Zero-Copy Cloning
A guide to zero-copy cloning, the powerful data lakehouse feature that allows engineers to create instant, functional copies of massive datasets without physically duplicating any of the underlying storage.
Duplicating the Pointers, Not the Bytes
In traditional software engineering, creating a safe “testing” environment is incredibly difficult when dealing with massive data. If a data science team wants to test a destructive new machine learning algorithm on the production transactions table, they cannot run it on live production data.
Historically, the only solution was to physically copy the entire table into a safe sandbox environment. If the table is 100 Terabytes, a physical CREATE TABLE test_transactions AS SELECT * FROM transactions query will take hours to execute and immediately double the company’s cloud storage bill.
Zero-Copy Cloning is the modern architectural solution. It allows data engineers to instantly create a perfectly functional “clone” of a 100-Terabyte table without copying a single byte of physical data on the hard drive, completely eliminating the time delay and the storage cost.
How Metadata Makes It Possible
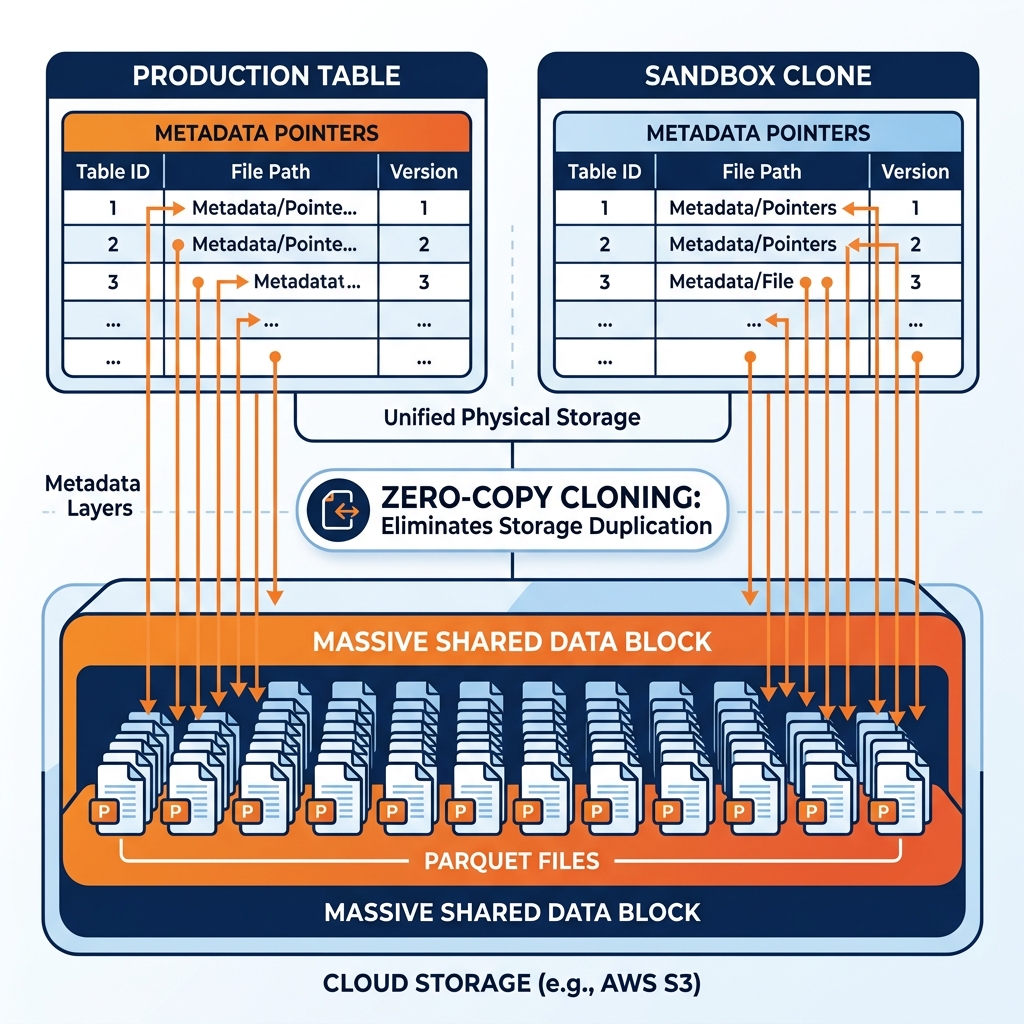
Zero-copy cloning is only possible in systems that strictly decouple metadata from physical storage (like Snowflake, Dremio, and Apache Iceberg).
When you execute a zero-copy clone command on an Iceberg table, the engine does not touch the massive Parquet files sitting on Amazon S3. Instead, the engine creates a brand new metadata file. This new metadata file simply contains pointers to the exact same raw Parquet files as the original table.
To the data scientist querying the clone, it looks and acts like a completely separate table. But beneath the surface, both the production table and the clone table are reading the exact same physical files on S3.
Copy-on-Write (The Divergence)
The true magic of zero-copy cloning happens when you alter the cloned data.
If the data scientist executes a DELETE or UPDATE statement on their safe test clone, the engine does not modify the original shared Parquet files (which would destroy production data). Instead, it uses a mechanism called Copy-on-Write.
The engine writes the new, modified data as brand new Parquet files on S3. It then updates the clone’s metadata pointer to look at the new files, while the production table’s metadata continues pointing safely at the original files. The two tables have diverged. You still only pay storage costs for the tiny fraction of data that was changed, while 99% of the massive dataset remains shared and free.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.