Event Sourcing
A guide to event sourcing, the architectural pattern where the state of an application is not stored as a single snapshot, but rather as an immutable sequence of historical events that can be replayed to derive the current state.
Storing the History, Not Just the Present
In a traditional relational database application (like a banking app), when a user deposits $50 into their account, the application runs an UPDATE accounts SET balance = 150 WHERE user_id = 1 query. The database overwrites the old balance ($100) with the new balance ($150). The old state is permanently destroyed.
While simple, this “snapshot” approach loses critical context. If you look at the database tomorrow, you know the balance is $150, but you have no idea how it got there. Was it a $50 deposit? Or a $200 deposit followed by a $50 withdrawal?
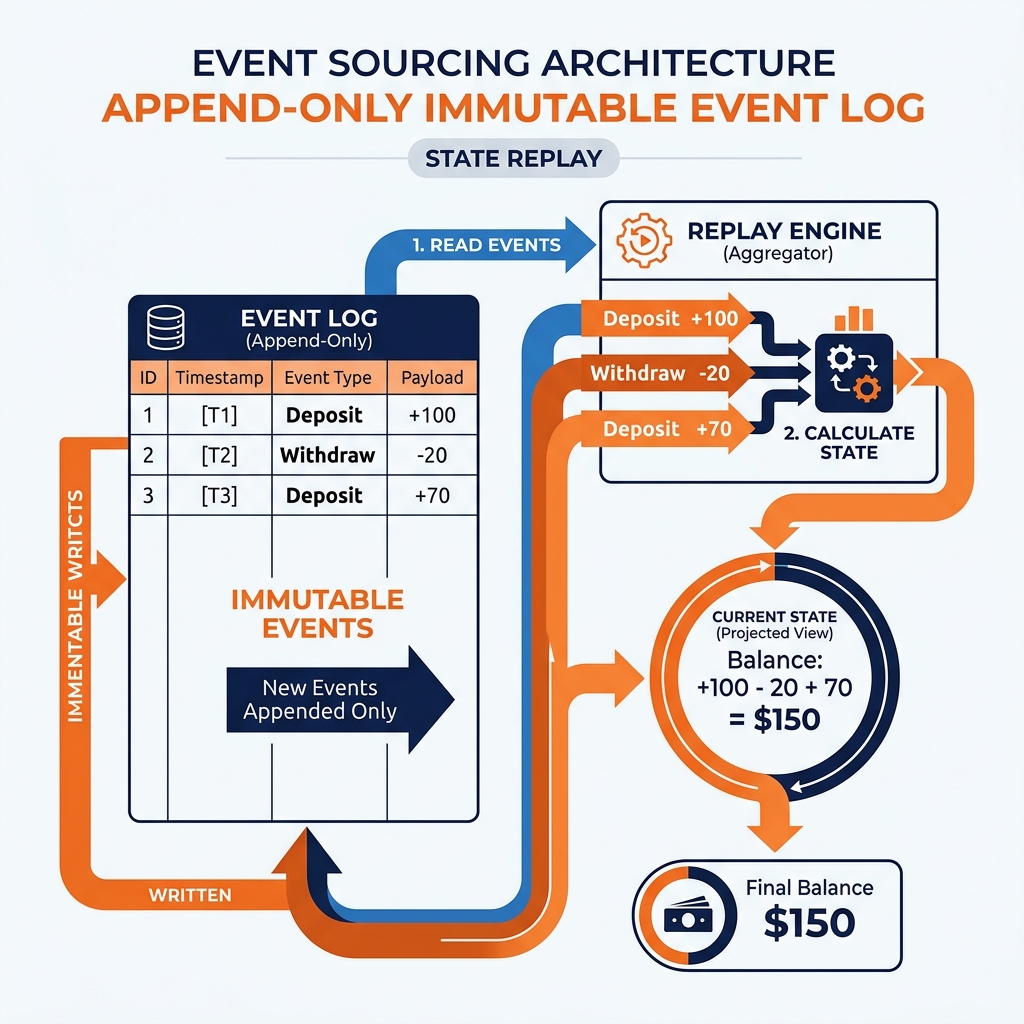
Event Sourcing flips this paradigm. Instead of storing the current state of an entity, the database stores every single action (event) that ever happened to that entity in an immutable, append-only log.
How Event Sourcing Works
In an Event Sourced system, the banking database does not have a “Balance” column. Instead, it has an Events table containing rows like:
AccountCreated: Initial Balance $0Deposited: $100Withdrawn: $20Deposited: $70
To find the user’s current balance, the application fetches all events for that user and mathematically “replays” them from the beginning (0 + 100 - 20 + 70 = 150).
Because replaying 10,000 events every time a user logs in is too slow, systems use Snapshots (calculating the balance once a night and saving it) so they only have to replay the events from today.
Benefits of Event Sourcing
Perfect Auditability: Event sourcing provides a mathematically perfect, tamper-proof audit log. Because events are immutable (you cannot UPDATE an event, you can only append a new CorrectionEvent), regulators can perfectly reconstruct the exact state of the system at any specific millisecond in the past.
Time Travel Debugging: If a bug in the code corrupted data on Tuesday, the engineering team doesn’t have to restore from a massive backup tape. They simply fix the bug, delete the corrupted snapshot, and replay the raw events from Monday night using the fixed code, perfectly reconstructing the correct data.
Event sourcing is heavily paired with Apache Kafka, as Kafka is fundamentally an immutable, append-only event log designed specifically for this exact architectural pattern.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.