Kappa Architecture
A comprehensive guide to Kappa Architecture, the stream-first data processing paradigm that eliminates the complexity of Lambda by using a single, replayable event log as the sole source of truth.
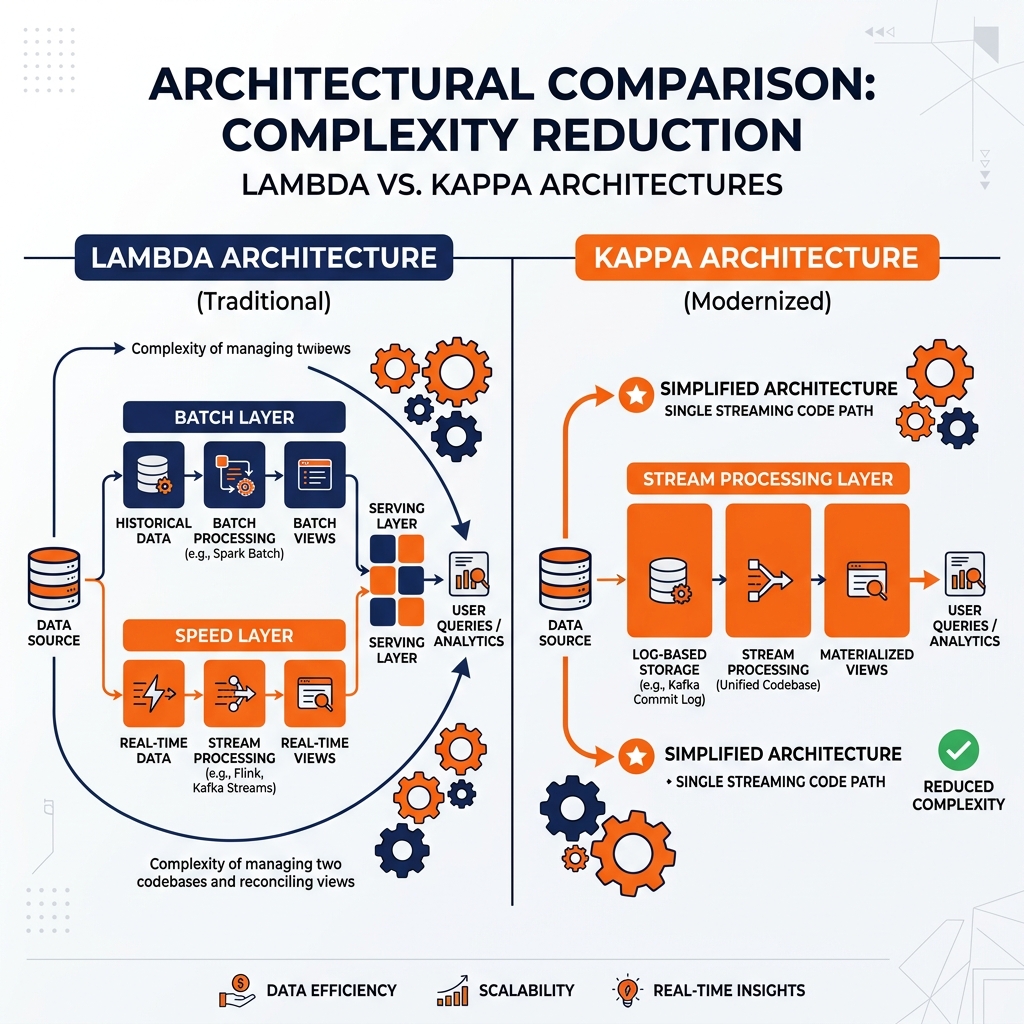
The Operational Burden of Two Code Paths
Jay Kreps, one of the original creators of Apache Kafka and a co-founder of Confluent, formalized the Kappa Architecture in 2014 in a blog post that responded directly to the operational complexity of the Lambda Architecture. His argument was precise and compelling: the fundamental problem with Lambda Architecture was not the presence of both a batch layer and a speed layer, but rather the requirement to maintain two completely separate implementations of the same business logic. This dual-code-path requirement was the source of most of the operational pain experienced by teams running Lambda systems in production.
Kreps identified that the core capability provided by the Lambda Batch Layer, the ability to reprocess the complete history of data, was already theoretically achievable in a streaming system if the underlying data log was designed with sufficient retention. Apache Kafka was specifically architected with this reprocessing capability in mind. A Kafka topic configured with a long enough retention period is not merely a message queue that deletes old events; it is a permanent, ordered, replayable log of every event the system has ever produced.
If historical reprocessing is achievable through a streaming framework applied to a replayable log, then the Batch Layer becomes logically redundant. The entire historical dataset is already stored in the event log, and a streaming framework can process it from the beginning at high speed, effectively simulating a batch run. If a bug is discovered in the stream processing logic, an engineer simply deploys the corrected consumer group, points it at offset zero of the Kafka topic, and allows it to reprocess the entire event history at maximum throughput. Once the consumer catches up to the live stream, it seamlessly transitions into real-time processing mode.
