Data Annotation
A guide to data annotation, the labor-intensive process of manually labeling raw unstructured data (images, text, audio) so that supervised machine learning models can learn to identify patterns.
Teaching by Example
Machine learning models, particularly deep neural networks, are incredibly powerful pattern-recognition engines, but they are not inherently intelligent. If you show a brand-new computer vision model a photograph of a cat, it only sees a meaningless grid of RGB pixel values. It has no concept of what a “cat” is.
To teach the model, you must provide it with examples. You must show it 10,000 pictures of cats, and crucially, you must explicitly tell the model: “This picture contains a cat.”
Data annotation (or data labeling) is the process of attaching these ground-truth metadata tags to raw, unstructured data. In supervised machine learning, the model looks at the raw data (the input), looks at the human-provided annotation (the target output), and mathematically adjusts its internal parameters to learn the mapping between the two.
Types of Data Annotation
The type of annotation required depends entirely on the machine learning task:
Image Annotation: Used for computer vision. Annotators draw “Bounding Boxes” around specific objects (e.g., drawing a box around every pedestrian in a dashcam video for self-driving cars) or perform “Semantic Segmentation” (coloring every single pixel in an image to belong to a specific category, like ‘road’, ‘sky’, or ‘vehicle’).
Text Annotation:
Used for Natural Language Processing (NLP). Annotators might highlight specific words in a medical document and tag them as Symptom or Medication (Named Entity Recognition). Or they might read a restaurant review and tag the entire paragraph as Positive Sentiment or Negative Sentiment.
Audio Annotation: Used for speech recognition. Annotators listen to a raw audio file of a person speaking and transcribe the exact text word-for-word, including tags for background noise or speaker changes.
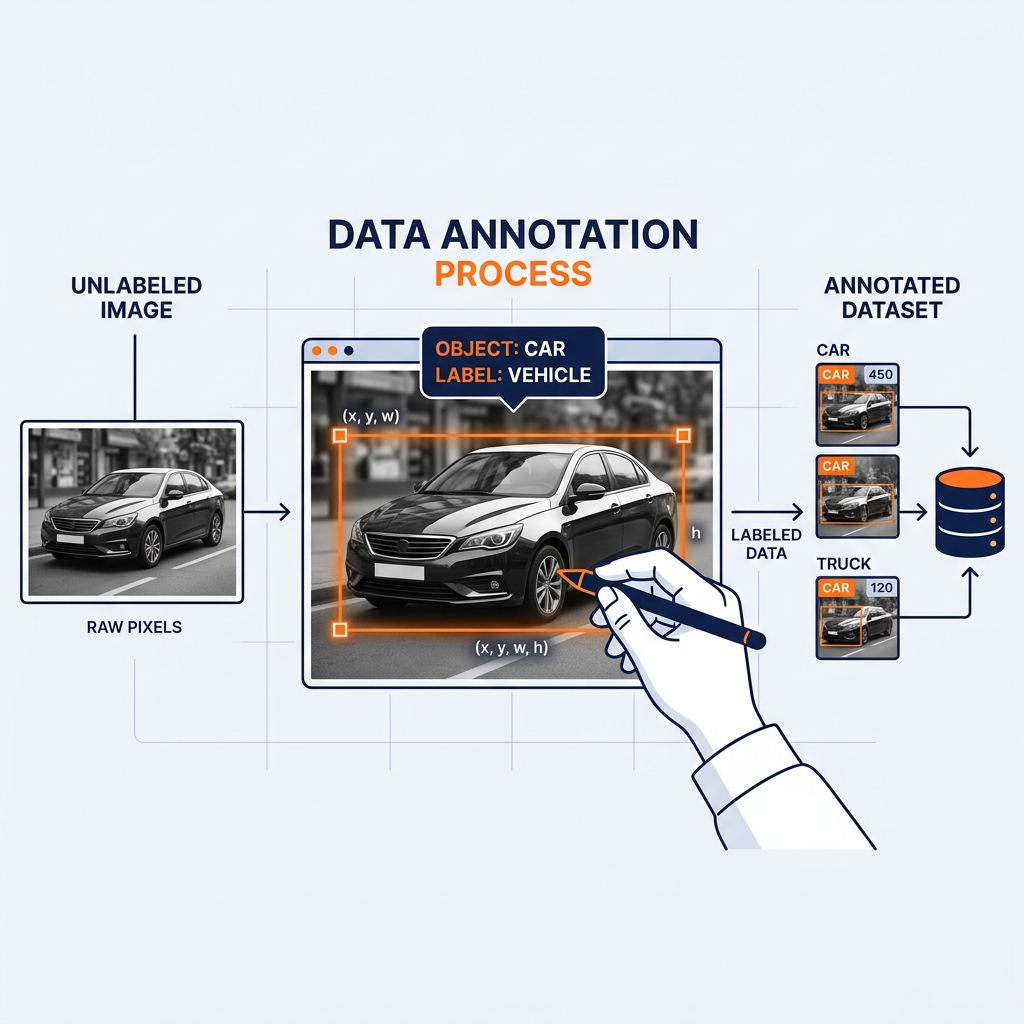
The Engineering Challenge
Data annotation is notoriously the most expensive, slow, and labor-intensive bottleneck in the entire AI lifecycle. It often requires armies of human workers (often managed through platforms like Scale AI or Amazon SageMaker Ground Truth) to click and drag boxes on screens for thousands of hours.
Data engineering teams must build robust pipelines to support this workflow. Raw data must be extracted from the lakehouse, securely transmitted to the annotation platform (often stripping out PII for privacy compliance), and then the returned JSON annotation files must be joined back to the raw image data to create the final “Training Dataset.”
To reduce costs, teams are increasingly using “Active Learning,” where a partially trained ML model attempts to pre-annotate the data, and human workers only step in to correct the model when it is uncertain.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.