Agentic Analytics
The next evolution of enterprise data, where autonomous AI agents leverage semantic layers and the data lakehouse to reason, plan, and execute complex analytical workflows without human intervention.
The Evolution Beyond Predictive AI
The trajectory of enterprise analytics is defined by a continuous drive toward automation and higher-order intelligence. For decades, the industry operated primarily within the realm of descriptive analytics, focusing on historical reporting to answer the question of what happened. This eventually matured into diagnostic analytics, providing deeper drill-downs to determine why specific events occurred. As computational power increased and big data architectures stabilized, organizations transitioned toward predictive analytics, utilizing statistical machine learning models to forecast what will happen next. Finally, prescriptive analytics emerged, attempting to recommend specific actions based on those predictions.
However, throughout this entire evolutionary spectrum, the human analyst remained the central orchestrator. Predictive models and prescriptive engines are fundamentally passive systems. They output a probability score, a classification label, or a recommended dashboard visualization, but they require a human operator to interpret the output, synthesize it with external business context, formulate a strategic plan, and ultimately execute the necessary operational changes.
Agentic Analytics represents a paradigm shift that fundamentally removes the human from the center of this execution loop. Rather than relying on passive models that simply process inputs and return static outputs, Agentic Analytics employs autonomous AI agents powered by Large Language Models (LLMs). These agents possess the architectural capability to reason about complex business objectives, dynamically construct multi-step analytical plans, interface directly with enterprise data platforms to retrieve necessary context, and execute actions across operational systems to resolve the original objective.
The distinction between traditional machine learning and Agentic Analytics is stark. Traditional machine learning relies on highly specialized algorithms trained on rigid datasets to solve narrow, specific problems, such as detecting credit card fraud or predicting customer churn. These models lack generalized reasoning capabilities and cannot adapt to novel scenarios outside their strict training parameters. Agentic Analytics, conversely, leverages the generalized reasoning engine of an LLM. An agent can be presented with an entirely novel, open-ended prompt, such as investigating a sudden drop in quarterly supply chain efficiency. The agent can independently decide to query an Apache Iceberg table to review logistics telemetry, execute a Python script to perform statistical anomaly detection, query a CRM system to check for related customer complaints, synthesize the findings into a cohesive narrative, and automatically draft a remediation report for the supply chain director. This shift from passive prediction to autonomous, reasoned execution marks the beginning of the Agentic era in data engineering.
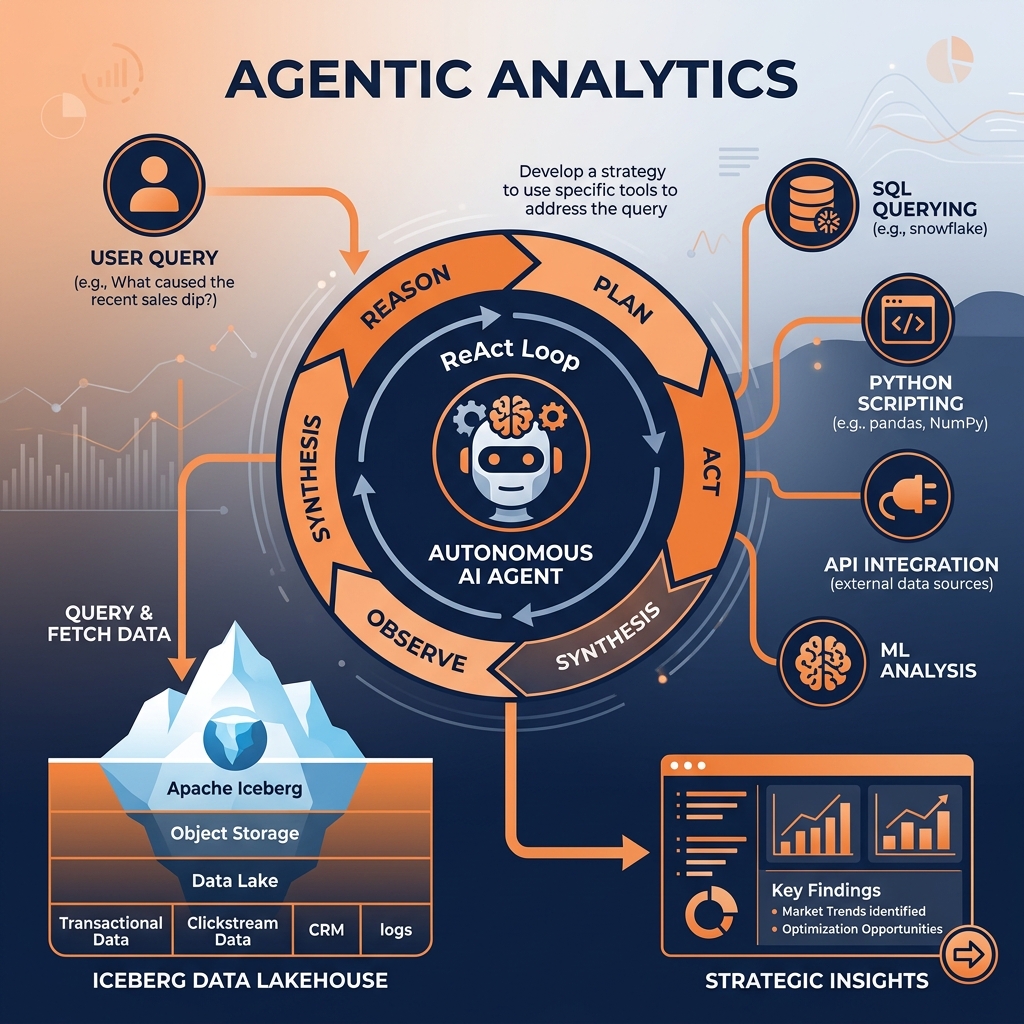
