Data Vault Modeling
A comprehensive guide to Data Vault modeling, the enterprise data warehouse methodology developed by Dan Linstedt that uses Hubs, Links, and Satellites to build scalable, auditable, and historically accurate analytical architectures.
When Dimensional Modeling Reaches Its Limits
Ralph Kimball’s dimensional modeling (Star Schema) dominates enterprise analytics for good reason: it is intuitive, fast, and well-suited to the reporting patterns of most business units. But dimensional modeling makes an assumption that breaks down in large, complex organizations: that the analytical team can reach upfront consensus on the schema. Building a Star Schema requires defining the grain of every Fact table, the attributes of every Dimension, and the relationships between them before data begins flowing.
In a small organization with a handful of data sources and a clear analytical mandate, this upfront design is achievable. In a Fortune 100 company integrating forty-seven source systems representing seven acquired businesses, each using different customer identifiers, different product taxonomies, and different transactional semantics, reaching schema consensus before ingesting data is practically impossible. The dimensional modeling project stalls in endless requirements workshops while business units wait months for analytical access to their data.
Dan Linstedt, working at the U.S. Department of Defense in the late 1990s and developing his methodology through the 2000s, encountered exactly this problem. His organization needed to integrate data from dozens of legacy systems with incompatible schemas while maintaining a complete, auditable history of every data change for regulatory purposes. Dimensional modeling could not accommodate this combination of requirements: schema flexibility, historical completeness, and parallel multi-source integration. Data Vault was his solution.
The Three Core Entity Types
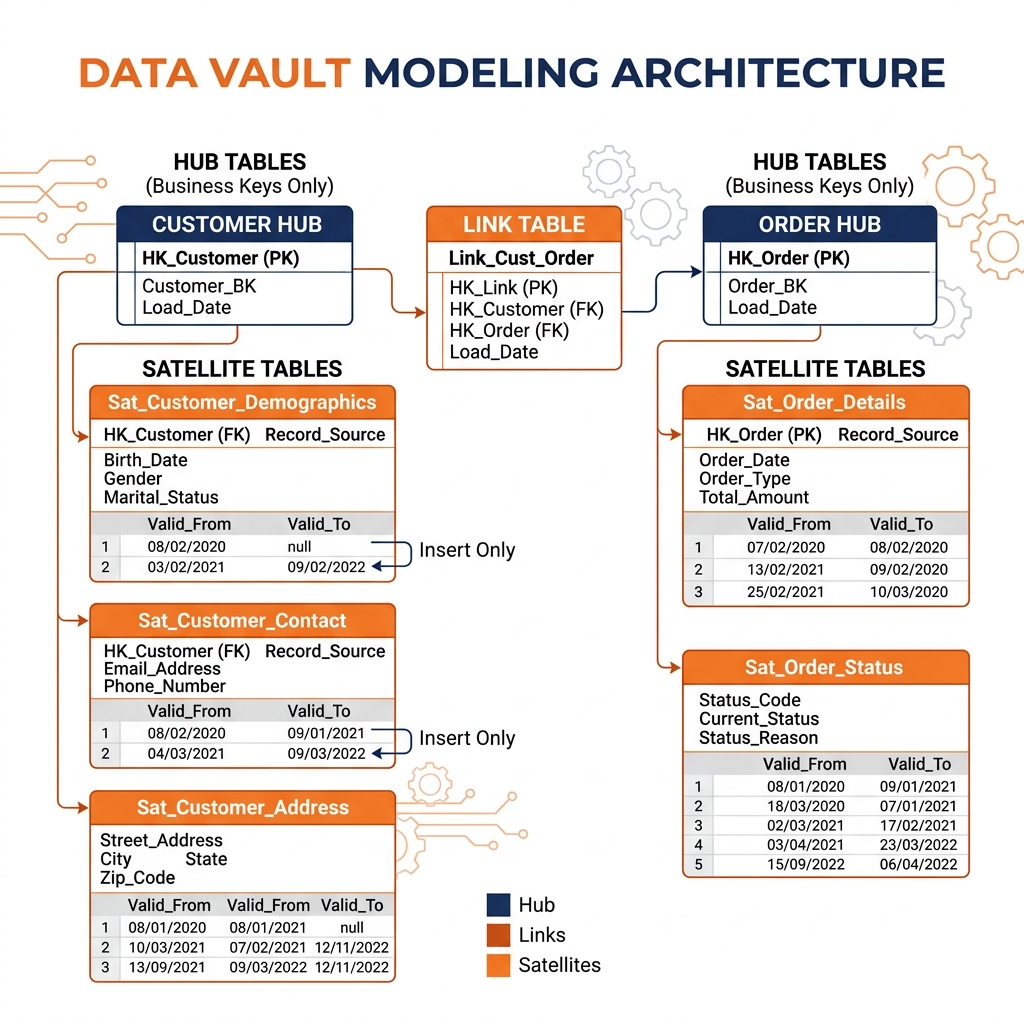
Data Vault organizes all data around three entity types: Hubs, Links, and Satellites. Each type has a strictly defined purpose and structure that together provide the flexibility, scalability, and auditability that make Data Vault suited for complex enterprise environments.
