Data Reliability
A guide to data reliability, the engineering discipline focused on ensuring data pipelines consistently deliver accurate, fresh, and complete data to consumers, treating data downtime with the same urgency as software application downtime.
Treating Data Downtime Like Application Downtime
When a company’s e-commerce website goes down, alerts fire immediately, engineers are paged, and the incident is resolved with maximum urgency because the business impact is visible and immediate. When a silent failure in a data pipeline causes the executive revenue dashboard to underreport sales by 15%, the issue often goes unnoticed for weeks until a business user questions the numbers. By then, decisions have been made based on flawed data, and trust in the data team is broken.
Data reliability is the engineering discipline focused on preventing, detecting, and resolving “data downtime” - periods where data is missing, inaccurate, stale, or otherwise unfit for consumption. It treats data pipelines as production software systems that require Service Level Agreements (SLAs), rigorous testing, and continuous monitoring.
The Pillars of Data Reliability
Data reliability engineering involves establishing automated checks across several dimensions of data health:
Freshness: Is the data up to date? A reliable pipeline monitors the maximum timestamp in target tables or the lag in streaming ingestion. If the hourly sales pipeline hasn’t updated the Gold table in 3 hours, a freshness alert fires before business users notice the stale dashboard.
Volume: Did the expected amount of data arrive? A reliable pipeline monitors row counts for anomalies. If a daily ingestion job normally processes 100,000 rows but suddenly processes 500 rows, a volume alert fires, indicating a likely upstream source system failure or API change.
Schema Stability: Has the structure of the data changed? A reliable pipeline detects schema drift. If an upstream SaaS application drops a column or changes a field type from Integer to String without warning, schema monitoring catches the change before it breaks downstream transformations.
Data Quality (Distribution): Does the data make sense? A reliable pipeline monitors the statistical distribution of column values. If the null rate of a critical user_id column jumps from 0% to 25%, or if an age column suddenly contains negative numbers, quality alerts trigger an investigation.
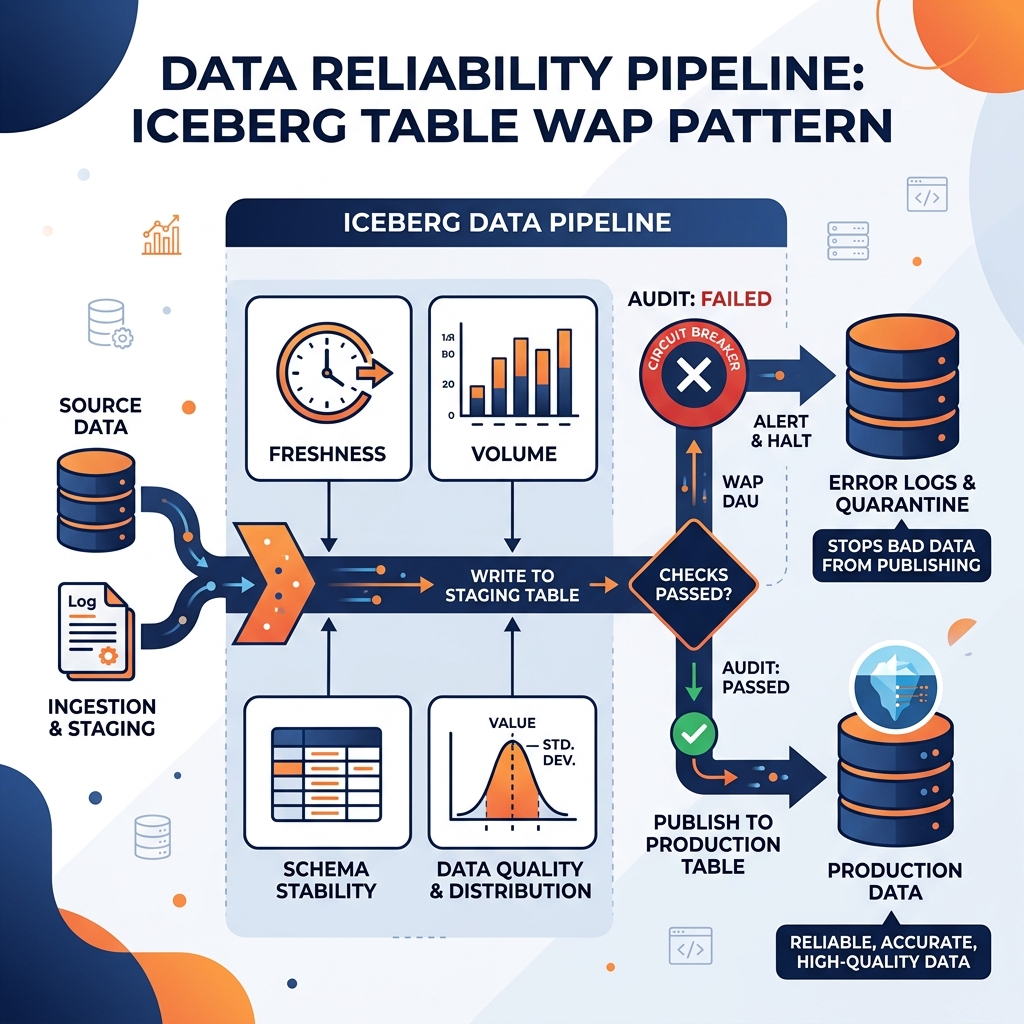
Implementing Reliability in the Lakehouse
Data reliability is implemented through a combination of pipeline testing (DataOps) and data observability tools.
Pre-computation Testing (dbt tests): Before a pipeline step writes data to the final analytical table, it runs assertions (dbt not_null, unique, accepted_values tests). If the tests fail, the pipeline run halts, preventing bad data from polluting the Gold layer. This is the data equivalent of software unit tests.
Post-computation Monitoring (Observability): Tools like Monte Carlo or Anomalo connect directly to the Iceberg tables in the lakehouse and continuously monitor the data at rest using machine learning models to detect anomalies in volume, freshness, and distribution without requiring manual threshold configuration by engineers.
Circuit Breakers and the WAP Pattern: The Write-Audit-Publish (WAP) pattern enabled by Iceberg table branching is the ultimate reliability mechanism. Data is written to an invisible branch, reliability tests (audits) are executed against the branch, and the branch is only published to the main table if the tests pass. If the data is unreliable, the main table is never updated, protecting consumers from data downtime.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.