To construct a robust architecture capable of supporting Agentic Analytics, engineers must deeply understand the core functional principles that separate an autonomous agent from a standard chatbot or a traditional predictive model. An agent operates through a continuous cognitive loop, often referred to as the ReAct (Reasoning and Acting) framework. This framework consists of four primary components: memory, planning, tool use, and execution.
Memory and State Management
Standard LLMs are stateless by design. When a user sends a prompt, the model processes the tokens and generates a response, but it retains no inherent memory of the interaction once the session ends. Autonomous agents, however, must execute complex workflows that span hours or days, requiring persistent state management.
Agentic architectures implement memory in two distinct phases: short-term memory and long-term memory. Short-term memory is typically managed within the LLM’s active context window, allowing the agent to track the immediate sequence of steps it is currently executing. Long-term memory involves the persistent storage and retrieval of historical context. Agents leverage external databases, often vector databases or optimized graph databases, to store previous findings, successful execution paths, and historical organizational context. When an agent encounters a new problem, it first queries its long-term memory to determine if it has solved a similar problem in the past, drastically improving its efficiency and preventing hallucinatory regressions.
Dynamic Planning
When a traditional software application encounters a task, it follows a rigid, hard-coded execution path defined by a human developer. An autonomous agent dynamically generates its own execution path. When presented with a high-level business objective, the agent’s planning module decomposes the complex objective into a sequence of manageable, atomic tasks.
Critically, this planning process is not static. Agentic architectures incorporate self-reflection and error correction mechanisms. If an agent executes step two of its plan and the resulting data query returns an unexpected error (perhaps due to a missing column in a table), the agent does not simply crash and throw an exception to the user. Instead, it observes the error, reasons about the failure, dynamically formulates a new SQL query to inspect the table schema, adjusts its overarching plan to account for the actual schema, and resumes execution. This dynamic, self-healing planning capability is the defining characteristic of true autonomy.
Tool Use and Orchestration
An LLM isolated in a vacuum is incapable of interacting with the enterprise. To effect change, agents must be granted access to external tools. In an Agentic Analytics architecture, tools are typically exposed as strictly typed APIs or SQL interfaces that the agent is trained to utilize.
An agent’s toolbelt might include the ability to execute SQL queries against a Dremio semantic layer, run Python code in a secure sandboxed environment, trigger external CI/CD pipelines, or interact with third-party SaaS applications via REST APIs. The agent uses its reasoning engine to determine exactly which tool is required to fulfill the current step of its dynamic plan. If the agent needs to forecast next quarter’s revenue, it will intelligently decide to query the historical revenue data using SQL, pass that data into a Python forecasting library via the code execution tool, and output the final result, seamlessly orchestrating multiple discrete technologies without human intervention.
