Extract, Load, Transform (ELT)
A comprehensive guide to ELT, the modern inversion of traditional ETL that leverages the computational power of cloud data warehouses and lakehouses to perform transformations after loading raw data.
Why ETL Broke Under Cloud-Scale Pressure
The traditional ETL (Extract, Transform, Load) paradigm served enterprise data engineering for decades. It worked because the destination data warehouse was an expensive, specialized database with limited storage capacity and relatively modest compute power. Every megabyte of storage space in an on-premises Oracle or Teradata appliance was costly, so engineers applied rigorous transformations to shrink data footprints before loading. The transformation server was a separate, dedicated machine that sat between the source systems and the warehouse, bearing the computational burden of cleansing, joining, and aggregating the data.
When cloud-native data platforms emerged in the late 2000s and early 2010s, this architectural calculus inverted completely. Storage in cloud platforms became extraordinarily cheap, orders of magnitude less expensive than on-premises appliances. More importantly, cloud data warehouses like Amazon Redshift, Google BigQuery, and Snowflake were architected with Massively Parallel Processing (MPP) capabilities that could apply complex SQL transformations across billions of rows in seconds, using the same platform that stored the data. There was no longer any practical reason to maintain a separate, expensive transformation server when the destination platform itself was vastly more powerful than any dedicated ETL machine.
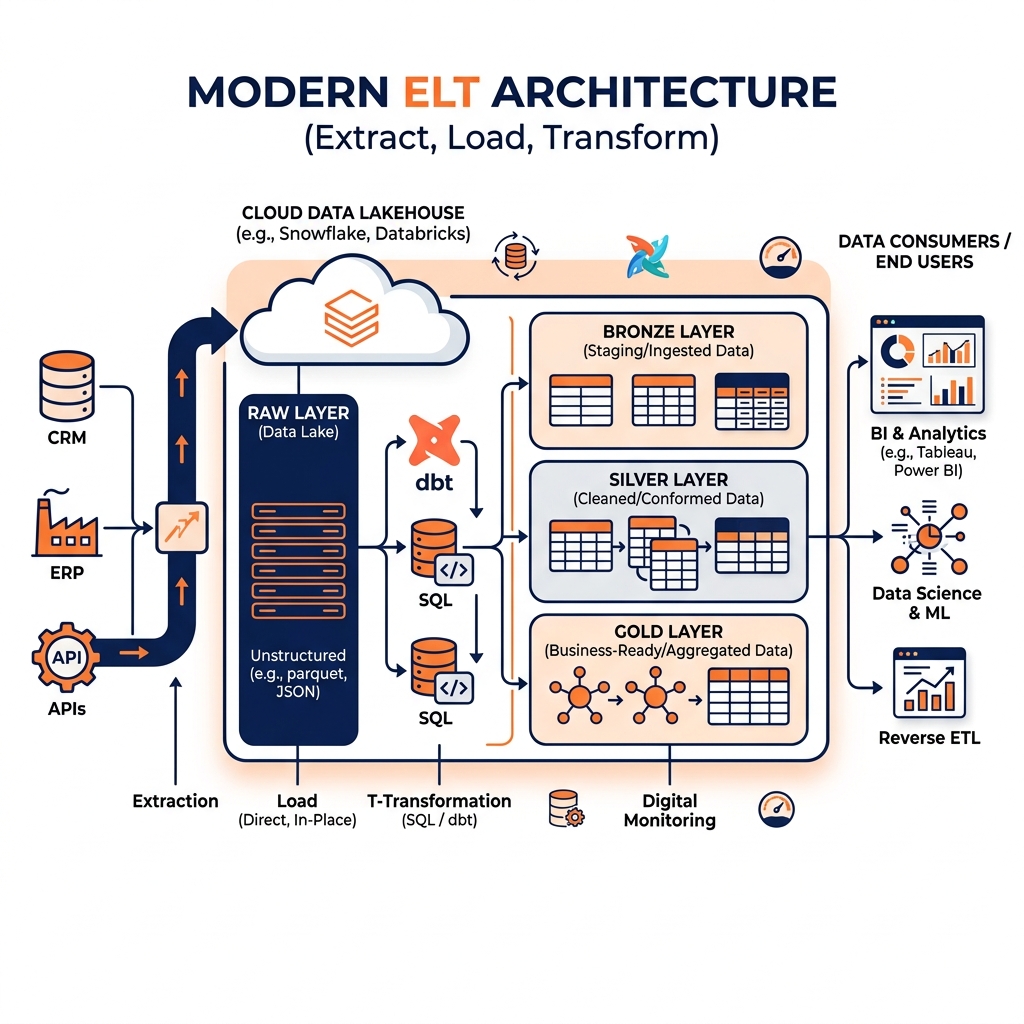
This shift in the economics and capabilities of destination platforms catalyzed the widespread adoption of ELT: Extract, Load, Transform. In ELT, the transformation step is moved from a pre-load process executed on a separate server to a post-load process executed directly inside the destination platform using SQL. Raw, unaltered data from source systems is loaded as quickly as possible into the destination. Once the data lands, powerful SQL-based transformation frameworks run within the destination platform to clean, conform, and model the data into analytical structures.
