Continuous Processing
A guide to continuous processing, the true streaming architecture that processes data event-by-event with millisecond latency, as opposed to waiting for scheduled batches or micro-batch intervals.
Event-by-Event Analytics
While micro-batching provides the illusion of real-time by running tiny batch jobs every few seconds, some use cases demand absolute immediacy. High-frequency algorithmic trading, live multiplayer gaming leaderboards, and autonomous vehicle sensor processing cannot wait 2 seconds for a batch window to close.
Continuous processing (also known as true streaming or native streaming) is the architectural paradigm where data is processed strictly event-by-event, the exact millisecond it arrives.
In a continuous processing engine (like Apache Flink or Kafka Streams), there is no concept of a “batch.” The computational graph is continuously running and always active. When a single JSON event drops into a Kafka topic, it flows immediately through the processing nodes, is evaluated, and the result is emitted instantly.
The Challenges of Continuous State
The complexity of continuous processing arises when the business logic requires calculating aggregations over time.
If the logic is simple filtering (e.g., “If the transaction is over $10,000, send an alert”), continuous processing is easy; the engine looks at the event, evaluates the rule, and drops it.
However, if the logic is stateful (e.g., “Alert if a user spends over $10,000 within a 5-minute rolling window”), the engine must remember the past. It must maintain an internal “state” representing the running total of the user’s purchases.
Because continuous engines process millions of events per second across distributed clusters, managing this internal state is incredibly difficult:
- What happens if the server holding the user’s running total crashes?
- What happens if events arrive out of order due to network lag (an event from 10:01 arrives at 10:05)?
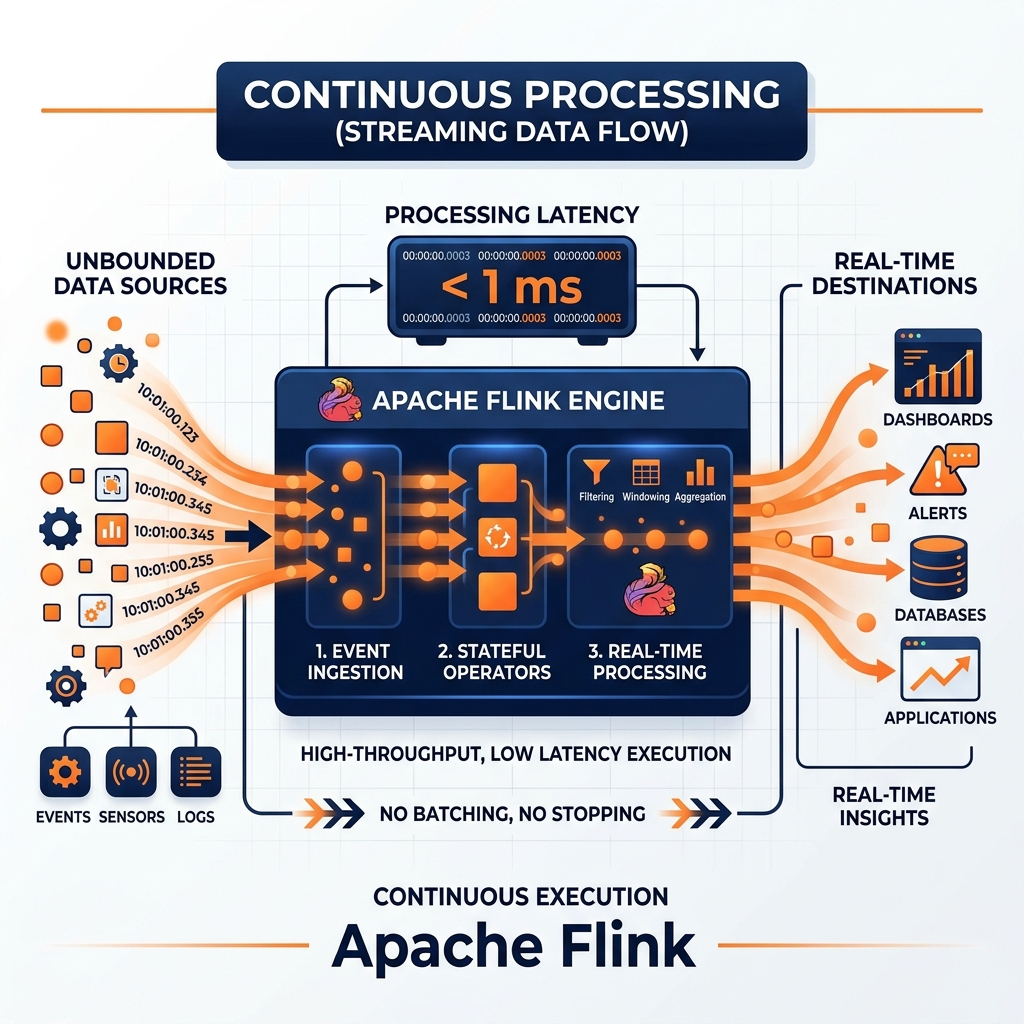
Solving the Challenges: Flink and Watermarks
Apache Flink is the industry standard for stateful continuous processing. It solves the state problem by continuously taking distributed snapshots of its internal memory (using the Chandy-Lamport algorithm) and saving them to durable storage like S3. If a node crashes, Flink restarts it and restores the exact state from the last snapshot, ensuring no running totals are lost or double-counted.
To solve the out-of-order data problem, continuous processing relies on “Event Time” and “Watermarks.” Instead of calculating the 5-minute window based on the time the server received the data (Processing Time), it uses the timestamp generated by the client device (Event Time).
A Watermark is a signal the engine generates saying, “I am confident I have received all events up to 10:05 AM.” Only when the watermark passes 10:05 AM will the engine officially close the 10:00-10:05 window and emit the final aggregated total, ensuring accurate analytics even when the mobile network delays a user’s purchase event by several minutes.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.