI platform exposes these metrics via a suite of APIs: REST APIs for web applications, GraphQL for mobile apps, and standard SQL interfaces (JDBC/ODBC) for traditional BI tools.
When a downstream application wants data, it doesn’t send a raw SQL query. It sends an API request: “Give me Net Revenue, grouped by Region, for Q3.” The Headless BI engine receives the request, translates it into the highly optimized, dialect-specific SQL required by the underlying data warehouse or lakehouse (e.g., Dremio or Snowflake), executes the query, and returns the result to the application.
Enabling Data as a Product
Headless BI is the technical enabler for treating Data as a Product. By providing a clean, version-controlled, API-driven interface to the organization’s metrics, Headless BI allows data teams to guarantee the accuracy and consistency of the data they serve.
If the CFO changes the definition of “Net Revenue” to exclude a specific new tax category, the data engineer updates the definition once in the Headless BI layer. Instantly, the Tableau dashboard, the custom web application, and the executive Slack bot all begin reporting the new, correct number, because they all pull from the same headless brain. This architectural pattern is essential for organizations scaling data access to hundreds of diverse applications and AI agents.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.