Lakehouse Concurrency
A guide to lakehouse concurrency, the mechanisms that allow thousands of users and pipelines to read and write data simultaneously to object storage without locking, corruption, or reading partial data.
Managing the Chaos of Simultaneous Access
In a modern enterprise, the data platform is a hyper-active intersection. At any given second, an automated streaming pipeline might be INSERTing new web clicks, a dbt batch job might be UPDATEing customer records, a data privacy script might be DELETEing a user’s data for GDPR compliance, and 500 business analysts might be running SELECT queries to render their morning dashboards.
If all these operations hit the same raw CSV or Parquet files on cloud object storage simultaneously, chaos ensues. A BI query might read a file while a pipeline is halfway through writing it, resulting in a dashboard showing incomplete, corrupted data.
Lakehouse concurrency is the set of architectural mechanisms that prevent this chaos, ensuring that thousands of simultaneous readers and writers can access the data lake safely, achieving the ACID (Atomicity, Consistency, Isolation, Durability) guarantees traditionally reserved for monolithic relational databases.
Optimistic Concurrency Control (OCC)
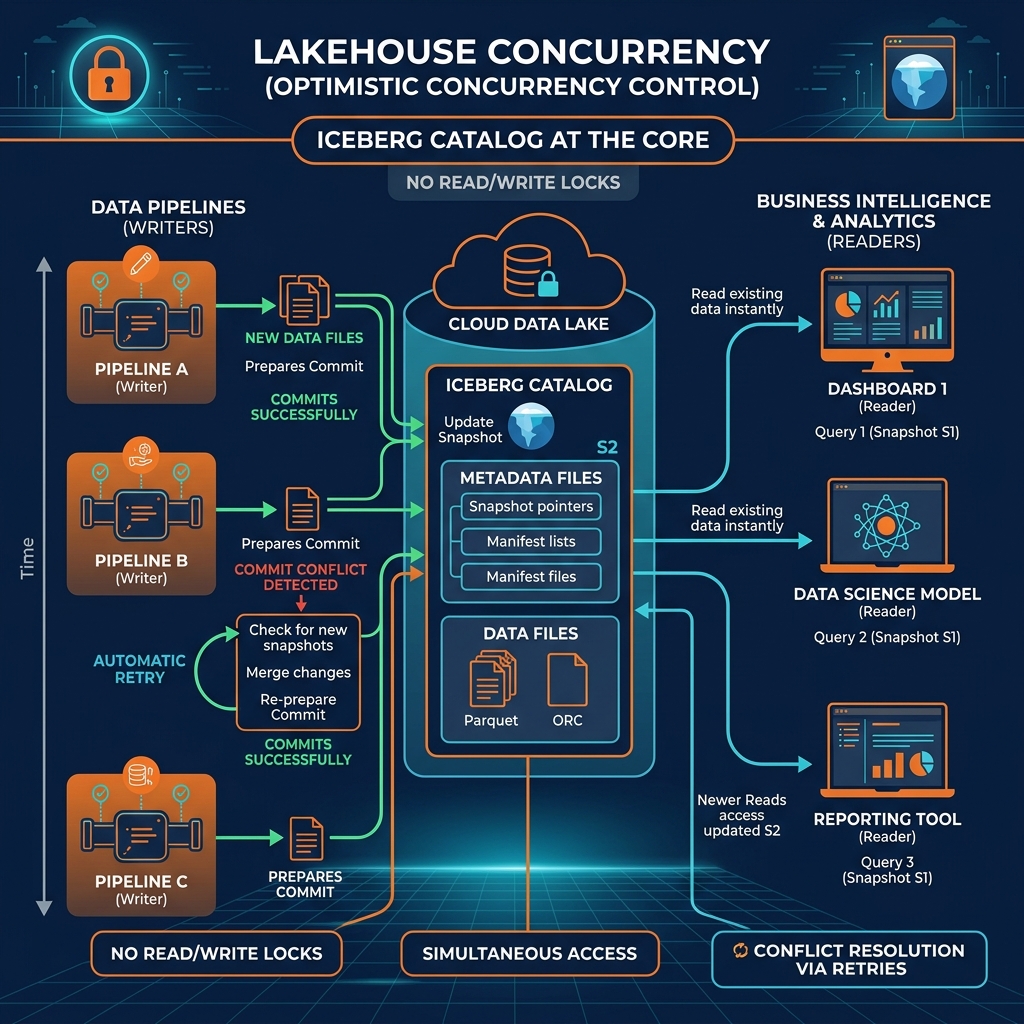
Apache Iceberg achieves high concurrency through a mechanism called Optimistic Concurrency Control (OCC).
Unlike traditional databases that use “Pessimistic Concurrency” (where a writer places a strict lock on a table, forcing everyone else to wait in line until the write finishes), OCC assumes that conflicts are rare.
When a pipeline wants to update an Iceberg table, it doesn’t lock the table. It reads the current metadata version (e.g., Version 10), does all the heavy computational work to create the new data files, and writes those files to storage.
Only at the very last millisecond, when it is time to commit the changes, does the pipeline check the catalog. If the current version is still Version 10, it safely swaps the pointer to Version 11. The operation is atomic: readers either see the old state or the new state; they never see a partial write.
Handling Conflicts
What happens if another pipeline committed a change a millisecond earlier, updating the catalog to Version 11?
In OCC, the first pipeline’s commit fails. However, Iceberg handles this gracefully. It evaluates what the other pipeline changed. If Pipeline B simply added new files to the table, and Pipeline A was also just adding new files, Iceberg automatically retries the commit, merging both sets of changes to create Version 12.
If the conflict is unresolvable (e.g., Pipeline B deleted a file that Pipeline A was trying to update), Iceberg fails the operation, protecting the integrity of the data. The orchestration tool (like Airflow) then simply retries the job.
Snapshot Isolation for Readers
For the 500 analysts running SELECT queries, Iceberg provides Snapshot Isolation. When an analyst starts a query, the engine locks onto the current snapshot ID (e.g., Version 10). Even if a massive ETL job finishes and commits Version 11 while the analyst’s 5-minute query is still running, the analyst’s query continues to read the data files exactly as they existed at Version 10.
This isolation ensures that read queries are never blocked by writers, writers are never blocked by readers, and dashboards always display a perfectly consistent point-in-time view of the data.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.