The impact of this architectural inversion was profound. ETL pipelines that previously took days or weeks to build and weeks more to maintain could be replaced by relatively concise, readable SQL scripts managed in version control. The entire discipline of data transformation became accessible to a broader range of practitioners because SQL, rather than specialized ETL tool scripting languages, became the primary transformation interface.
The Core ELT Workflow
ELT separates the data integration process into three sequential phases, with the critical distinction from ETL being that transformation occurs after the data reaches its destination.
Extract: Rapid, Raw Ingestion
In an ELT architecture, the Extract phase is deliberately simplified. The goal is to move data from source systems to the destination platform as rapidly as possible, without applying any transformation logic that might slow the ingestion process or require detailed upfront knowledge of how the data will eventually be used.
Data is extracted from sources including operational relational databases (via direct database connections or Change Data Capture streams), SaaS applications (via REST API calls to platforms like Salesforce, HubSpot, or Stripe), event streams (via Apache Kafka or cloud-native streaming services), and file-based sources (CSV and JSON files delivered to S3 buckets via partner integrations).
Modern ELT extraction is typically handled by purpose-built ingestion tools rather than custom code. Platforms like Fivetran, Airbyte, and Stitch specialize in pre-built connectors for hundreds of popular source systems. These tools manage schema detection automatically, handle authentication securely, track which records have been ingested (watermarking), and deliver raw data to the destination with minimal engineering effort. This automation allows data engineering teams to onboard new data sources in hours rather than weeks.
Load: Raw Storage in the Destination
The Load phase deposits the raw extracted data directly into the destination platform, typically in a dedicated staging area or raw schema. Because no transformation has been applied, the data arriving in the destination is unfiltered and unprocessed: it may contain duplicate records (from at-least-once extraction retries), inconsistent data types, null values, and columns whose business significance is not yet fully understood.
This raw landing layer is not a weakness of ELT; it is a deliberate architectural feature. The raw data serves multiple purposes. First, it provides an auditable historical record of exactly what arrived from the source system at each point in time. If a transformation bug is discovered six months later, the raw source data is available for reprocessing without needing to re-extract from the source. Second, raw data enables exploratory analysis. Data scientists can query the raw landing tables directly to understand the full fidelity of the source data, discovering signals that might be destroyed by a premature transformation.
In a lakehouse architecture, the raw landing zone corresponds directly to the Bronze layer of the Medallion Architecture. Apache Iceberg tables serve as the raw landing destination, providing ACID guarantees that prevent corrupted partial loads from becoming visible to consumers.
Transform: SQL-Powered Modeling Inside the Destination
The Transform phase in ELT is where the data engineering work occurs, and it is fundamentally different from the transformation step in classic ETL. Rather than executing transformations in a separate ETL server, all transformation logic runs as SQL queries directly inside the destination platform.
The destination platform’s Massively Parallel Processing engine applies the SQL transformation queries across the full raw dataset in parallel, leveraging the platform’s full compute resources. A complex join across three tables containing one billion rows each, which might take hours on a dedicated ETL server, executes in seconds within a cloud data warehouse or lakehouse equipped with appropriate compute resources.
