Micro-batching
A guide to micro-batching, the hybrid data processing architectural pattern that achieves near-real-time streaming performance by rapidly executing tiny, high-frequency batch jobs, forming the foundation of systems like Spark Streaming.
The Illusion of Continuous Streams
In the world of data processing, there are two fundamental paradigms: Batch and Streaming.
Batch processing (like traditional Hadoop or nightly dbt runs) processes massive chunks of static data at scheduled intervals (e.g., daily). It is highly efficient for complex aggregations but suffers from high latency; the data is always hours old.
True continuous streaming (like Apache Flink) processes every single event individually the millisecond it arrives. It offers the lowest possible latency but is complex to manage, especially when dealing with distributed state and fault tolerance.
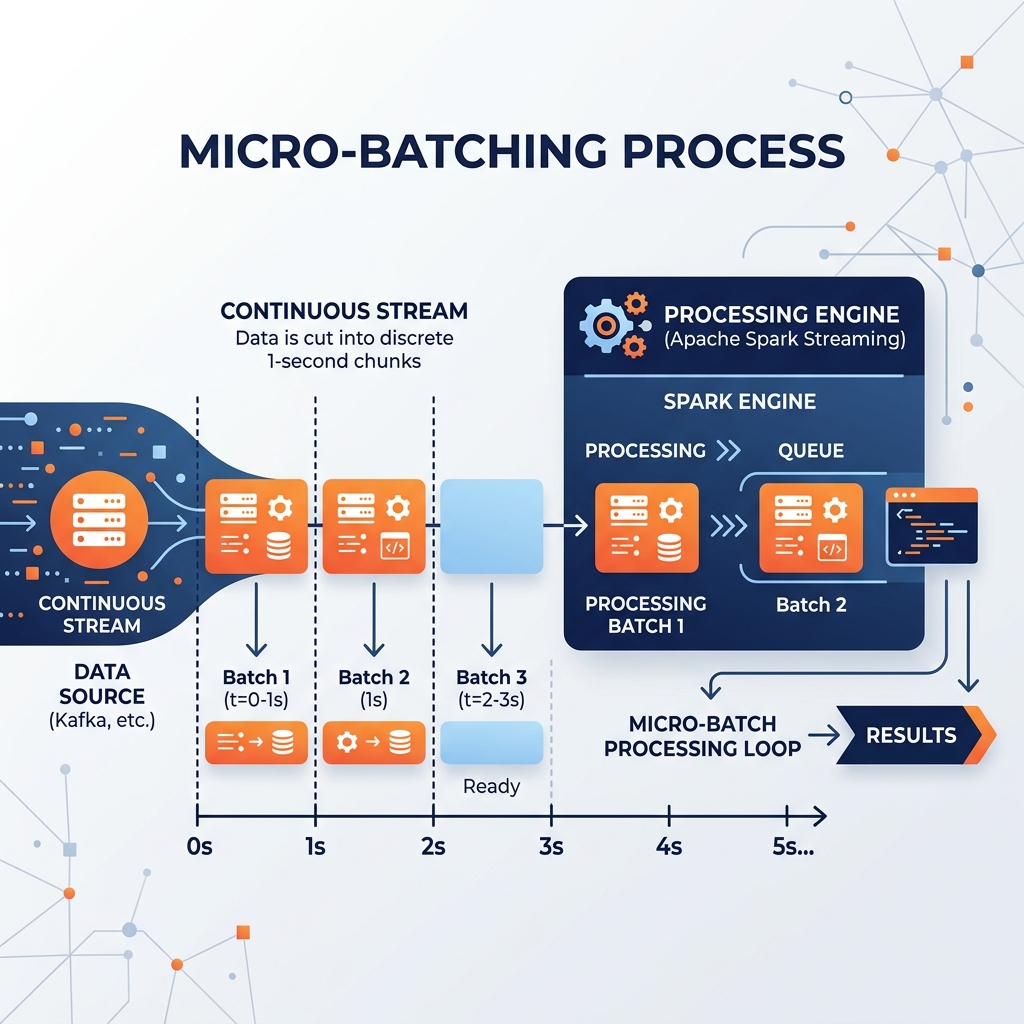
Micro-batching is the pragmatic architectural bridge between the two. Instead of processing data once a day, or processing it event-by-event, a micro-batching engine gathers incoming data into tiny chunks (e.g., 500 milliseconds, 1 second, or 5 seconds of data) and processes each chunk as a miniature, independent batch job. To the end-user looking at a dashboard updating every 2 seconds, it looks like true continuous streaming, but under the hood, the system is just running thousands of tiny batch jobs per hour.
The Micro-batching Architecture
Apache Spark Streaming (specifically Structured Streaming) is the most famous implementation of the micro-batching architecture.
When a Spark Structured Streaming job connects to a Kafka topic, it doesn’t process events one by one. The architecture works like this:
- The engine checks the Kafka topic and sees 10,000 new messages have arrived in the last second.
- It defines those 10,000 messages as “Batch 1.”
- It spins up the massive distributed processing power of the Spark engine to execute a standard SQL transformation against Batch 1.
- It writes the result to the destination (e.g., an Apache Iceberg table).
- The moment Batch 1 finishes, it immediately triggers “Batch 2” for whatever data has arrived since.
Benefits and Trade-offs
The primary benefit of micro-batching is that it unifies the programming model. In Spark, the exact same SQL code or DataFrame API logic used to process a massive 10-terabyte nightly batch job can be used to process a 1-second micro-batch. The engineer doesn’t have to learn a separate streaming API. Furthermore, fault tolerance is much simpler than continuous streaming; if a micro-batch fails, the engine simply re-runs that specific 1-second batch.
The trade-off is latency. A micro-batching system can rarely achieve sub-100-millisecond latency. If a high-frequency trading application requires a reaction time of 5 milliseconds to a stock price change, micro-batching is too slow; the system must wait for the batch window to close before processing begins.
However, for 95% of enterprise use cases - updating a live inventory dashboard, calculating a rolling 5-minute average for an ML model, or near-real-time fraud detection - the 1-second latency of a micro-batching architecture is indistinguishable from continuous streaming, while offering superior throughput and operational simplicity.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.