Data Fabric
A comprehensive guide to Data Fabric, the unified architecture that combines data integration, governance, and intelligent automation to connect distributed enterprise data sources into a coherent analytical fabric.
The Fragmentation Problem at Enterprise Scale
Modern enterprises operate in a state of perpetual data fragmentation. Over decades of organic growth, technology acquisitions, and departmental silos, organizations accumulate an extraordinary number of disparate data stores. A typical Fortune 500 company might operate dozens of on-premises relational databases, multiple cloud-based SaaS platforms, several proprietary data warehouses, streaming event buses, and object storage lakes spread across three different cloud providers. This heterogeneous landscape is not the result of poor planning; it reflects the reality that different business units adopted the best available technology at the time of their specific need.
The consequence of this fragmentation is that data, the organization’s most valuable asset, becomes effectively inaccessible at scale. When a data science team needs to build a customer churn model, they cannot query across all these systems simultaneously. Each system speaks its own query language, uses its own authentication protocol, and enforces its own schema conventions. The engineering effort required to manually build point-to-point connectors between every source and the central data platform grows at a combinatorial rate. With twenty source systems, the potential number of integration pathways is enormous, and each pathway must be maintained individually as the source systems evolve.
This integration complexity creates a second-order failure: inconsistent metadata. When the Marketing team refers to “Customer ID,” they might mean the Salesforce contact identifier. When the Finance team refers to “Customer ID,” they might mean the ERP account number. When these identifiers are never reconciled into a consistent enterprise definition, analytical models produce conflicting outputs. Leadership loses trust in the data platform, and data scientists spend the majority of their time on manual data wrangling rather than building models.
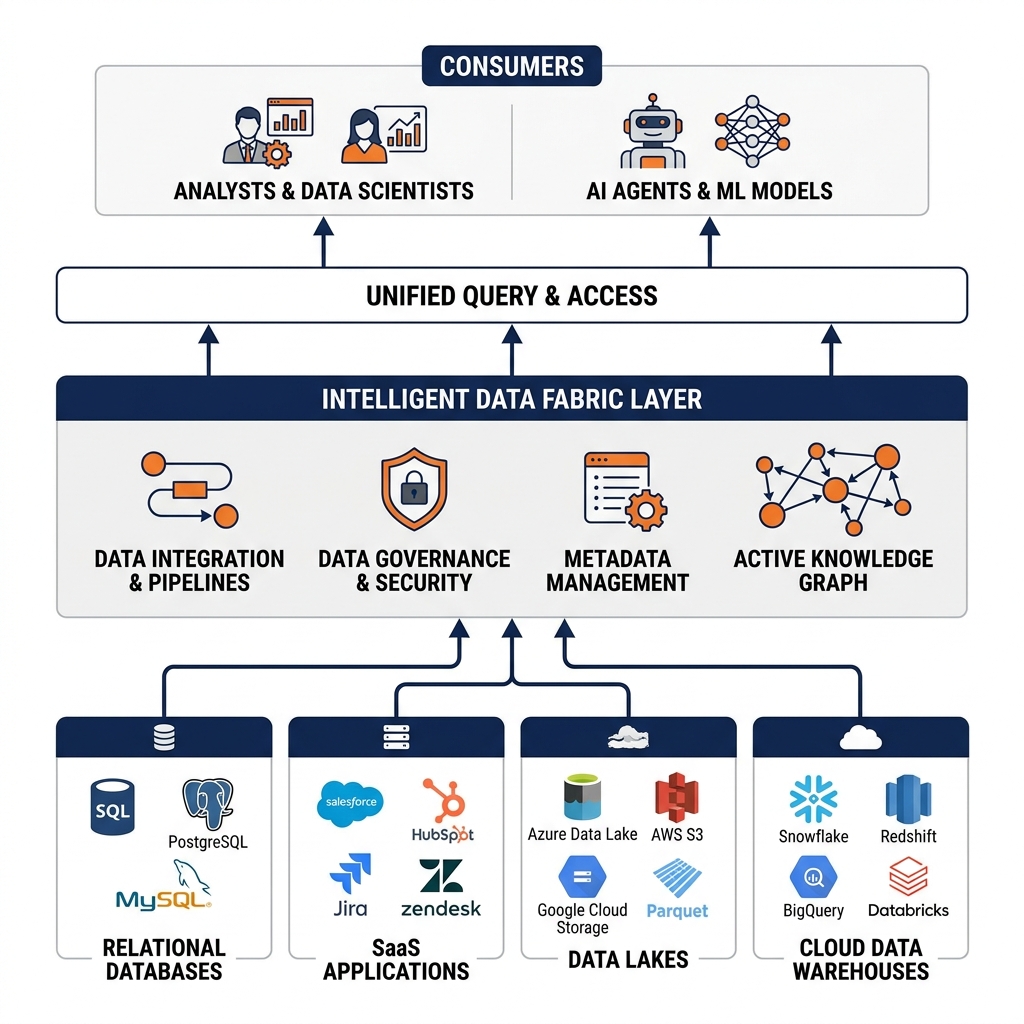
The Data Fabric paradigm was developed to resolve this fundamental tension between the operational necessity of heterogeneous data stores and the analytical necessity of unified, coherent data access. Unlike the Data Mesh, which is primarily an organizational paradigm, the Data Fabric is fundamentally a technology-driven architecture. It leverages automated metadata management, active knowledge graphs, and intelligent integration pipelines to weave disparate data sources into a single, cohesive analytical fabric without requiring every system to be physically migrated into a central repository.
