CQRS (Command Query Responsibility Segregation)
A guide to CQRS, the architectural pattern that completely separates the code and databases used for reading data (Queries) from the code and databases used for writing data (Commands) to maximize performance and scalability.
Splitting the Reads and Writes
In a traditional application architecture, the exact same database and the exact same data model are used to insert data (writes) and retrieve data (reads).
For a simple blog, this works perfectly. But for a massive enterprise application like an e-commerce platform, this unified model breaks down. The database schema required for highly optimized, ACID-compliant checkouts (writes) is fundamentally different from the schema required for lightning-fast, highly-filtered product searches (reads). If you try to optimize a single database for both, you end up doing neither well.
CQRS (Command Query Responsibility Segregation) is the architectural pattern that solves this by physically and logically splitting the application in half.
The Two Sides of CQRS
The Command Side (Writes):
This side handles actions that change state (e.g., PlaceOrder, UpdateAddress). It uses a data model highly optimized for transactional integrity. It doesn’t care about making the data easy to search; it only cares about making the write operation fast, atomic, and safe. It often utilizes Event Sourcing, storing the commands as an immutable log.
The Query Side (Reads):
This side handles actions that only fetch data (e.g., GetOrderHistory, SearchProducts). It uses a completely different data model-often a highly denormalized, flattened table in a NoSQL database or a search index like Elasticsearch-optimized purely for sub-millisecond retrieval. It does not contain complex business logic or validation; it simply serves data to the UI.
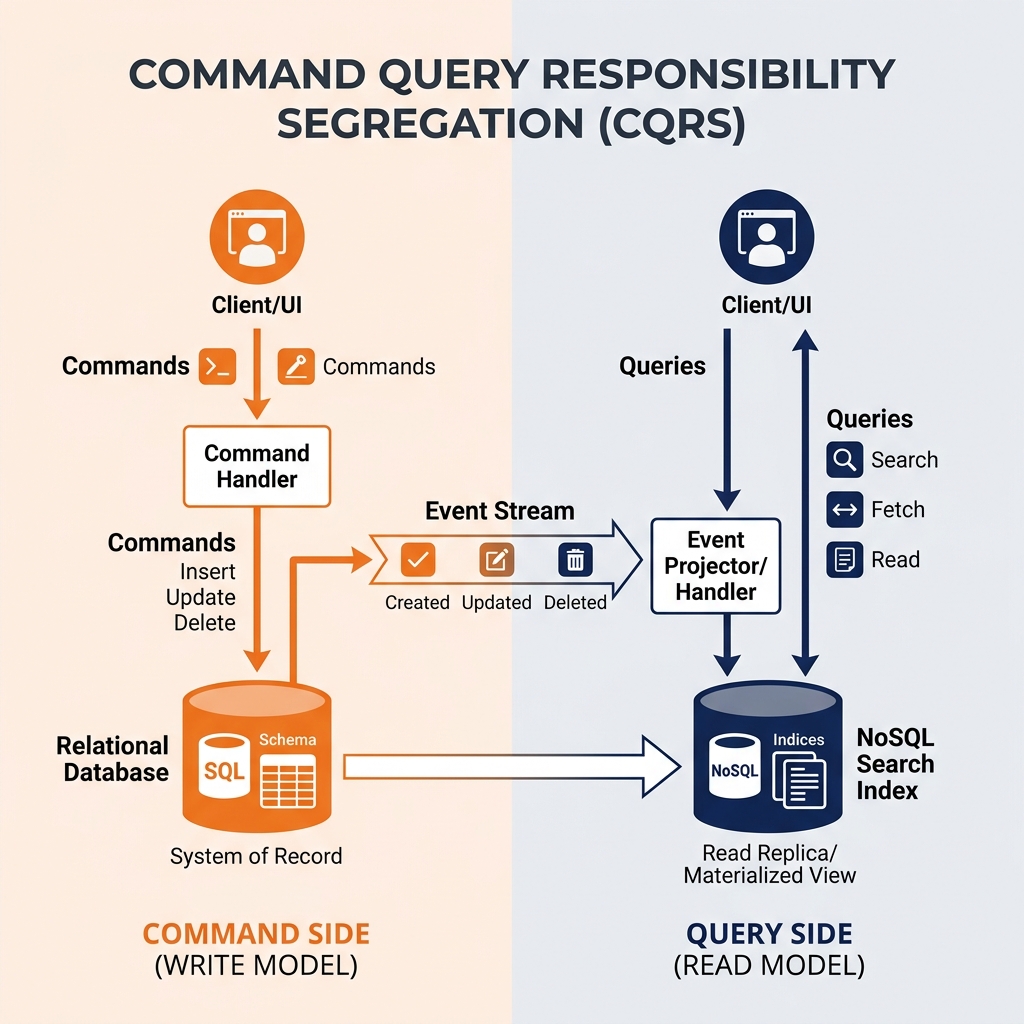
The Synchronization Challenge
Because the reads and writes happen in physically separate databases, the biggest challenge in CQRS is keeping them synchronized.
When a user places an order (Command), that order is written to the Write Database. Instantly, an asynchronous event is fired across a message broker (like Apache Kafka). The Read Database listens for that event, takes the raw order data, denormalizes it, and updates its own separate read-optimized tables.
This synchronization introduces Eventual Consistency. There is a tiny window of time (often a few milliseconds) between when the write occurs and when the read database is updated. If a user places an order and instantly refreshes the page, the order might not appear for a split second. Modern UI development must explicitly handle this eventual consistency to prevent user confusion.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.