Hyperparameter Tuning
A guide to hyperparameter tuning, the experimental process of adjusting the external configuration settings of a machine learning model to optimize its learning efficiency and final predictive accuracy.
Tuning the Engine
When training a machine learning model, there are two distinct types of variables: Parameters and Hyperparameters.
Parameters are the internal variables that the model learns completely on its own during the training process. For example, in a linear regression model (y = mx + b), the model automatically calculates the slope (m) and the intercept (b) by looking at the data. A human does not set these values.
Hyperparameters are the external configuration settings of the model algorithm itself. The model cannot learn these; a human data scientist (or an automated script) must set them before the training process even begins. Think of hyperparameters as the dials and knobs on the dashboard of a car. You set the gear and the cruise control speed (the hyperparameters), and the engine then figures out how much fuel to inject (the parameters).
Hyperparameter tuning is the iterative process of testing dozens or hundreds of different configurations to find the specific combination of dials that results in the most accurate model.
Common Hyperparameters
The specific hyperparameters vary drastically depending on the type of algorithm:
Learning Rate: Used in neural networks and gradient boosting. It determines how aggressively the model updates its internal parameters after every training step. If the learning rate is too high, the model “overshoots” the optimal answer and never learns. If it is too low, the model takes an eternity to learn.
Number of Trees (n_estimators): Used in Random Forest models. It defines how many individual decision trees the forest should contain. More trees generally increase accuracy but make the model significantly slower to train and execute.
Maximum Depth: Determines how deep a decision tree is allowed to grow. A deep tree can learn highly complex patterns, but risks memorizing the training data perfectly (overfitting) and failing on new data.
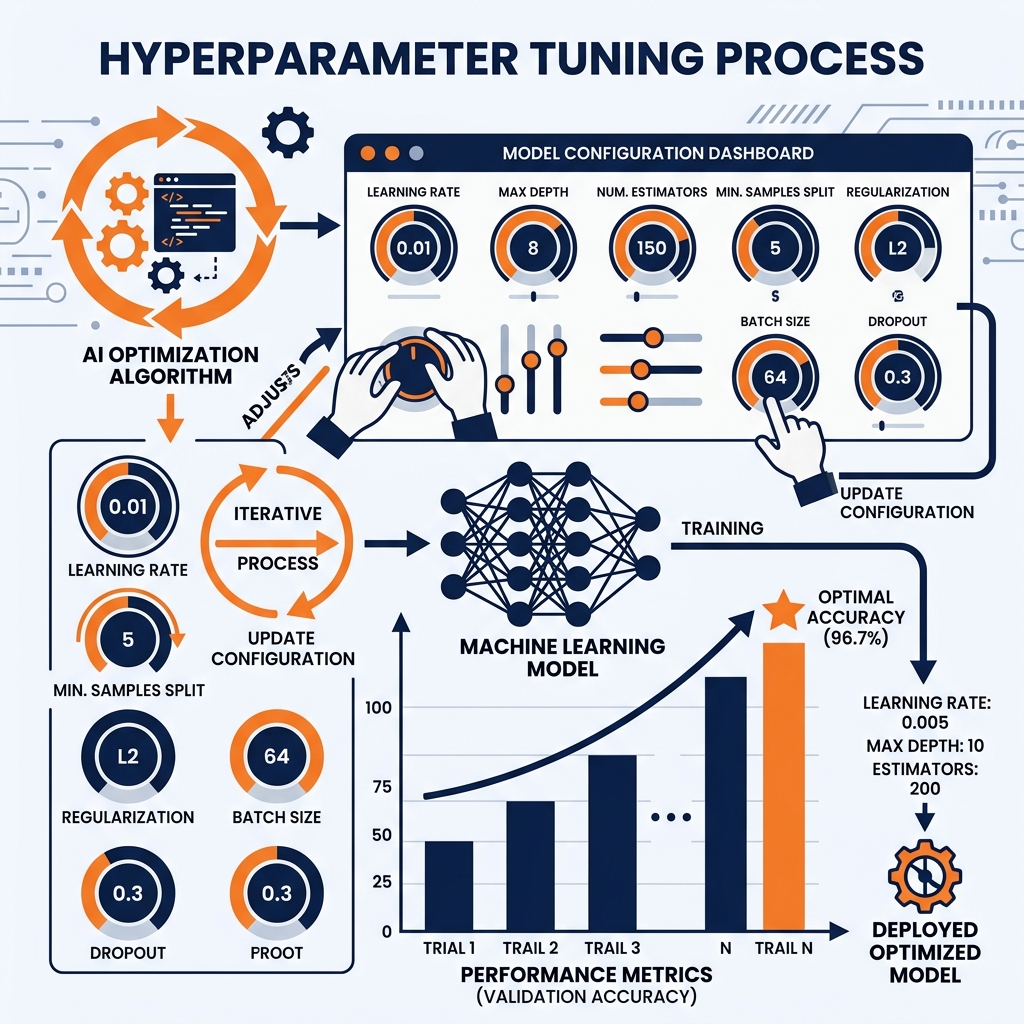
Tuning Strategies
Because training a massive model on a lakehouse can take hours or days, data scientists cannot manually guess hyperparameters. They use systematic, automated search strategies:
Grid Search: The brute-force approach. The scientist defines a list of values for each hyperparameter (e.g., Learning Rate: [0.1, 0.01, 0.001], Max Depth: [5, 10, 15]). Grid Search trains a separate model for every single possible mathematical combination of those lists. It guarantees finding the best combination within the grid but is incredibly computationally expensive.
Random Search: Instead of testing every single combination, Random Search picks combinations at random from the defined lists. Surprisingly, mathematical studies show that Random Search almost always finds a nearly-optimal configuration in a fraction of the time and compute cost of Grid Search.
Bayesian Optimization: An intelligent, AI-driven approach. The tuning algorithm trains a few models, analyzes which hyperparameter combinations resulted in the best accuracy, and uses that knowledge to intelligently guess which new combinations to try next, rapidly zooming in on the optimal configuration.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.