The RAG Pattern and LLM Orchestration
The foundational pattern that enables Agentic Analytics to interface with enterprise data is Retrieval-Augmented Generation (RAG). While LLMs possess vast amounts of generalized knowledge absorbed during their initial training phases, they are fundamentally ignorant of an organization’s specific, proprietary data. Furthermore, retraining or fine-tuning an LLM every time a new sales transaction occurs is computationally prohibitive and architecturally unscalable. RAG solves this by decoupling the reasoning engine from the underlying data storage.
The Retrieval-Augmented Generation Workflow
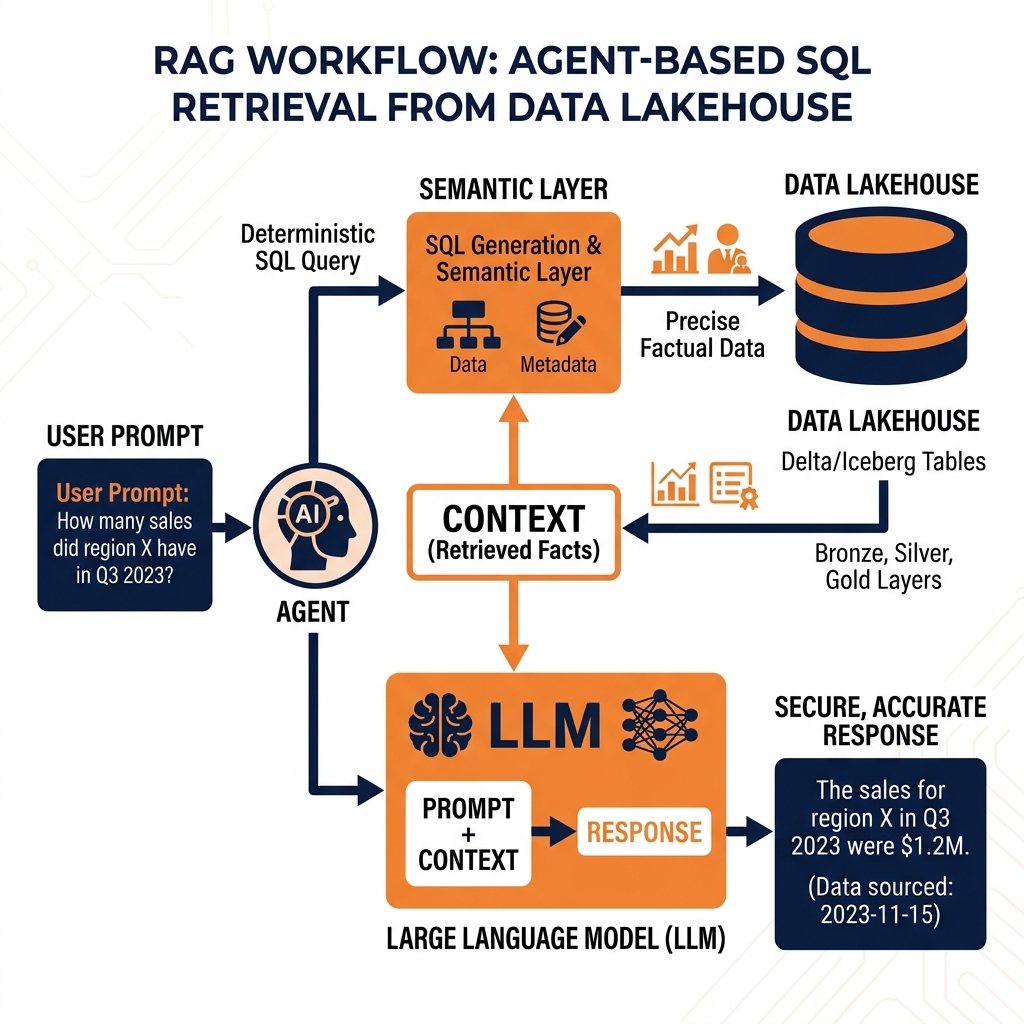
In a standard RAG workflow, the autonomous agent acts as the reasoning orchestrator. When the agent determines it needs specific organizational context to fulfill an objective, it formulates a retrieval query. This query is directed at the enterprise data architecture, which acts as the retrieval system. The data platform executes the query, extracts the relevant historical data, and returns it to the agent. The agent then injects this retrieved data directly into the active prompt context of the LLM.
