NoSQL Databases
A guide to NoSQL databases, the flexible, non-relational storage systems designed to handle massive volumes of unstructured or semi-structured data by sacrificing strict ACID guarantees for infinite horizontal scalability.
Breaking the Tabular Mold
In the late 2000s, the explosive growth of web applications, social media, and mobile devices created a data crisis. Applications were generating massive volumes of data at unprecedented velocities, and the data rarely fit neatly into the rigid, pre-defined rows and columns of a traditional Relational Database (RDBMS).
If a software developer wanted to add a new “Twitter Handle” field to a user profile, adding a new column to a massive relational table required a blocking database migration that could take the application offline for hours. Furthermore, relational databases scaled vertically (requiring bigger, more expensive servers), hitting physical limits.
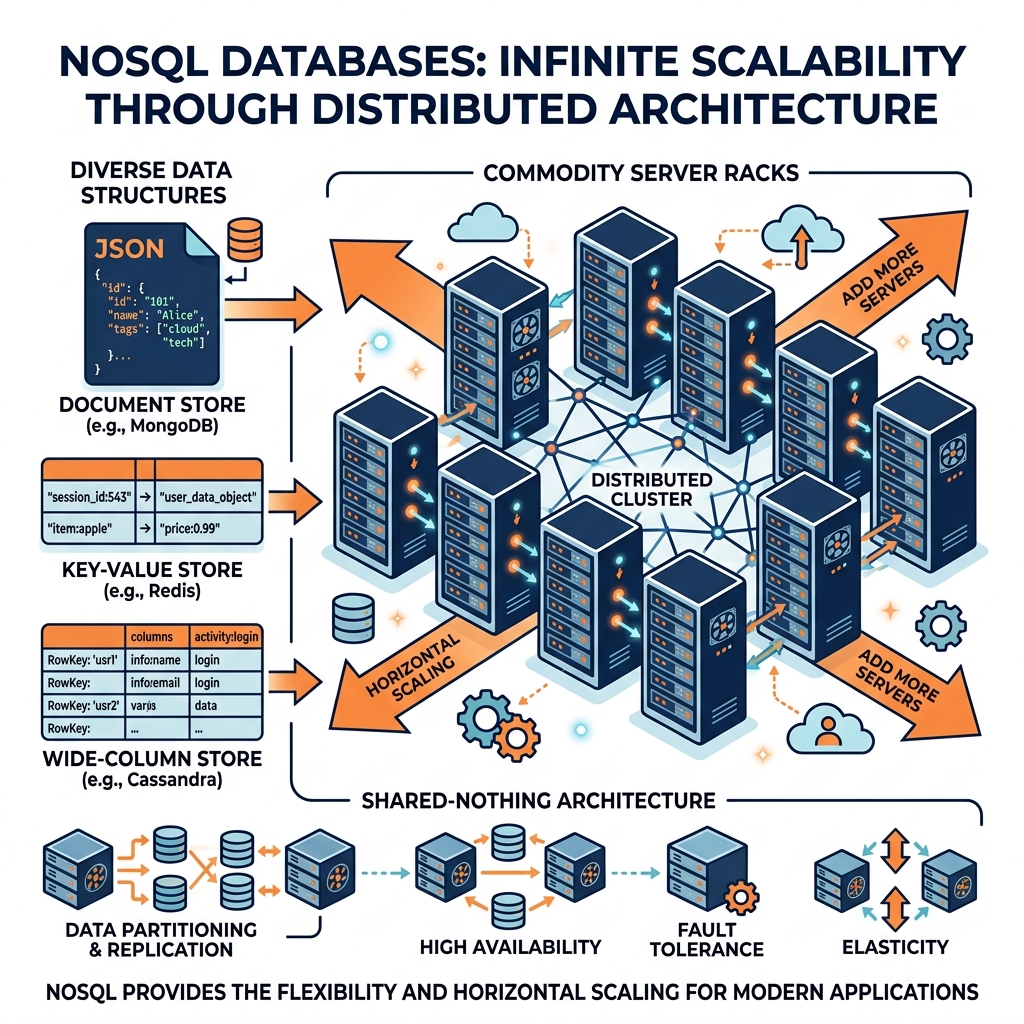
NoSQL (often interpreted as “Not Only SQL”) databases emerged as the solution. They abandoned the strict tabular constraints of the relational model in favor of flexible schemas and distributed, horizontal scalability (spreading the data across hundreds of cheap, commodity servers).
The Four Types of NoSQL
NoSQL is an umbrella term encompassing several fundamentally different architectural patterns:
1. Document Databases (e.g., MongoDB, Couchbase): The most popular NoSQL paradigm. Data is stored as complex, nested JSON-like documents. A single document can contain a user’s profile, a nested array of their recent orders, and a nested object containing their preferences. The schema is entirely flexible; Document A can have 5 fields, and Document B can have 50 fields, all living in the same collection.
2. Key-Value Stores (e.g., Redis, DynamoDB): The simplest and fastest databases. Data is stored as a massive dictionary of unique Keys pointing to unstructured Values. They provide sub-millisecond retrieval times and are heavily used for caching, user session management, and shopping carts.
3. Wide-Column Stores (e.g., Cassandra, HBase): Designed for massive write throughput across distributed clusters. They store data in column families, allowing highly efficient retrieval of specific attributes across billions of rows. They are heavily used in IoT time-series logging and high-velocity event tracking.
4. Graph Databases (e.g., Neo4j): Designed specifically to model and navigate highly complex relationships (nodes and edges), such as social networks or fraud rings.
The CAP Theorem Trade-off
The architectural compromise of NoSQL is defined by the CAP Theorem (Consistency, Availability, Partition Tolerance). In a distributed system, you cannot guarantee all three simultaneously.
While traditional relational databases prioritize strict Consistency (guaranteeing every user sees the exact same data, even if it means blocking access), NoSQL databases typically prioritize Availability and Partition Tolerance. They utilize “Eventual Consistency,” meaning if you update your profile picture in New York, a user in Tokyo might see the old picture for a few seconds before the distributed database nodes sync up. For web applications, this slight delay is an acceptable trade-off for infinite scalability and zero downtime.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.