Columnar Storage vs. Row-Oriented Storage
A comprehensive guide to the architectural difference between columnar and row-oriented storage, and why columnar storage is the foundation of high-performance analytical data platforms.
Two Fundamentally Different Storage Philosophies
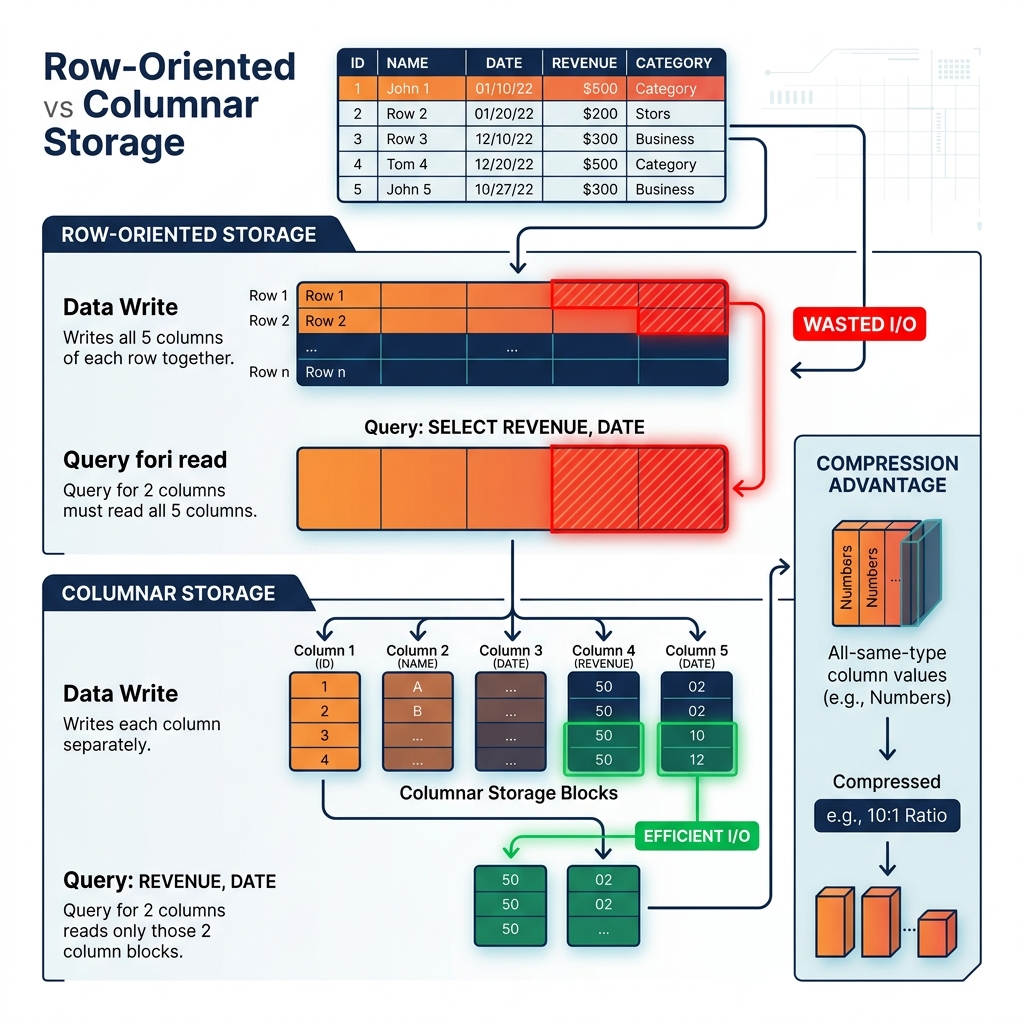
Every data storage system must answer a deceptively simple question: in what order should the data be physically written to disk? For a table with one billion rows and one hundred columns, two radically different orderings are possible. Row-oriented storage writes all one hundred columns of row 1, then all one hundred columns of row 2, then row 3, continuing until all one billion rows are written. Columnar storage writes all one billion values of column 1, then all one billion values of column 2, then column 3, writing every value for each column before moving to the next.
This seemingly technical choice has profound consequences for every aspect of storage performance: compression ratios, query speed, write patterns, and the classes of workloads each approach serves well. Understanding this distinction is foundational to understanding why Apache Parquet, Apache ORC, and the entire modern analytical storage stack are built on columnar principles.
Why Row-Oriented Storage Serves OLTP
Row-oriented storage (the default for relational databases like PostgreSQL, MySQL, and Oracle) organizes data so that all columns of a single row are physically adjacent in storage. When an application needs to read or write a complete record, such as retrieving all details of a specific customer or inserting a new order, the storage system reads or writes a single contiguous block of data that contains the entire row. This access pattern aligns naturally with OLTP (Online Transaction Processing) workloads: single-record lookups, inserts, and updates.
The indexed B-tree structures of row-oriented databases allow rapid single-row lookups by primary key or indexed column, making row-oriented storage ideal for transactional databases that handle thousands of concurrent single-row operations per second.
Why Columnar Storage Serves Analytics
Analytical queries operate on fundamentally different access patterns than OLTP queries. An analytical query computing average revenue by product category across one billion sales transactions needs to read the revenue column and the product_category column, nothing else. In a row-oriented layout, accessing those two columns requires reading every row’s entire 100-column data block, wasting I/O on 98 irrelevant columns. In a columnar layout, only the revenue and product_category column blocks need to be read from disk, skipping 98% of the stored data entirely.
This column selectivity advantage is the primary performance benefit of columnar storage for analytical workloads, and it compounds with table width. For a table with 200 columns, an analytical query reading 5 columns wastes 97.5% of I/O in row-oriented storage but zero excess I/O in columnar storage.
Compression: The Columnar Advantage
Columnar storage achieves dramatically higher compression ratios than row-oriented storage for a critical reason: within a column, all values share the same data type and often exhibit high similarity or repetition. A product_category column might contain 1 billion values drawn from only 50 distinct categories. In columnar storage, all 1 billion values of the same data type are stored contiguously, allowing highly efficient compression algorithms to exploit the repetition. Dictionary encoding represents each distinct category as a small integer, reducing 1 billion string values to 1 billion compact integer codes plus a 50-entry dictionary. The entire column might compress to 2-5GB from an uncompressed size of 80GB.
In row-oriented storage, each row interleaves the product_category string value between 99 other columns of different types, completely defeating compression algorithms that need repeated patterns of the same type to achieve high compression ratios.
Apache Parquet combines multiple encoding strategies (dictionary encoding for low-cardinality columns, delta encoding for monotonically increasing integers, run-length encoding for repetitive values) to achieve compression ratios of 3:1 to 10:1 on typical analytical datasets, dramatically reducing storage costs and I/O bandwidth requirements compared to row-oriented formats.
Columnar Storage in the Modern Lakehouse
Apache Parquet and Apache ORC are the two dominant columnar file formats in the modern data engineering ecosystem, both providing excellent analytical query performance and high compression. Apache Iceberg uses Parquet as its default data file format, combining Parquet’s columnar storage efficiency with Iceberg’s ACID transaction semantics and metadata management.
Dremio’s query engine is built natively around the columnar Arrow in-memory format, which aligns with Parquet’s on-disk columnar layout. When Dremio reads Parquet files from an Iceberg table, the Parquet decoder produces Arrow columnar buffers directly from the columnar Parquet data, with minimal format conversion overhead. This Parquet-to-Arrow alignment is a core architectural advantage that enables Dremio to deliver interactive analytical query performance on cloud object storage.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.