Apache Pinot
A guide to Apache Pinot, a real-time, distributed OLAP datastore purpose-built to deliver ultra-low latency analytics across massive, constantly updating event streams for user-facing applications.
Analytics at the Speed of Now
When a company wants to build an internal dashboard for their executives to review yesterday’s sales figures, a traditional cloud data warehouse (like Snowflake) or a Lakehouse (like Dremio) is the perfect architectural choice. These systems are designed to process massive, complex JOIN queries across terabytes of historical data, and waiting 5 seconds for the dashboard to load is perfectly acceptable.
However, if a company wants to build a user-facing dashboard-for example, the “Analytics” tab on LinkedIn that shows a user exactly who viewed their profile in the last 15 minutes, or an Uber Eats dashboard showing a restaurant their live order volume-a traditional data warehouse fails completely.
If millions of external users hit the data warehouse simultaneously, the system will crash under the concurrency load. If it takes 5 seconds for a user’s mobile app to load a simple chart, the user will uninstall the app.
Apache Pinot was created by LinkedIn specifically to solve this problem. It is a real-time, distributed Online Analytical Processing (OLAP) database engineered for site-facing analytics.
How Pinot Achieves Sub-Second Speed
Pinot achieves millisecond latency at massive concurrency by heavily pre-computing and indexing the data before the user even asks the question.
1. Aggressive Indexing: While traditional databases might only use a few B-Tree indexes, Pinot applies aggressive indexing to almost every column. It uses Inverted Indexes (like a search engine) to instantly find specific records, and Star-Tree Indexes (a unique Pinot feature) to pre-aggregate combinations of dimensions on the fly as the data is ingested.
2. Direct Stream Ingestion: Pinot does not wait for a batch ETL job. It connects directly to Apache Kafka. The moment an event (like a profile view) hits the Kafka stream, Pinot ingests it, updates its internal Star-Tree indexes, and makes the data available for querying within milliseconds.
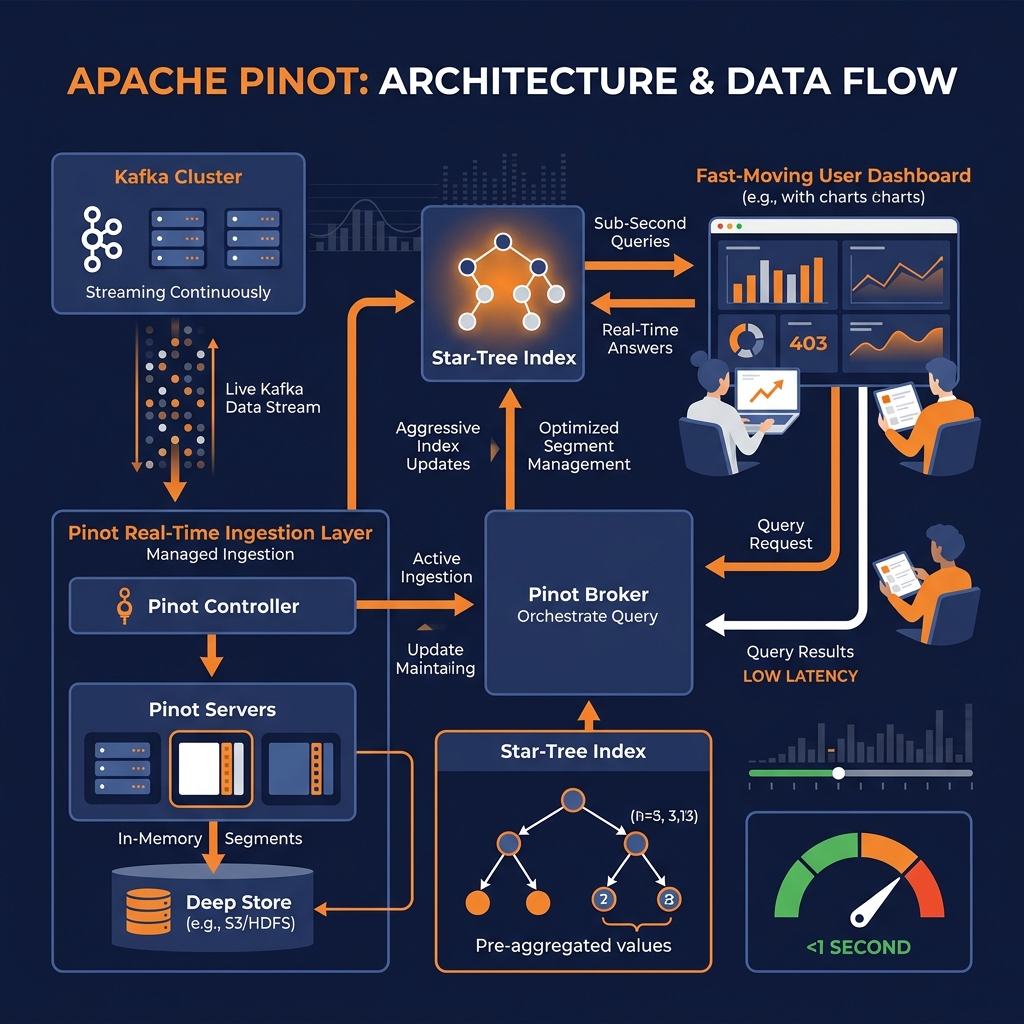
The Trade-Offs of Real-Time OLAP
Pinot is incredibly fast, but it achieves this speed by strictly limiting what you can do with it.
It is not designed for exploratory data science. It struggles with massive, complex JOIN operations across massive tables because joining data on the fly destroys sub-second latency. To use Pinot effectively, data engineers must pre-join and flatten the data streams before they enter Pinot.
Pinot is the specialized “sports car” of the data ecosystem: it can only drive on paved, pre-defined analytical roads (specific dashboards), but it drives on them faster than anything else on earth.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.