Extract, Transform, Load (ETL)
A comprehensive guide to Extract, Transform, Load (ETL), the foundational data integration pattern that has shaped enterprise data pipelines for decades and continues to evolve in the modern lakehouse era.
The Origins of Data Integration
Long before the era of cloud computing and distributed data platforms, enterprises faced a persistent and fundamental challenge: their operational data was scattered across dozens of isolated departmental databases. The accounting department ran its own proprietary financial system, the sales department operated a separate customer management database, and the manufacturing division maintained its own production tracking system. Each of these systems spoke a different query language, used a different data format, and enforced a different schema.
Executive leadership required consolidated analytical reporting that could present a unified view of the business. How many units were sold in the Northeast region this quarter, and what was the associated gross margin after accounting for manufacturing costs? Answering this question required combining data from at least three separate systems that had never been designed to communicate with each other.
Early data integration was performed entirely by hand. Database administrators would manually export data from each source system to flat files, write custom Perl or shell scripts to transform the data formats, and manually import the results into a centralized reporting database. This process was labor-intensive, error-prone, and completely impossible to scale as the number of source systems grew.
The emergence of dedicated ETL (Extract, Transform, Load) tools in the late 1980s and through the 1990s formalized and automated this integration process. Products like Informatica PowerCenter, IBM DataStage, and Microsoft SQL Server Integration Services (SSIS) provided graphical development environments where data engineers could visually design data flows between sources and destinations, define transformation logic through a library of pre-built operators, and schedule automated execution on a recurring basis. These tools dramatically accelerated the development of data integration pipelines and established ETL as the dominant paradigm for enterprise data management for the next three decades.
The Three Phases of ETL
Understanding ETL requires a precise examination of each of its three constituent phases and the specific responsibilities that each phase carries.
Extract
The Extract phase is concerned solely with acquiring data from source systems. Sources are typically diverse: relational databases (Oracle, SQL Server, PostgreSQL), ERP systems (SAP, Oracle Fusion), CRM platforms (Salesforce), flat files on network shares, and FTP servers delivering files from external partners.
Extraction strategies vary depending on how much data must be transferred. Full extraction reads the complete contents of a source table on every pipeline run. While simple to implement, full extraction is inefficient for large tables, as it transfers data that has not changed since the last run. Incremental extraction identifies only the rows that have changed since the previous extraction by querying a timestamp column, a row version number, or a dedicated change log. Incremental extraction dramatically reduces the volume of data transferred and is the standard approach for high-volume production pipelines.
During extraction, raw data is typically staged in a temporary holding area, sometimes called a staging database or a landing zone, rather than being immediately passed to the transformation phase. This staging allows the transformation logic to operate on a complete, consistent snapshot of the source data without holding open long-running transactions on the production source system.
Transform
The Transform phase is where the majority of the business logic in an ETL pipeline resides. Transformation encompasses a wide range of data manipulation operations applied to the raw extracted data before it is loaded into the destination.
Data cleansing addresses quality issues in the raw data. Null values are replaced with appropriate defaults, duplicate records are identified and eliminated, and invalid values (a birthdate of 1900-01-01 used as a null placeholder) are corrected or filtered out. Format standardization converts values to a consistent representation: phone numbers stripped of dashes and parentheses, country codes standardized to ISO-3166 two-letter codes, and dates converted to a single timezone.
Data conforming reconciles different representations of the same entity across source systems. The CustomerID field in the CRM uses a UUID format while the Account_No field in the ERP uses a sequential integer; the transformation joins these on a master customer table to produce a unified canonical_customer_id that appears in the destination.
Business logic application is the most analytically significant transformation. Raw transactional records are joined to reference tables to enrich them with dimensional attributes. Calculated metrics are derived: gross margin is computed as (revenue - cost_of_goods_sold) / revenue, a “high-value customer” flag is set based on lifetime purchase history. These transformations encode the organization’s analytical definitions into the pipeline as executable code, creating the standardized business view that downstream reporting depends on.
