Z-Ordering and Data Skipping
A guide to Z-ordering and data skipping in data lakehouses, the file-level data organization techniques that cluster related records together in Parquet files to enable dramatic I/O reduction for multi-column filter queries.
The Multi-Dimensional Data Locality Problem
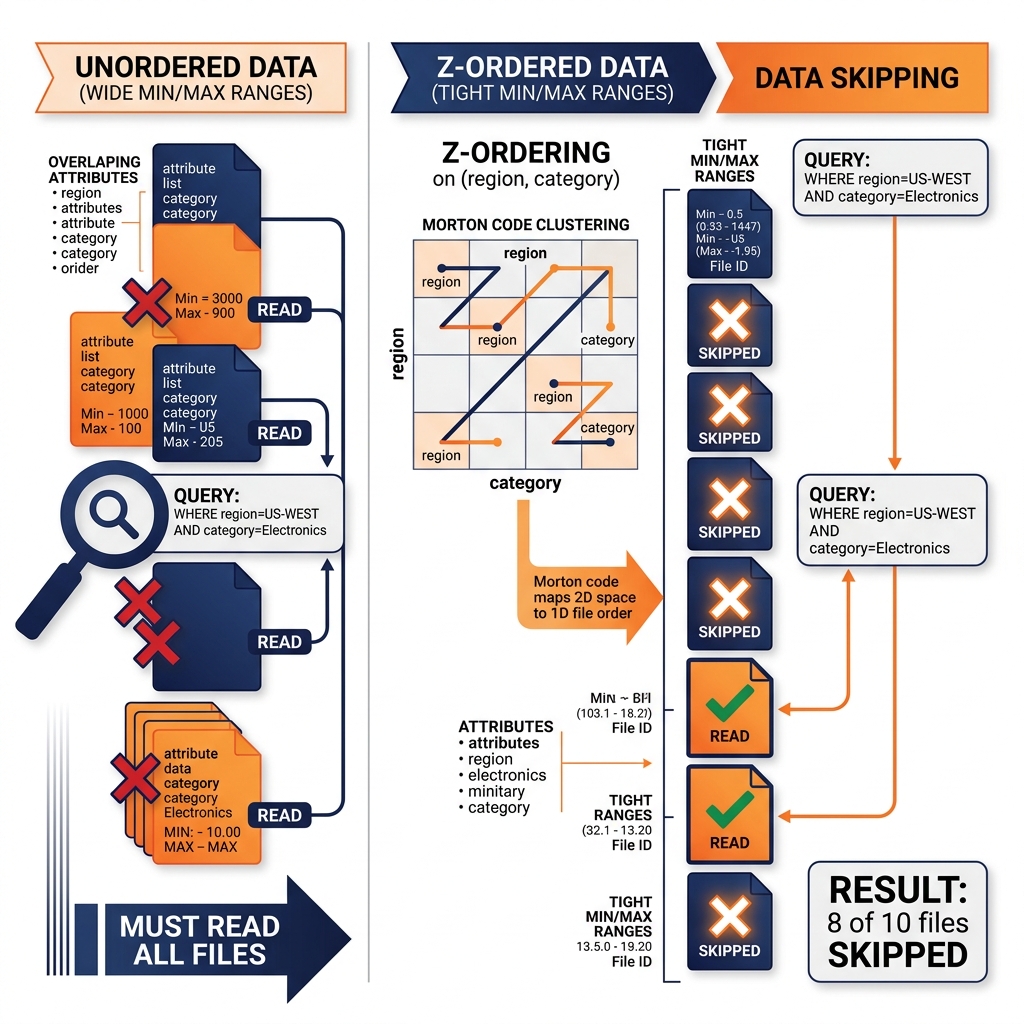
Partitioning organizes data files by the values of partition columns, enabling partition pruning to eliminate entire files based on a single column’s filter value. This works excellently for queries that filter on the partition column. But analytical queries frequently filter on non-partition columns or combinations of multiple columns. A query filtering WHERE region = 'US-WEST' AND product_category = 'Electronics' AND price > 500 benefits from partition pruning if the table is partitioned by region, but the product_category and price filters still require scanning all data files within the US-WEST partition to find matching rows.
The theoretical ideal is that all records matching a particular combination of column values are physically co-located in the same few Parquet files, so that queries filtering on those values can read only the relevant files. Achieving this data locality for multiple columns simultaneously requires a multidimensional space-filling curve: a mapping from multiple column value combinations to file positions that preserves proximity in multi-dimensional space as proximity in the linear file sequence.
Z-ordering (also called Z-curve ordering or Morton code ordering) is the most widely adopted space-filling curve technique for data lake file organization. Z-ordering maps multi-dimensional column value combinations to a single one-dimensional index using the Morton code function, then sorts data files by this one-dimensional index. The mathematical property of the Z-curve is that records with similar values across multiple dimensions tend to receive similar Z-order index values and therefore end up in adjacent files. When a query filters on any combination of the Z-ordered columns, the query engine can use file-level column statistics (min/max ranges) to identify which files cannot contain matching records and skip them entirely.
How Z-Ordering Reduces I/O
Z-ordering is applied through a rewrite operation (in Spark, Iceberg’s CALL rewrite_data_files with strategy sort and sort columns). The rewrite reads all data files in the affected table or partition, sorts the records by the Z-curve index computed from the specified columns, and writes new, sorted Parquet files. The new files have tight min/max ranges for the Z-ordered columns: because records with similar multi-dimensional values are co-located, each file contains records that fall within a narrow range of each Z-ordered column’s values.
When Dremio or any query engine reads file-level statistics (stored in Iceberg manifests), it evaluates whether the file’s min/max range for each filtered column can potentially contain matching records. If the query filter value falls outside a file’s min-max range for any filtered column, that file is skipped entirely without reading a single byte of data. This data skipping is the mechanism that translates Z-ordering’s data locality into query performance improvement.
Liquid Clustering: Iceberg’s Evolution
Apache Iceberg introduced Liquid Clustering as an alternative to Z-ordering that addresses some of Z-ordering’s limitations. Z-ordering requires a full rewrite of all affected data files each time it is applied, which is expensive for large tables. Liquid Clustering applies clustering incrementally, clustering only newly written files and the least-clustered existing files in each maintenance operation. Over successive operations, the entire table gradually achieves a well-clustered layout without ever requiring a full table rewrite.
Liquid Clustering also adapts automatically to query patterns. If the access patterns for a table change over time (analysts begin filtering on a new set of columns), the clustering columns can be updated and future clustering operations will cluster new data according to the new columns while existing data retains its old clustering.
Dremio leverages file-level statistics from Iceberg manifests to implement data skipping automatically. When Z-ordered or Liquid Clustered Iceberg tables are queried through Dremio, the query planner reads the per-file statistics from the manifest and eliminates files that cannot contain matching rows before any data is read, combining Dremio’s performance optimizations with Iceberg’s structural data organization.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.