Hubs: The Business Keys
A Hub represents a core business concept and stores only its unique business key, nothing more. The Hub for Customer stores the customer_business_key (the identifier used by the source system to uniquely identify a customer), a system-generated hash key, the timestamp when the record was first loaded, and the identifier of the source system that introduced it.
This extreme minimalism is intentional. By storing only the business key, the Hub becomes the permanent anchor for the concept of “Customer” regardless of how many source systems define or describe a customer. The Salesforce CRM might identify customers by email address. The ERP might use an account number. The billing system might use a sequential integer ID. All three are loaded as business keys into the Customer Hub, reconciled through a separate reference table. The Hub itself does not care about these differences; it simply records that a specific identifier from a specific system represents a Customer.
Hubs are insert-only. Once a business key is loaded, the Hub row is never updated. Historical accuracy is absolute: the Hub records precisely when each customer identity first appeared in the enterprise data ecosystem.
Links: The Relationships
Links represent associations between Hubs. A Link connecting Customer Hub to Order Hub records that a specific customer placed a specific order. A Link connecting Order Hub to Product Hub records that a specific order contained a specific product. Links store the hash keys of the associated Hubs, a load timestamp, and a source system identifier.
Like Hubs, Links are insert-only. Relationships are recorded as they are first discovered and never modified. If a customer relationship to an order is deleted in the source system (perhaps due to a data correction), Data Vault records this as a new Link entry with an end-date Satellite rather than modifying the original Link row.
Links are extraordinarily flexible. Because Links are separate tables rather than embedded foreign keys in the Fact table, new relationships between existing entities can be added to the Data Vault simply by creating a new Link table, without modifying any existing Hub or Satellite. This is a profound advantage in enterprises where new analytical requirements emerge continuously.
Satellites: The Context and History
Satellites store all descriptive attributes for Hubs and Links, and they provide the complete historical record that is Data Vault’s most distinctive capability. A Customer Satellite stores first_name, last_name, email_address, city, state, phone_number, along with the Hub’s hash key, a load timestamp, and an end-date timestamp.
Satellites are also insert-only. When a customer’s email address changes, the existing Satellite row is not updated. A new Satellite row is inserted with the new email address and the current load timestamp. The old row’s end-date is set to the current timestamp, marking it as the historical record for the period before the change. This insert-only mechanism provides a complete, tamper-evident history of every attribute change across every entity in the enterprise.
Multiple Satellites can attach to a single Hub, each fed by a different source system. The Customer Hub might have a Customer_CRM_Satellite fed by Salesforce and a Customer_ERP_Satellite fed by SAP, each storing the attributes their respective source systems provide. This multi-source Satellite architecture allows Data Vault to integrate data from multiple systems without requiring them to share a common schema.
The Business Vault and Reporting
Raw Data Vault (Hub, Link, Satellite) is designed for integration, not for reporting. Writing a query directly against the raw Data Vault to calculate “monthly revenue by customer segment” would require joining multiple Hubs through Links and then joining multiple Satellites for each, producing complex SQL that is not practical for business analysts.
The Business Vault layer sits above the raw Data Vault and applies business rules and transformations to produce computed attributes and derived metrics. Bridge tables in the Business Vault pre-compute common multi-join paths, creating reusable structures that reduce reporting query complexity. Point-in-Time (PIT) tables construct consistent snapshots of Hub attributes as of specific dates, enabling historical analysis without requiring date-range joins against every Satellite.
Above the Business Vault, a reporting layer typically implements dimensional models (Star Schemas) or flat denormalized tables optimized for BI tool consumption. The Data Vault serves as the integration and historical storage layer, and the reporting models are generated from it. This separation means that multiple different reporting schemas can be derived from the same Data Vault without modifying the underlying integration layer.
Data Vault on Apache Iceberg
Apache Iceberg is an ideal physical storage substrate for Data Vault tables. The insert-only nature of Hubs, Links, and Satellites aligns perfectly with Iceberg’s append-optimized write path. Iceberg’s partition pruning and file-level statistics allow queries against Satellite tables to efficiently locate rows within specific date ranges without scanning the entire history.
Iceberg’s schema evolution capabilities allow new columns to be added to Satellite tables as source systems evolve, without requiring expensive full table rewrites. When a new attribute is added to the CRM system and needs to flow into the Customer CRM Satellite, the engineer adds the column to the Iceberg table schema with a single metadata operation and begins including it in new inserts. Historical rows that predate the new column retain null values for it, which is consistent with Data Vault’s principle that history is never modified.
Dremio’s Semantic Layer is well-suited to virtualizing the complex join patterns of the Business Vault. Data engineers build Virtual Datasets in Dremio that encapsulate the multi-Hub, multi-Satellite join logic and expose simple, business-friendly views to analysts. Data Reflections pre-compute the most expensive Business Vault joins, delivering BI-grade performance without requiring the engineering overhead of physical materialization pipelines.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.