What is a Data Fabric?
A Data Fabric is an integrated data management architecture designed to provide consistent, unified access to distributed data across heterogeneous environments. The defining characteristic of a Data Fabric is its active, automated approach to metadata management. Rather than relying on data engineers to manually document every data source, schema, and data quality rule, the Data Fabric continuously discovers, profiles, and catalogs metadata from all connected data sources automatically.
This active knowledge graph sits at the center of the fabric. As source systems evolve, the knowledge graph updates itself, tracking schema changes, identifying new datasets, and flagging quality deviations. This continuous awareness allows the Data Fabric to intelligently route queries to the optimal data source, reconcile semantically equivalent entities across different systems, and recommend pre-built integration patterns to data engineers.
The Data Fabric is not a single product but rather a set of integrated architectural capabilities: unified data discovery and cataloging, automated data integration and orchestration, self-service data preparation, active data governance and policy enforcement, and intelligent query federation. Together, these capabilities provide a comprehensive layer that spans the entire heterogeneous data landscape, making the complexity of the underlying infrastructure transparent to the end-user.
The Knowledge Graph and Active Metadata
The core engine of the Data Fabric is the active knowledge graph. A knowledge graph is a structured representation of organizational knowledge that explicitly models the relationships between different data entities, concepts, and processes. Unlike a passive data catalog (which merely lists what datasets exist), the knowledge graph in a Data Fabric actively maps the semantic relationships between entities across systems.
For example, the knowledge graph might determine that the cust_id field in the CRM database is semantically equivalent to the account_number field in the ERP system based on statistical analysis of the data distributions and the relationship patterns between these identifiers and common attributes like email addresses and phone numbers. Once these semantic links are established, queries that reference “Customer” can be intelligently resolved across both systems without requiring the analyst to know which specific field name to use in each source.
Active metadata is the process by which the fabric continuously enriches this knowledge graph. When a new Kafka stream is connected to the fabric, it immediately begins profiling the data: calculating column-level statistics, detecting data types, identifying potential primary keys, and flagging potential sensitive data requiring governance controls. This automated profiling dramatically reduces the manual cataloging burden and ensures the knowledge graph remains current as the data landscape evolves.
Federated Query and Virtual Data Integration
One of the most powerful capabilities of the Data Fabric is its ability to execute federated queries across heterogeneous data sources without physically moving or duplicating the data. This virtual integration approach directly addresses the cost and latency overhead of traditional ETL pipelines.
In a traditional integration architecture, accessing data from five different source systems requires five separate ETL pipelines to extract the data, transform it to a common schema, and load it into a central warehouse. These pipelines consume significant compute resources, introduce latency (often measured in hours for batch jobs), and require constant maintenance as source schemas evolve. Each pipeline also creates a physical copy of the data, doubling storage costs and creating the risk of data drift between the copy and the original.
A Data Fabric’s federated query engine eliminates this overhead. When an analyst issues a SQL query, the fabric’s query optimizer consults the knowledge graph to determine which source systems contain the required entities. It then generates system-specific sub-queries for each source (translating SQL to the native query language of each system if required), executes the sub-queries in parallel, and merges the results into a coherent unified dataset returned to the analyst. The data never moves; it is accessed in place. This approach reduces data duplication, eliminates the latency of ETL batch jobs, and ensures the analyst always receives the freshest possible data directly from the source.
