Control Plane vs Data Plane
A guide to the architectural separation of the Control Plane (the management and orchestration layer) and the Data Plane (the physical execution and storage layer) in modern distributed data systems.
Managing the Machinery
Modern distributed data platforms-whether they are cloud data warehouses, orchestration tools, or streaming engines-are incredibly complex systems managing thousands of moving parts. To maintain stability, security, and scalability, these systems fundamentally divide their architecture into two distinct layers: the Control Plane and the Data Plane.
This concept originally comes from software-defined networking (SDN) but has become the standard architectural blueprint for modern SaaS data platforms.
The Control Plane (The Brain)
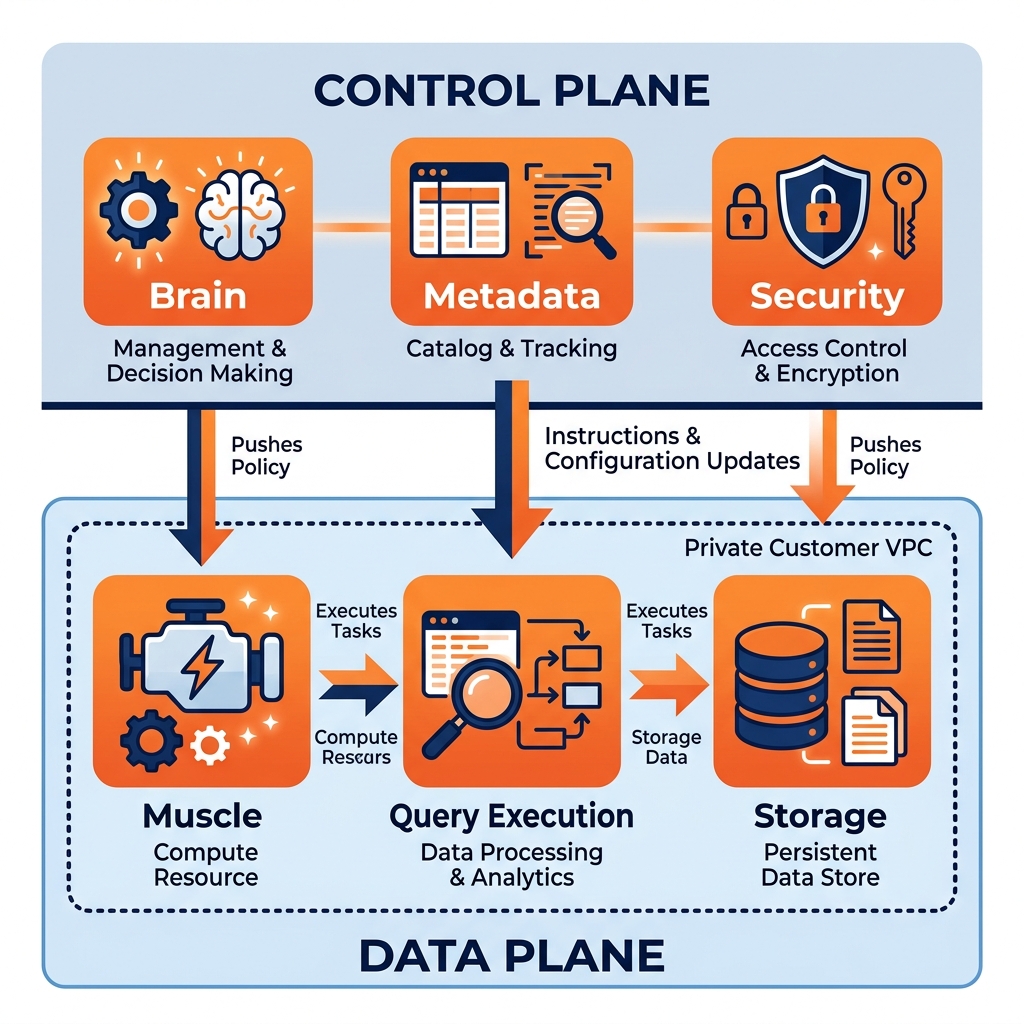
The Control Plane is the centralized management layer. It is the “brain” that makes decisions, manages metadata, enforces security policies, and orchestrates the overall system. However, the Control Plane does not touch the actual payload data.
Responsibilities of the Control Plane:
- Authentication & Authorization: Verifying user logins and checking RBAC policies (e.g., “Is User A allowed to access Table B?”).
- Metadata Management: Storing the schema definitions and table locations (e.g., an Apache Iceberg catalog like Nessie or Polaris acts entirely within the control plane).
- Query Planning: Taking a SQL string, parsing it, and generating the optimized execution plan using a Cost-Based Optimizer.
- Cluster Provisioning: Monitoring workloads and telling the cloud provider to spin up 5 new compute nodes because a massive query was just submitted.
The Data Plane (The Muscle)
The Data Plane (sometimes called the Compute Plane or Execution Plane) is the physical execution layer. It is the “muscle” that does the heavy lifting. It takes the instructions generated by the Control Plane and executes them against the actual physical data.
Responsibilities of the Data Plane:
- Data Ingestion: Reading the physical byte streams from Kafka or an API.
- Query Execution: Scanning the Parquet files on S3, performing the distributed Hash Joins in memory, and aggregating the results.
- Data Egress: Returning the final computed result set back to the user’s dashboard.
Why Separation Matters
Separating these planes provides massive benefits for security and SaaS deployment models.
In a modern “Bring Your Own Cloud” (BYOC) deployment, a vendor (like Dremio or Databricks) hosts the Control Plane in their own managed cloud account. The vendor’s engineers manage the upgrades, the UI, and the metadata catalog.
However, the Data Plane (the actual compute clusters and the S3 storage buckets containing the highly sensitive corporate data) lives entirely within the customer’s private Virtual Private Cloud (VPC).
When a user runs a query, the vendor’s Control Plane generates the execution plan and sends those instructions into the customer’s VPC. The customer’s Data Plane executes the query locally against the customer’s S3 buckets. The raw, sensitive data never leaves the customer’s network, and the vendor never has access to the underlying data, satisfying the strictest enterprise security requirements while still providing a seamless, fully-managed SaaS experience.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.