Model Drift
A guide to model drift, the phenomenon where a perfectly trained machine learning model slowly loses predictive accuracy in production because the real-world environment and underlying data have changed over time.
When the World Changes
In traditional software engineering, if you write a Python function that adds two numbers together, that function will work perfectly forever. Two plus two will always equal four, whether you execute the code today or ten years from now.
Machine learning is fundamentally different. An ML model is not a fixed set of logical rules; it is a statistical reflection of the data it was trained on.
If a data science team trains a highly accurate fraud detection model using data from 2020 to 2022, they capture the patterns of how hackers operated during that specific time period. They deploy the model to production, and it works flawlessly. However, three years later, in 2025, hackers have invented entirely new techniques, and consumer spending habits have shifted due to inflation.
The 2022 model is now operating in a world that no longer matches its training data. Its accuracy begins to steadily decline. This degradation of predictive performance over time is known as Model Drift.
Types of Drift
Data scientists categorize drift into two distinct phenomena:
1. Data Drift (Feature Drift): The underlying statistical distribution of the input data changes, even if the definition of the target hasn’t. For example, a model predicts housing prices using “Interest Rate” as a key feature. In 2020, interest rates hovered around 3%. In 2024, they sit at 7%. The model has never seen a 7% interest rate during training, so its predictions become erratic. The input data itself has drifted.
2. Concept Drift: The actual relationship between the input data and the target changes. The definition of what you are trying to predict shifts. Before 2020, if a customer suddenly started buying massive quantities of toilet paper and hand sanitizer, the model correctly flagged it as “Institutional Buying.” During the 2020 pandemic lockdowns, average families began doing this. The input data was the same, but the underlying human “concept” of the behavior had fundamentally changed.
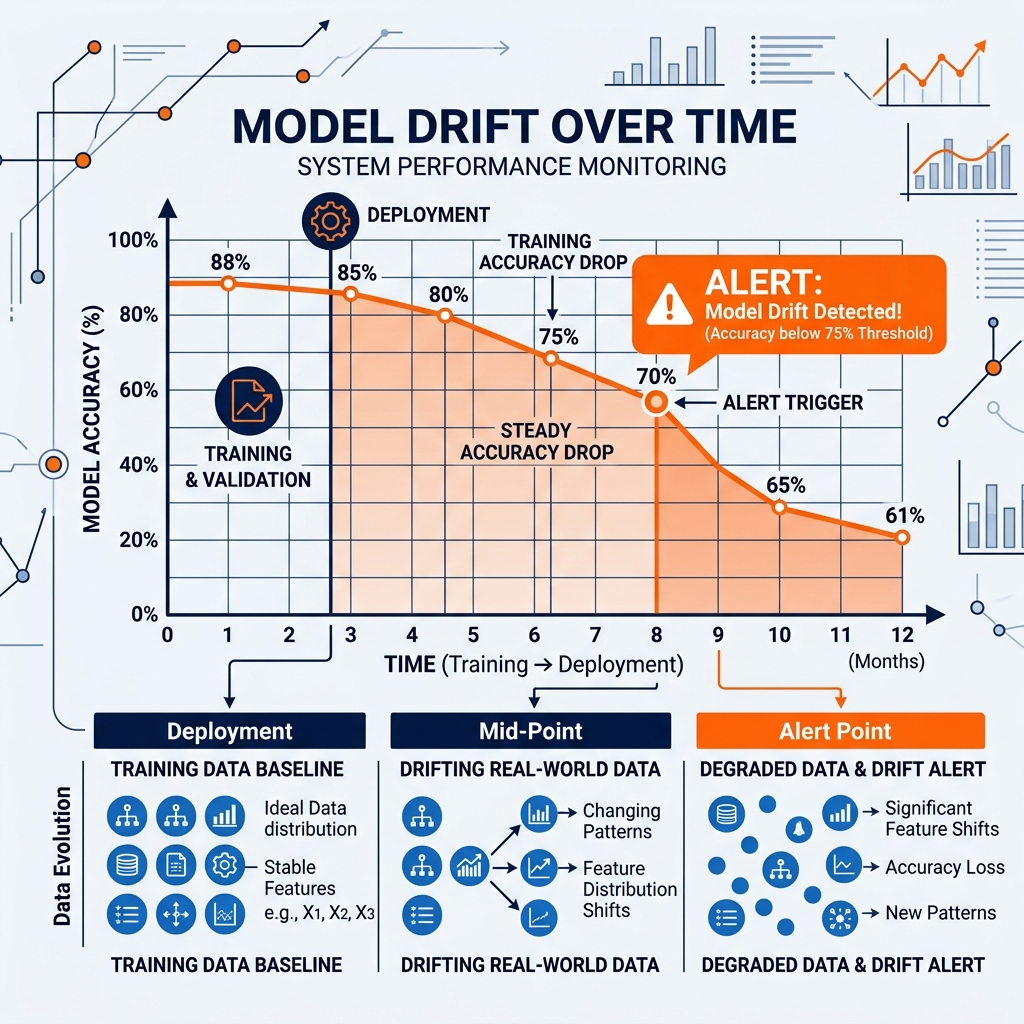
Combating Drift with MLOps
Model drift is inevitable. Therefore, the goal of modern MLOps (Machine Learning Operations) is not to prevent drift, but to detect it instantly and react automatically.
Data engineering pipelines are built to continuously monitor the statistical distribution of the live production data flowing through the lakehouse, comparing it against the baseline data the model was originally trained on.
When the MLOps monitoring system detects that the live data has drifted beyond a statistical threshold (using metrics like the Kullback-Leibler divergence), it fires an alert. In mature organizations, this alert automatically triggers a “Retraining Pipeline,” which fetches the most recent 30 days of fresh data from the Iceberg tables, retrains the model from scratch, tests it, and deploys the new, accurate version to production, closing the loop.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.