Backfilling
A guide to backfilling in data engineering, the essential process of reprocessing historical data using new pipeline logic to ensure consistency across the entire dataset after a bug fix or feature addition.
Rewriting History
In software engineering, when you push a bug fix to production, the fix applies to all future user interactions. In data engineering, fixing a bug is only half the battle. If a bug in a dbt model caused the “revenue” column to be calculated incorrectly for the last six months, pushing the fix only corrects the data moving forward starting tomorrow. The last six months of historical data remain corrupted.
Backfilling is the process of retroactively running new or updated data pipeline logic against historical data. It is how data teams “rewrite history” to ensure consistency across the entire dataset.
Backfilling is required in several common scenarios:
- Bug Fixes: Correcting historical data that was processed with flawed logic.
- New Features: When a data scientist creates a new predictive feature (e.g.,
days_since_last_purchase), the business needs that feature calculated not just for today’s users, but for all users over the past year to train the machine learning model. - Adding New Data Sources: If the company acquires a competitor, the competitor’s last five years of sales data must be backfilled into the central data lakehouse to provide a unified historical view.
The Engineering Challenge of Backfilling
Backfilling is notoriously difficult and is a major source of data engineering pain. A pipeline that easily handles 10 gigabytes of daily incremental data might collapse if asked to process 5 terabytes of historical data in a single run.
Idempotency is Mandatory: If a pipeline is not strictly idempotent (safe to run multiple times), a backfill will create massive duplication. The pipeline must be designed to explicitly overwrite or MERGE the specific historical partitions it is recalculating without affecting adjacent data.
Orchestration Complexity: In tools like Apache Airflow, data engineers often write specific “Catchup” DAGs or leverage Airflow’s built-in backfill CLI commands to sequentially run the daily pipeline for every day in the past year. This requires the pipeline to be parameterized by execution date so that the logic knows which specific historical day it is currently processing.
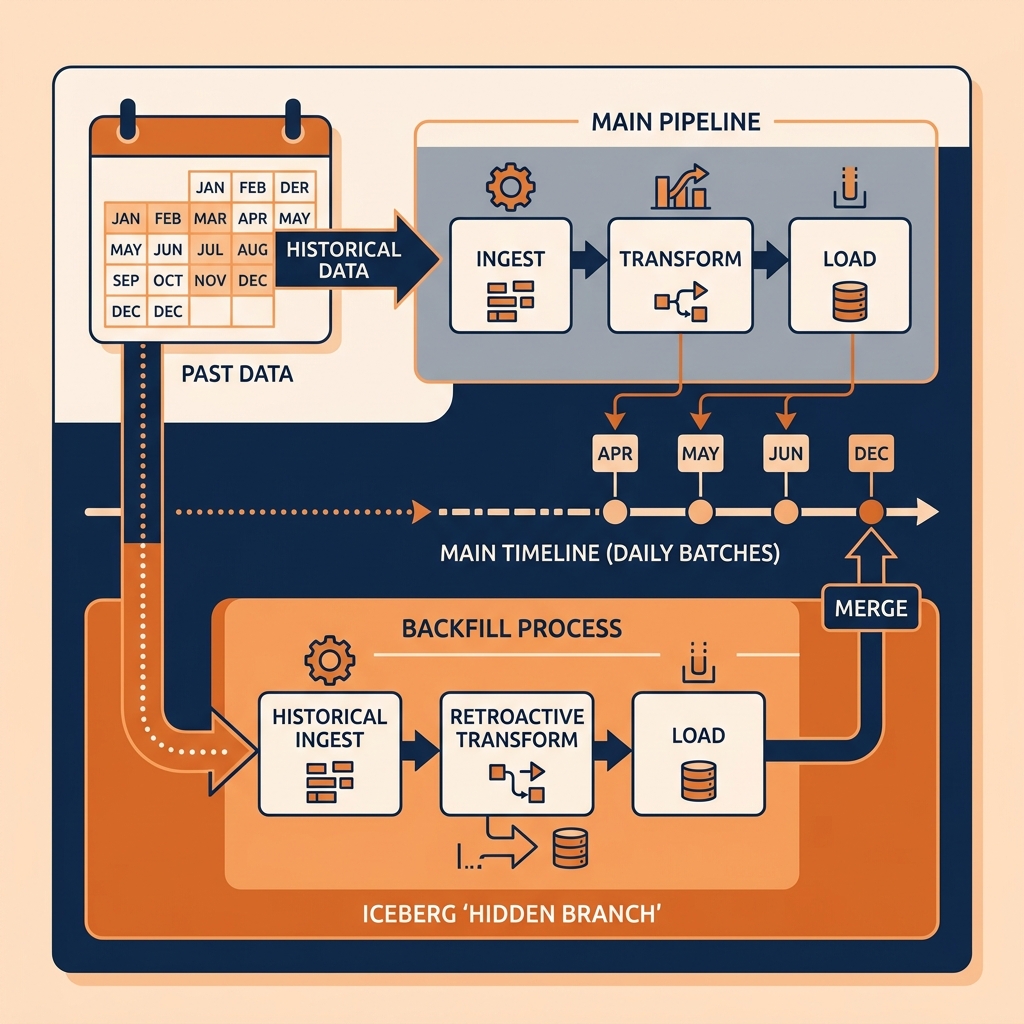
Backfilling in the Iceberg Lakehouse
Apache Iceberg makes backfilling significantly safer and more efficient.
Because Iceberg supports hidden branching (the Write-Audit-Publish pattern), a massive 5-year historical backfill can be executed entirely on a background branch. The engineering team can run the heavy compute job, audit the backfilled data to ensure the new revenue logic is correct, and then atomically merge the branch into the main table.
This means the live production dashboards never experience downtime, locking, or the risk of exposing half-finished backfill data to business executives. Furthermore, if the backfill logic is flawed, the branch is simply dropped, protecting the main table from corruption.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.