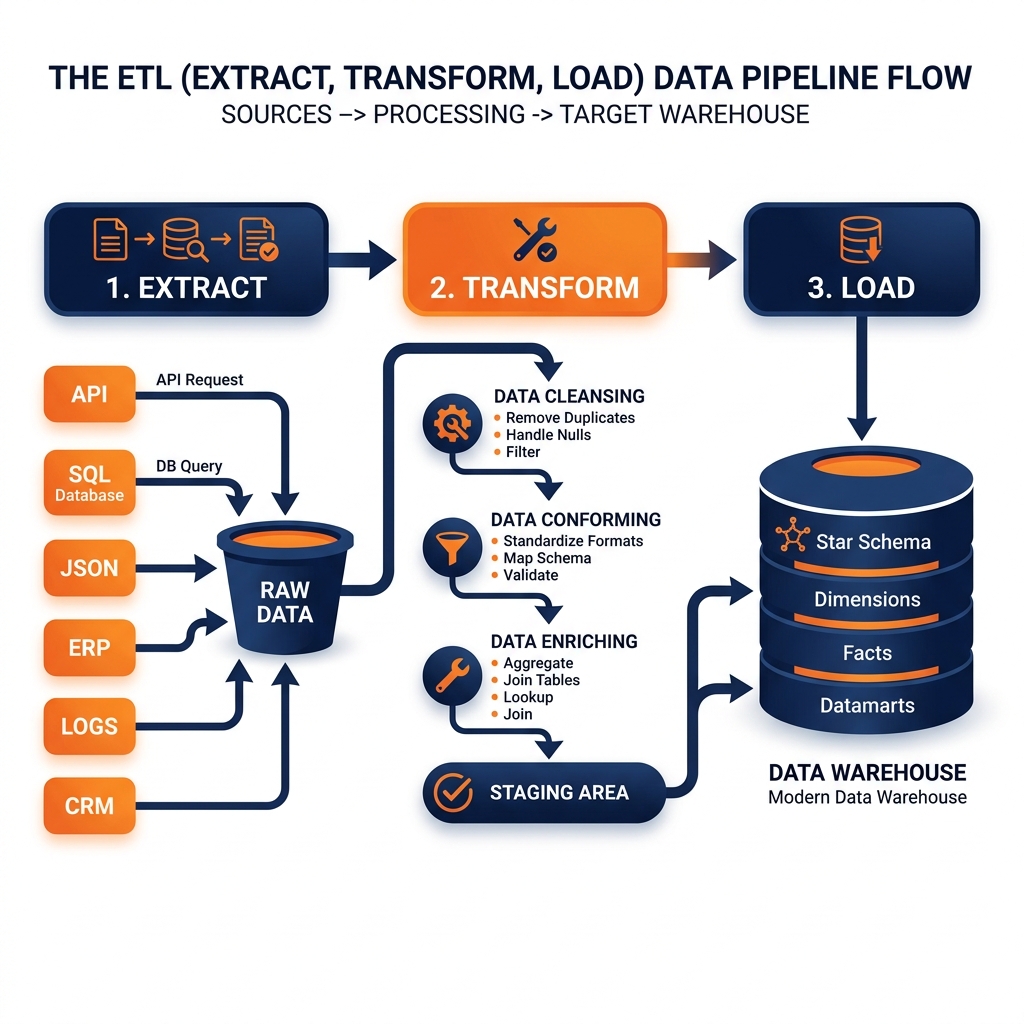
Load
The Load phase transfers the transformed data into the destination system, typically a relational data warehouse. Loading strategies vary by the destination table type and the frequency of the pipeline run.
Full load truncates the destination table and reloads all records from scratch on every pipeline run. This guarantees the destination always reflects the current state of the source but is expensive for large tables. Incremental load appends new records or applies updates to existing records using merge (upsert) logic, which is efficient but requires robust change detection in the extraction phase. Slowly Changing Dimension (SCD) loading implements specific strategies for handling historical changes to dimensional attributes, such as preserving the previous address of a customer when they move, to support accurate historical reporting.
ETL’s Structural Limitations
While ETL served the industry well for decades, the explosion of data volume and the emergence of cloud-scale data architectures exposed fundamental structural limitations in the classic ETL paradigm.
The most significant limitation of ETL is the schema-on-write requirement for the transformation phase. Every byte of data must be understood, parsed, and forced into the destination schema before it can be stored. When a new source system is onboarded, the data engineers must first fully analyze its schema, design the appropriate transformations, build and test the pipeline code, and only then can data begin flowing. For organizations ingesting dozens of new data sources per year, this schema-on-write requirement creates severe bottlenecks.
ETL also creates fragile dependencies between the pipeline and the source systems. Because the transformation logic is tightly coupled to the specific column names and data formats of the source, any schema change in the source system (a renamed column, an altered data type) immediately breaks the transformation step. In environments where application developers deploy schema changes frequently and independently, ETL pipelines become a constant maintenance burden for the data engineering team.
The sequential architecture of ETL creates scalability constraints. The transformation step must complete before any data reaches the destination, which means the pipeline is only as fast as the slowest transformation. For massive datasets, the transformation phase can consume hours of compute time, creating analytical latency that is incompatible with near-real-time business intelligence requirements.