This insight led to the core proposition of Kappa Architecture: a single streaming system, backed by a replayable event log, can replace both the Batch Layer and the Speed Layer of Lambda Architecture while providing a single unified code path for all analytical computation.
The Core Principles of Kappa Architecture
Kappa Architecture is built on three foundational principles that collectively eliminate the complexity of the dual-layer Lambda approach.
Immutable Event Log as the Source of Truth
The cornerstone of Kappa Architecture is the treatment of the event log as the singular, immutable, authoritative source of truth. Every event produced by every operational system is published to a central, durable log, typically implemented using Apache Kafka or a similar distributed streaming platform. This log is append-only; events are never modified or deleted (except through explicit, time-based retention policies). The current state of any entity in the system is derived by processing the full sequence of events that describe its history.
This event-sourcing approach to data storage has significant implications. The raw event log is not a temporary buffer that events pass through on their way to a permanent database; it is itself the primary data store. All downstream databases, analytical tables, and materialized views are derived artifacts computed from the log. This means that if every downstream database were to be completely erased, the entire state of the system could be perfectly reconstructed by replaying the event log from the beginning.
Single Streaming Code Path
The defining operational advantage of Kappa Architecture over Lambda is the use of a single streaming code path for all data processing. In a Lambda system, maintaining separate Spark batch jobs and Flink streaming jobs for the same computation is an ongoing burden. In Kappa, a single streaming job handles both real-time processing of incoming events and historical reprocessing.
Modern streaming frameworks like Apache Flink and Apache Kafka Streams have matured to the point where they can efficiently process event time semantics, handle late-arriving events through watermark mechanisms, and produce exactly-once processing guarantees. These capabilities were the historically cited weaknesses of streaming systems that justified the existence of the Lambda Batch Layer. As these frameworks have closed the accuracy gap, the rationale for maintaining the separate batch code path has weakened considerably.
Reprocessing via Consumer Restart
Historical reprocessing in Kappa Architecture occurs through a simple operational pattern: deploying a new version of the stream processing job configured to consume from the earliest available offset of the event log. The new consumer group processes all historical events sequentially, building up its derived state from scratch. When it reaches the tail of the log (the current moment), it continues processing in real-time without any special transition logic.
During the reprocessing period, the old consumer group (running the previous version of the logic) continues to serve queries against its existing derived state. Once the new consumer group has fully caught up and its derived state is verified to be correct, traffic is switched to the new state, and the old state is decommissioned. This blue-green deployment pattern for data reprocessing is significantly simpler than the batch cycle management and merge logic required by Lambda systems.
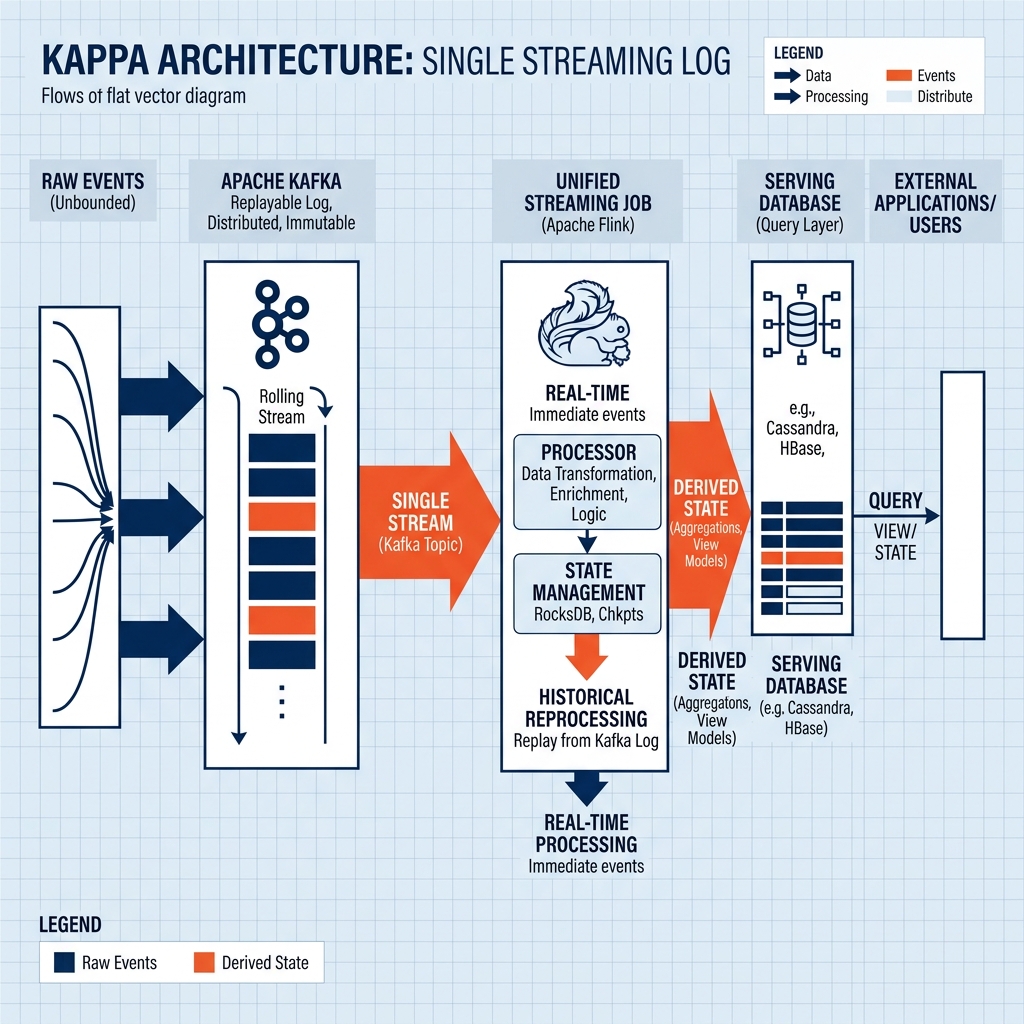
Apache Kafka as the Foundation
Apache Kafka is the enabling technology that makes Kappa Architecture practical. Understanding why requires examining Kafka’s specific architectural properties that distinguish it from traditional message queues.
