Data Skewness
A guide to data skewness in distributed data engineering, the performance-killing imbalance where some partitions or tasks process dramatically more data than others, and how to detect and address it.
When Parallelism Breaks Down
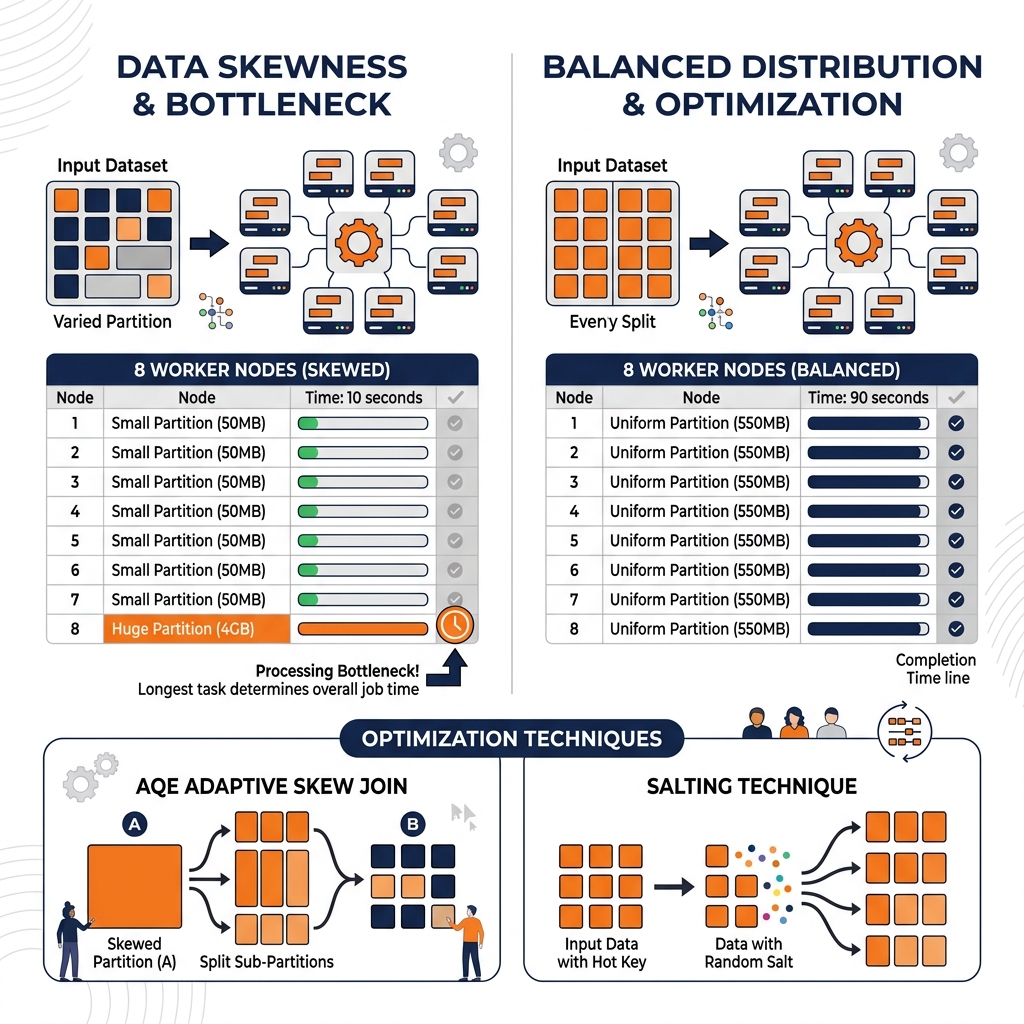
Distributed query engines and processing frameworks achieve their performance advantage through parallelism: dividing large datasets into partitions that are processed simultaneously by many worker nodes. When this parallelism works correctly, doubling the number of workers roughly halves the job execution time. When data skewness is present, parallelism breaks down: some workers process a small partition and finish in seconds, while one unlucky worker receives a massive partition and becomes the bottleneck that determines the entire job’s duration.
Data skewness is the condition where data is unevenly distributed across partitions, causing some partitions to be dramatically larger than others. In a distributed join between a customer table and a transaction table, if 80% of all transactions belong to 5 enterprise customers, any join strategy that partitions by customer ID will result in 5 workers each processing 16% of the total transaction data while hundreds of other workers process tiny micro-partitions. The 5 overloaded workers determine the join’s completion time; the hundreds of other workers sit idle waiting.
Skewness manifests in different forms. Partition skewness occurs when data is partitioned by a column with highly unequal value distribution, such as partitioning by customer tier when 90% of rows are ‘Consumer’ tier and 10% are ‘Enterprise’. Join skewness occurs when joining on a column where the key distribution in one table is highly concentrated. Aggregation skewness occurs when grouping by a low-cardinality column produces a small number of very large groups that must be reduced by a single reducer.
Detecting Skewness
Skewness is detected through examining task-level timing metrics in the Spark UI or Flink Dashboard. If the median task duration is 5 seconds but the maximum task duration is 5 minutes, severe skewness is present. The ratio of max to median task duration is the primary skewness indicator.
In Apache Iceberg tables, skewness at the file level is visible through the metadata layer: manifests that list files with dramatically different sizes indicate skew. Files produced by streaming pipelines that write per-event or per-micro-batch before compaction are uniformly small (under-sized), but after compaction, if partition-level skew exists, some partitions will have many more large files than others.
Addressing Skewness
Salting: For join skewness, salting artificially distributes skewed keys across multiple partitions by appending a random suffix (0-N) to the hot key before joining. The join is performed on the salted key, distributing the skewed key’s records across N partitions. After the join, the records are aggregated by the original unsalted key. Salting introduces complexity in query logic but is the most reliable solution for severe join skewness.
Spark AQE (Adaptive Query Execution): Spark’s AQE feature automatically detects skewed partitions at runtime and splits them into smaller sub-partitions before executing the join, without requiring any manual salting or query rewrite. AQE skew join optimization is the preferred first approach for Spark workloads before resorting to manual salting.
Improved partitioning: For partition skewness, the long-term solution is to choose partition columns with more uniform distribution. For Iceberg tables, partition evolution enables changing the partition strategy without data rewriting, allowing gradual migration to a better-distributed partition column.
Pre-aggregation: For aggregation skewness, pushing aggregations into the map phase before the reduce phase (two-stage aggregation) distributes the reduction work across many workers rather than concentrating it in a few reducers.
Dremio’s distributed query engine applies its own optimizer-level handling for skew-prone operations, using adaptive work distribution to rebalance tasks when runtime statistics reveal imbalance, providing automatic skewness mitigation without requiring query-level intervention.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.