Transformations progress through multiple layers, typically aligned with the Medallion Architecture. The first transformation layer cleanses the raw data: removing duplicates, standardizing data types, handling null values, and resolving schema inconsistencies. The second layer conforms the cleansed data into enterprise-standard entities. The third layer applies dimensional modeling to produce business-ready Fact and Dimension tables optimized for BI tool consumption.
dbt: The Transformation Framework for ELT
The emergence of dbt (Data Build Tool), originally built by Fishtown Analytics (now dbt Labs), formalized and standardized the Transform phase of ELT into a disciplined software engineering practice. dbt has become the defining tool of the modern ELT ecosystem, fundamentally changing how data transformation is written, tested, versioned, and deployed.
SQL as the Transformation Interface
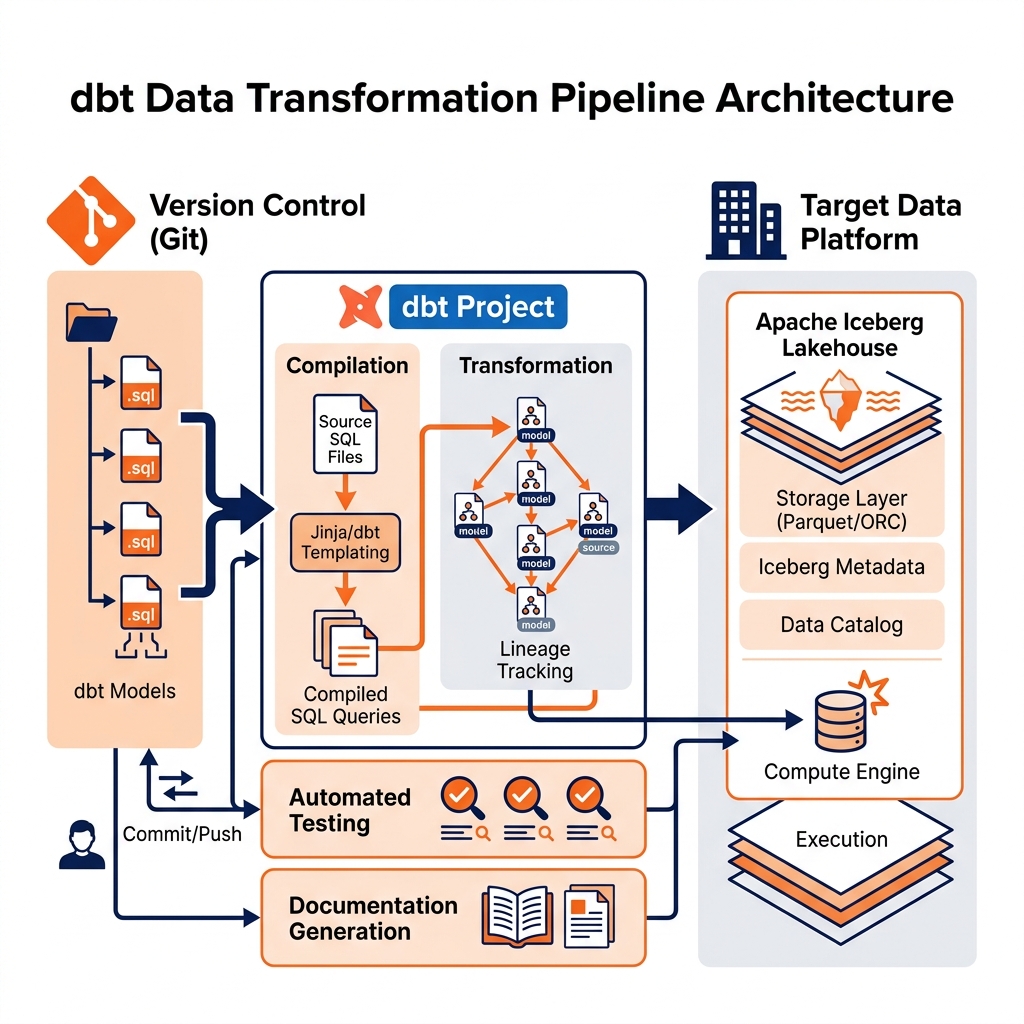
dbt’s core innovation was straightforward: every transformation is expressed as a SQL SELECT statement saved in a .sql file. Engineers do not write INSERT or UPDATE statements; they write SELECT queries that define what the output of the transformation should look like. dbt compiles these SELECT statements into the appropriate CREATE TABLE AS or INSERT INTO SQL statements and executes them against the destination platform.