Traditional message queues, such as RabbitMQ, are designed for transient messaging. When a consumer reads a message, it is typically deleted from the queue. The queue is a temporary buffer, not a permanent store. If a consumer fails, it can recover by reprocessing messages that are still in the queue, but historical messages that were already consumed are permanently gone.
Kafka’s design philosophy is fundamentally different. Kafka stores all messages as a persistent, ordered log on disk. Consumers track their position in the log using a numeric offset. Reading a message does not delete it; the message remains available at its offset for any other consumer to read. Kafka’s retention is configurable; topics can be configured to retain messages for days, months, or indefinitely through log compaction, which retains only the latest value for each unique key regardless of time.
This architectural distinction is what makes Kafka the ideal substrate for Kappa Architecture. Because the full event history is retained in the log, historical reprocessing is trivially achievable by simply resetting a consumer’s offset to zero. The log serves as the canonical record that can regenerate any derived view on demand. This makes the Kafka topic the functional equivalent of the Lambda Batch Layer’s master dataset, but with the additional capability of delivering events in real-time with millisecond latency.
Kappa’s Limitations and Real-World Constraints
Kappa Architecture is intellectually elegant, but it carries practical constraints that have prevented it from universally replacing Lambda in all enterprise contexts.
Retention Cost and Practicality
Storing years of raw event data indefinitely in a Kafka cluster is significantly more expensive than storing the same data in compressed Parquet files on object storage. Kafka is optimized for high-throughput sequential write and read performance, not for cost-efficient long-term archival. For organizations generating petabytes of raw events per day, the economics of unlimited Kafka retention can become prohibitive.
This practical constraint has led to a common hybrid approach where Kafka topics have limited retention (hours to days) for real-time processing, and a separate archival system (typically Apache Iceberg tables on object storage) serves as the long-term event log for historical reprocessing. This combination retains the single streaming code path of Kappa while solving the storage economics problem.
Streaming Framework Maturity for Complex Computations
Not all computations are well-suited to streaming frameworks. Certain complex machine learning training jobs, large-scale multi-way joins, and sophisticated graph algorithms are considerably easier to express and optimize in batch processing frameworks like Apache Spark than in streaming APIs. For organizations that rely heavily on these types of computations, the operational complexity of maintaining a separate batch job may be justified.
State Management at Scale
Streaming jobs that maintain large amounts of state (for example, a join across multiple streams that requires keeping billions of keys in memory) can become operationally complex to manage. State backends for streaming frameworks (like Flink’s RocksDB state backend) require careful tuning, and state migrations during reprocessing can be complex when the data volume is very large. Batch systems, which read from disk on every run rather than maintaining persistent in-memory state, avoid this operational dimension entirely.
Kappa in the Modern Lakehouse
The open Data Lakehouse has significantly enhanced the practical applicability of Kappa Architecture by solving its primary limitation: cost-effective long-term event storage. Apache Iceberg tables on cloud object storage provide the perfect archival substrate for Kappa’s event log.
Rather than retaining unlimited events in expensive Kafka storage, organizations implement a two-tier event log. Kafka retains recent events (typically seven to thirty days) for low-latency stream processing. A separate Apache Flink job simultaneously consumes from Kafka and appends every event to an Iceberg table on Amazon S3, creating an infinitely scalable, cost-effective, and ACID-compliant archival log. When historical reprocessing is required, the Flink job is pointed at the Iceberg table rather than at Kafka’s offset zero, reading the historical events through Iceberg’s highly optimized Parquet-based storage at very high throughput.
This architecture provides the best properties of both storage systems: Kafka’s low-latency streaming delivery for real-time processing and Iceberg’s cost-effective, governed, time-travel-capable archival storage for historical reprocessing. Dremio can then be deployed on top of the Iceberg tables to provide interactive analytical queries against the processed derived state, completing the full Kappa Lakehouse architecture with a semantic layer for governed data access.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.