By augmenting the prompt with ground-truth enterprise data, the LLM can generate highly accurate, highly contextualized responses without relying on its static training weights. This entirely eliminates the risk of the model hallucinating incorrect business metrics, as its reasoning is strictly bounded by the factual data retrieved from the lakehouse.
Vector Databases vs. Structural SQL
Early implementations of RAG relied almost exclusively on vector databases. In this paradigm, enterprise documents (PDFs, wikis, unstructured text) are converted into mathematical embeddings (vectors) and stored in a specialized database. When the agent needs information, it performs a semantic similarity search across the vectors to retrieve the most relevant text chunks. While vector databases are exceptional for querying unstructured text, they are fundamentally inadequate for Agentic Analytics workflows that require absolute numerical precision.
If a financial agent is tasked with determining the exact total revenue for Q3 2025, executing a semantic search against a vector database is dangerous and unreliable. The agent does not need a document that sounds semantically similar to “Q3 revenue”; it needs the exact, aggregated numerical integer resulting from a mathematical SUM() operation across millions of individual transaction records.
Consequently, mature Agentic Analytics architectures rely heavily on structural SQL databases and open data lakehouses for their primary retrieval mechanism. Instead of vectorizing financial ledgers, the agent is trained to dynamically generate and execute complex SQL queries against a semantic layer. The data platform executes the massive analytical aggregations deterministically and returns the precise numerical results to the agent. This fusion of deterministic SQL retrieval with probabilistic LLM reasoning is the hallmark of enterprise-grade Agentic Analytics.
Autonomous AI agents are incredibly powerful, but they are entirely dependent on the quality, accessibility, and structure of the underlying data architecture. Deploying highly intelligent agents against legacy data swamps or closed, proprietary data warehouses inevitably results in failure. The Open Data Lakehouse, specifically powered by Apache Iceberg, is the strict architectural prerequisite for successful Agentic Analytics.
The Failure of Legacy Architectures
Legacy data swamps lack governance, structure, and transactional consistency. If an AI agent attempts to reason over a data swamp, it will inevitably ingest corrupted files, orphaned partitions, and conflicting schemas. Because the agent relies on this data as the absolute ground truth for its decision-making loop, ingesting corrupted data will cause the agent to hallucinate wildly and execute destructive, incorrect actions across the enterprise.
Conversely, legacy data warehouses offer pristine data quality but fail agents through lock-in and rigidity. Proprietary warehouses often restrict programmatic access via closed APIs and charge massive egress fees to extract data into the external compute environments where LLM orchestration frameworks (like LangChain or AutoGen) typically operate. Furthermore, traditional warehouses struggle to store the massive volumes of unstructured text and multimodal data (images, audio) that modern AI agents require to build comprehensive contextual awareness.
The Iceberg Lakehouse Advantage
The Apache Iceberg data lakehouse perfectly satisfies the rigorous demands of Agentic Analytics by combining the infinite scale and format flexibility of object storage with strict, ACID-compliant database guarantees.
Iceberg tables are built on open standard formats (Parquet, ORC). This means AI agents can interact directly with the underlying storage layer using whatever compute framework or programming language best suits their current task, completely bypassing proprietary vendor lock-in.
Most importantly, Iceberg provides the critical feature of Time Travel. Autonomous agents require absolute reproducibility to validate their reasoning loops and debug complex decision trees. If an agent formulates a plan based on a table that is constantly receiving streaming updates, the data will mutate out from under the agent mid-execution, causing the agent’s logic to fail. Because Iceberg uses immutable snapshots, an AI agent can execute a query pinned to a specific snapshot ID, ensuring that its entire multi-step analytical workflow operates against a perfectly frozen, consistent view of the enterprise data, regardless of ongoing ingestion pipelines.
Dremio as the Agentic Engine
While the Apache Iceberg lakehouse provides the physical foundation for Agentic Analytics, the raw physical schema of a massive enterprise data ecosystem is often too complex for an LLM to navigate autonomously. An AI agent is likely to fail if it is forced to write complex, 20-way SQL joins across cryptically named physical Parquet files just to determine a simple metric like “Net Churn.” To operate effectively, agents require a logical translation layer. Dremio serves as the critical engine that bridges this gap, providing the Semantic Layer necessary for agents to succeed.