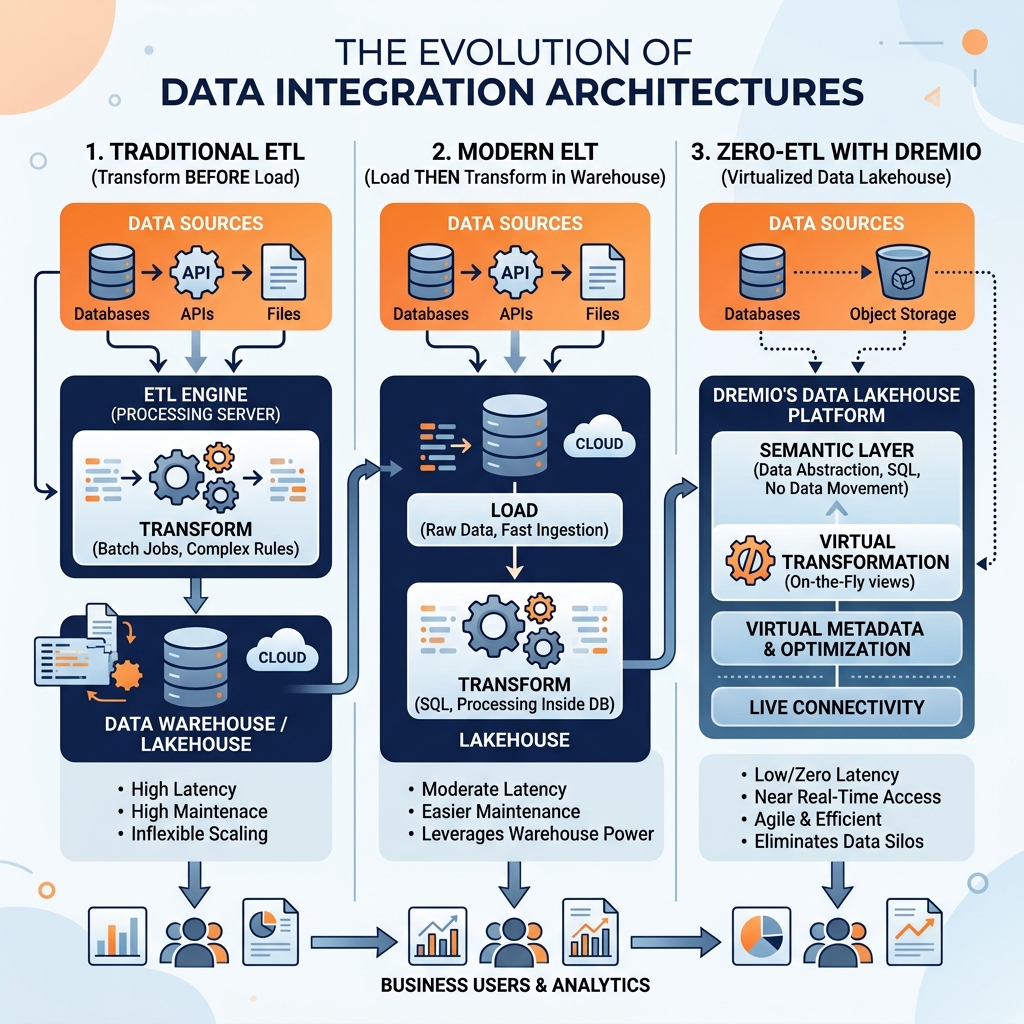
The Rise of ELT: Inverting the Paradigm
The widespread adoption of cloud data warehouses (Snowflake, Google BigQuery, Amazon Redshift) and data lakehouses fundamentally changed the economics of transformation, catalyzing the shift from ETL to ELT (Extract, Load, Transform). In ELT, raw data is loaded directly into the destination platform without transformation, and the transformation logic is applied after the load using the destination platform’s compute power.
This inversion provides significant architectural benefits. Raw data is available in the destination immediately after extraction and loading, dramatically reducing analytical latency. Because the raw data is stored in the destination before transformation, failed transformation jobs can be easily re-run without re-extracting from the source. Data scientists and analysts can access raw data in the destination to perform ad-hoc explorations that would be impossible in a classic ETL pipeline where the raw data is discarded after transformation.
The ELT model underpins modern tools like dbt (Data Build Tool), which allows data engineers to express transformations as SQL SELECT statements version-controlled in Git, run directly against the destination data warehouse or lakehouse. This approach brings software engineering best practices (code review, unit testing, version control) to data transformation, replacing the opaque graphical transformation environments of legacy ETL tools.
Modern ETL and ELT with Dremio
In the modern lakehouse architecture, Dremio’s Zero-ETL philosophy represents the logical endpoint of the ELT evolution. For many analytical use cases, the transformation step can be entirely virtualized within Dremio’s Semantic Layer, eliminating the need to physically write any transformed data to a separate destination table.
Data engineers build virtual datasets in Dremio that define the transformation logic as parameterized SQL views directly over the raw Apache Iceberg tables in the lakehouse. When a BI tool queries the Semantic Layer, Dremio dynamically applies the transformation logic at query time and returns the results. For performance-sensitive workloads, Dremio Data Reflections automatically pre-compute and cache the most frequently queried transformations as optimized Iceberg tables, delivering data warehouse performance without requiring a separate physical ETL pipeline or destination table.
This approach does not render traditional ETL obsolete. For complex historical corrections, cross-database reconciliation, and specialized data quality workflows, physical ETL and ELT pipelines remain valuable tools. However, for the majority of analytical use cases, the combination of the raw data lakehouse, the Iceberg table format, and the Dremio Semantic Layer dramatically reduces the scope and complexity of the ETL work required to deliver governed, high-performance analytical access to enterprise data.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.