This SQL-first approach has significant implications for the data engineering workforce. Rather than requiring engineers to master a proprietary ETL tool’s scripting language or graphical interface, dbt requires only SQL proficiency, a skill that is far more widely distributed across data teams than ETL tool expertise. Business analysts and data scientists who understand SQL can read, review, and even contribute to dbt transformation models, dramatically broadening the team of people who can productively participate in data pipeline development.
Software Engineering Practices for Data
Beyond the SQL interface, dbt introduced comprehensive software engineering practices to data transformation that had previously been absent in most ETL workflows.
Version Control: dbt projects are standard Git repositories. Every transformation model is a text file tracked in version control. Engineers use branches and pull requests to propose changes, and team leads review transformation logic before it is deployed to production, exactly as software development teams review application code.
Automated Testing: dbt provides a native testing framework for validating data quality. Engineers write test assertions directly alongside their transformation models: a not_null test verifies that a column never contains null values, a unique test verifies that a column serves as a reliable primary key, and a relationships test verifies that foreign key references resolve to valid records in a parent table. These tests run automatically after each transformation job, immediately flagging data quality regressions.
Documentation: dbt generates a self-updating HTML documentation portal that describes every model, column, test, and lineage relationship in the project. When a new analyst joins the team, they can browse the dbt documentation portal to understand what every table contains, how it was built, and what data quality guarantees it carries, without needing to schedule a meeting with the data engineering team.
Lineage Tracking: dbt automatically tracks the dependencies between models. If a downstream model depends on an upstream model, dbt constructs a Directed Acyclic Graph (DAG) of all transformation dependencies and executes them in the correct order. This DAG also powers visual lineage graphs that allow engineers to instantly identify which downstream dashboards would be affected by a change to a specific upstream raw table.
ELT on the Open Lakehouse with Apache Iceberg
While ELT was initially popularized in the context of cloud data warehouses (Snowflake, BigQuery, Redshift), the principles apply equally, and in many ways more powerfully, to the open Data Lakehouse backed by Apache Iceberg.
Applying ELT on an Iceberg lakehouse provides capabilities that traditional cloud data warehouses cannot match. Iceberg’s Time Travel feature allows data engineers to query the state of any table as it existed at any historical snapshot. If a dbt transformation run corrupts a Silver layer table, the engineer can immediately roll back to the previous snapshot using Iceberg’s rollback command, restoring the table to its pre-transformation state in milliseconds. In a traditional cloud data warehouse, recovering from a failed transformation requires restoring from a backup (a slow, disruptive process) or reprocessing from the raw source data.
Iceberg’s schema evolution capabilities allow columns to be added, renamed, or dropped from transformation output tables without requiring the consumer-facing queries to change. When a new field is added to the Bronze raw data and needs to flow through to the Silver and Gold layers, the data engineer updates the dbt model to include the new column, and Iceberg’s metadata layer handles the schema migration transparently.
Multiple compute engines can read and write Iceberg tables simultaneously. A dbt job using Apache Spark as its execution engine can run the Silver transformation while a separate Dremio virtual dataset queries the same Silver Iceberg tables in real-time. This multi-engine interoperability is unavailable in proprietary cloud data warehouses where the compute and storage are tightly coupled.
The Relationship Between ELT and the Semantic Layer
ELT handles the physical transformation of raw data into cleaned and modeled tables. The Semantic Layer, implemented in a platform like Dremio, handles the logical transformation of physical tables into business-friendly virtual datasets. These two layers are complementary and serve different stages of the data delivery pipeline.
ELT (implemented via dbt) produces the physical Gold layer tables: materialized Fact and Dimension tables stored as Iceberg Parquet files in the lakehouse. These tables are structurally clean and analytically useful, but they may still use technical column names and lack the final business context required by non-technical users.
The Semantic Layer then takes these physical Gold tables as its inputs. Data engineers build virtual datasets in Dremio that expose the Gold tables through business-friendly column names, add pre-computed calculated metrics, join Fact tables to Dimension tables for denormalized reporting, and enforce Row-Level Security to restrict access based on the user’s organizational role.
This layered architecture cleanly separates responsibilities. The dbt ELT pipeline owns the physical data quality and structural modeling. The Dremio Semantic Layer owns the business context, performance optimization (via Data Reflections), and governed access control. Together they provide a complete, end-to-end data delivery pipeline from raw source data to governed, high-performance analytical access.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.