The Agentic Semantic Layer
Dremio’s Semantic Layer abstracts away the immense complexity of the physical data lakehouse. Data engineers utilize Dremio to construct virtual datasets that pre-join complex physical tables, rename cryptic columns into natural business terminology, and embed standardized organizational logic (e.g., standardizing the exact formula for “Net Churn”).
When an autonomous AI agent needs to retrieve context, it does not query the raw Iceberg files; it queries the Dremio Semantic Layer via standard SQL. By interacting with these clean, business-friendly virtual datasets, the agent’s success rate in generating accurate SQL syntax skyrockets. The agent no longer has to guess how to join the cust_id_x7 column with the trx_fk_9 column; it simply executes SELECT * FROM business.active_customers, and Dremio handles the complex physical translation engine under the hood. The Semantic Layer effectively serves as an API that translates raw technical infrastructure into a language the AI agent can naturally reason about.
Accelerating the Agentic Loop
Autonomous agents operate in continuous loops of reasoning and acting. If every data retrieval action takes several minutes to execute because it requires a full scan of a massive object storage bucket, the agentic workflow will become unacceptably slow. In interactive scenarios, such as an agent assisting a human executive in real-time during a board meeting, these massive latencies are fatal to adoption.
Dremio solves this latency requirement through Data Reflections. When data engineers identify the core virtual datasets that the AI agents frequently access, they can enable Data Reflections on those views. Dremio will automatically pre-compute, optimize, and store the results in the lakehouse. When the AI agent subsequently queries the Semantic Layer, the Dremio optimizer intercepts the request and instantly routes it to the pre-computed Reflection. The agent receives sub-second query responses, allowing its autonomous reasoning loops to cycle rapidly, processing complex workflows in seconds rather than hours. This combination of semantic abstraction and blazing-fast acceleration makes Dremio the ultimate execution engine for Agentic Analytics.
Security, Governance, and the Future of AI
Deploying autonomous systems that have the capability to independently query, analyze, and act upon enterprise data introduces unprecedented security and governance challenges. In traditional environments, data access is strictly gated by human identities and manual approval workflows. In an Agentic Analytics ecosystem, agents execute thousands of operations autonomously, requiring security architectures to be explicitly designed for machine-to-machine interactions.
Enforcing Role-Based Access Control
The most critical governance requirement for Agentic Analytics is ensuring that an AI agent cannot access data outside of its strictly defined purview. If an agent tasked with optimizing supply chain logistics accidentally retrieves unmasked PII (Personally Identifiable Information) from a human resources table and injects it into a public LLM prompt, the organization faces a catastrophic compliance violation.
Security cannot be enforced at the application level where the LLM resides, as autonomous agents can easily bypass application constraints through dynamic code generation. Instead, security must be enforced universally at the catalog and compute layers. By utilizing an open catalog like Apache Polaris in conjunction with the Dremio execution engine, organizations establish a unified control plane.
Data engineers configure strict Role-Based Access Control (RBAC) policies within Dremio and Polaris, assigning the AI agent a specific service account identity. When the agent attempts to execute a query, Dremio authenticates the service account and evaluates the RBAC policies in real-time. If the agent attempts to query a restricted financial table, Dremio decisively blocks the execution at the engine level, completely neutralizing the threat. Furthermore, Dremio can enforce column-level masking and row-level security, ensuring that even if an agent has access to a table, it only receives redacted or aggregated data appropriate for its clearance level.
Conclusion
Agentic Analytics represents the final transition from passive data consumption to active, autonomous data intelligence. By decoupling the reasoning engine of Large Language Models from the proprietary constraints of legacy data warehouses, organizations can unleash AI agents to dynamically solve complex business objectives. However, this autonomous future is entirely dependent on the structural integrity of the underlying data platform. Only an open, governed data lakehouse powered by Apache Iceberg, unified by Apache Polaris, and accelerated by the Dremio Semantic Layer can provide the speed, consistency, and security required to safely usher the enterprise into the Agentic AI era.
Learn More
To dive deeper into these architectures and master the modern data ecosystem, check out the comprehensive books by Alex Merced available in our Books section.