Automated Governance and Policy Enforcement
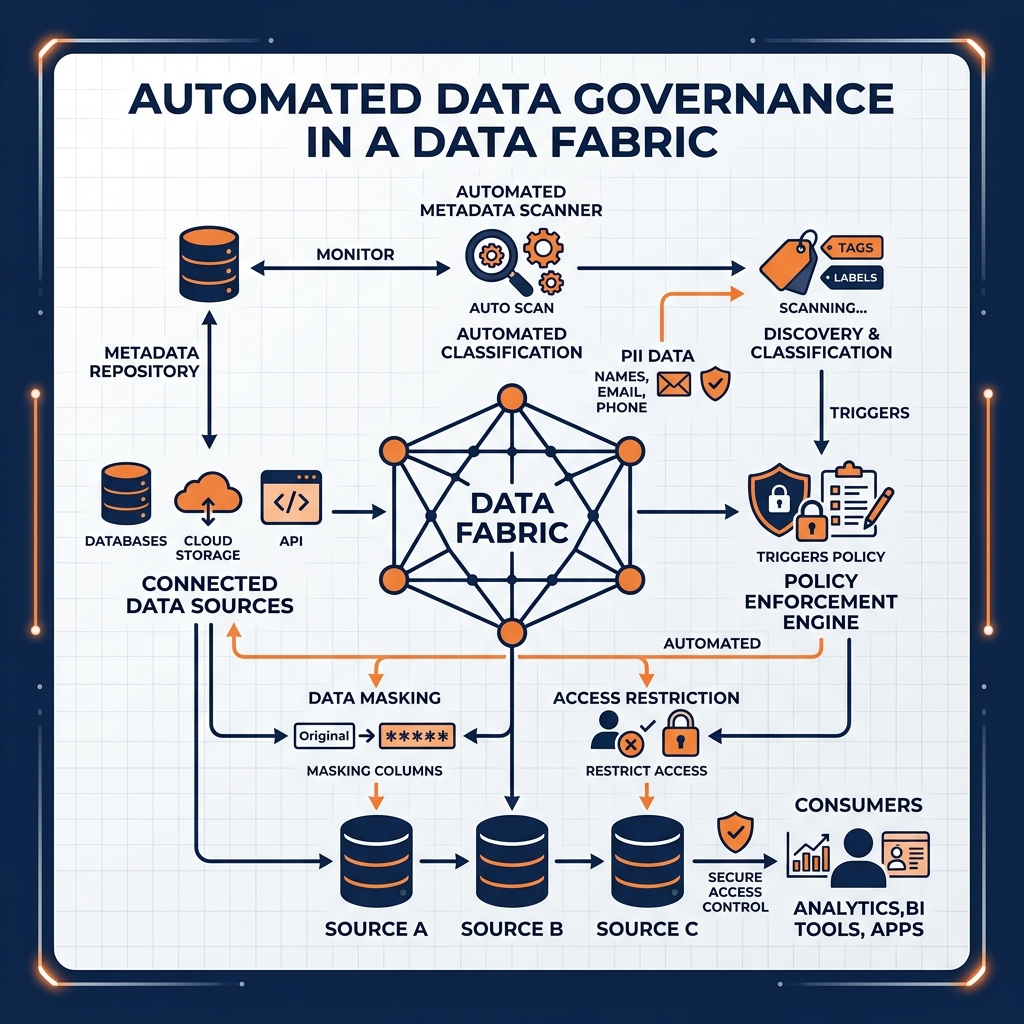
Data governance in a traditional, manually managed environment is inherently reactive. Security policies are documented in spreadsheets, access control is managed through ticket-based approval processes, and compliance audits are conducted quarterly by reviewing static reports. This reactive posture leaves organizations perpetually exposed to data breaches and compliance violations in the gaps between audits.
The Data Fabric transforms governance into a proactive, automated process. Because the active knowledge graph continuously profiles all connected data sources, it can automatically classify sensitive data as it is discovered. When a new column containing values matching the pattern of Social Security Numbers is detected in a newly connected data source, the fabric can automatically apply the organization’s PII governance policy, masking the column and requiring elevated access approval before any user can query the raw values.
Policy enforcement is computational and continuous rather than manual and periodic. Integration with platforms like Apache Polaris allows the fabric to propagate RBAC policies across all connected sources from a single control plane. When a user’s permissions are revoked in the central catalog, that revocation is immediately enforced across every data source in the fabric simultaneously, completely eliminating the dangerous lag that exists in manually synchronized access control systems.
The Data Fabric and the Open Lakehouse
While a Data Fabric can span any heterogeneous data environment, the open Data Lakehouse powered by Apache Iceberg serves as its most powerful anchor. The Iceberg Lakehouse provides the Data Fabric with a high-performance, governed, and open central hub where the most critical enterprise datasets are stored and managed with full ACID compliance.
When data from legacy on-premises databases and SaaS platforms is integrated into the fabric, the highest-value, most frequently queried datasets can be selectively ingested into the Iceberg Lakehouse. Storing these datasets as Iceberg tables unlocks Time Travel (enabling auditors to query the historical state of the data), schema evolution (allowing the physical table structure to change without breaking downstream consumers), and interoperability (allowing any compute engine to read the data without vendor lock-in).
Dremio as the Data Fabric Intelligence Layer
Dremio’s architecture makes it a natural intelligence layer for the Data Fabric. Through its unified Semantic Layer, Dremio can connect directly to dozens of heterogeneous data sources (relational databases, object storage buckets, data warehouses) and present them as unified virtual datasets. This eliminates the need for physical data movement and serves as the primary federated query engine of the fabric.
The Dremio Semantic Layer acts as the human-facing expression of the knowledge graph. The governed virtual datasets built in Dremio are the operationalization of the semantic reconciliation performed by the fabric’s active metadata engine. When the knowledge graph determines that cust_id and account_number are semantically equivalent, a Dremio virtual dataset can codify that equivalence into a permanent, reusable join, making the reconciled “Customer” entity accessible to every analyst and AI agent across the organization through a single, governed SQL endpoint.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.